搜索到
72
篇与
的结果
-
 MySQL 慢查询分析工具~pt-query-digest 详解 MySQL 慢查询分析工具~pt-query-digest 详解介绍pt-query-digest 是用于分析 mysql 慢查询的一个工具,它可以分析 binlog、general log、slowlog,也可以通过 SHOW PROCESSLIST 或者通过 tcpdump 抓取的 MySQL 协议数据来进行分析。可以把分析结果输出到文件中,分析过程是先对查询语句的条件进行参数化,然后对参数化以后的查询进行分组统计,统计出各查询的执行时间、次数、占比等,可以借助分析结果找出问题进行优化。安装(yum 安装)yum install perl-DBIyum install perl-DBD-MySQLyum install perl-Time-HiResyum install perl-IO-Socket-SSLwget percona.com/get/pt-query-digestchmod u+x pt-query-digestmv pt-query-digest /usr/bin/语法pt-query-digest [OPTIONS] [FILES] [DSN]--create-review-table 当使用 --review 参数把分析结果输出到表中时,如果没有表就自动创建。--create-history-table 当使用 --history 参数把分析结果输出到表中时,如果没有表就自动创建。--filter 对输入的慢查询按指定的字符串进行匹配过滤后再进行分析。--limit 限制输出结果百分比或数量,默认值是 20, 即将最慢的 20 条语句输出,如果是 50% 则按总响应时间占比从大到小排序,输出到总和达到 50% 位置截止。--host mysql 服务器地址--user mysql 用户名--password mysql 用户密码--history 将分析结果保存到表中,分析结果比较详细,下次再使用 --history 时,如果存在相同的语句,且查询所在的时间区间和历史表中的不同,则会记录到数据表中,可以通过查询同一 CHECKSUM 来比较某类型查询的历史变化。--review 将分析结果保存到表中,这个分析只是对查询条件进行参数化,一个类型的查询一条记录,比较简单。当下次使用 --review 时,如果存在相同的语句分析,就不会记录到数据表中。--output 分析结果输出类型,值可以是 report (标准分析报告)、slowlog (Mysql slow log)、json、json-anon,一般使用 report,以便于阅读。--since 从什么时间开始分析,值为字符串,可以是指定的某个”yyyy-mm-dd [hh:mm:ss]” 格式的时间点,也可以是简单的一个时间值:s (秒)、h (小时)、m (分钟)、d (天),如 12h 就表示从 12 小时前开始统计。--until 截止时间,配合 —since 可以分析一段时间内的慢查询。分析 pt-query-digest 输出结果第一部分:总体统计结果Overall:总共有多少条查询Time range:查询执行的时间范围unique:唯一查询数量,即对查询条件进行参数化以后,总共有多少个不同的查询total:总计 min:最小 max:最大 avg:平均95%:把所有值从小到大排列,位置位于 95% 的那个数,这个数一般最具有参考价值median:中位数,把所有值从小到大排列,位置位于中间那个数该工具执行日志分析的用户时间,系统时间,物理内存占用大小,虚拟内存占用大小340ms user time, 140ms system time, 23.99M rss, 203.11M vsz工具执行时间Current date: Fri Nov 25 02:37:18 2016运行分析工具的主机名Hostname: localhost.localdomain被分析的文件名Files: slow.log语句总数量,唯一的语句数量,QPS,并发数Overall: 2 total, 2 unique, 0.01 QPS, 0.01x concurrency __日志记录的时间范围Time range: 2016-11-22 06:06:18 to 06:11:40属性 总计 最小 最大 平均 95% 标准 中等Attribute total min max avg 95% stddev median============ ======= ======= ======= ======= ======= ======= =======语句执行时间Exec time 3s 640ms 2s 1s 2s 999ms 1s锁占用时间Lock time 1ms 0 1ms 723us 1ms 1ms 723us发送到客户端的行数Rows sent 5 1 4 2.50 4 2.12 2.50select语句扫描行数Rows examine 186.17k 0 186.17k 93.09k 186.17k 131.64k 93.09k查询的字符数Query size 455 15 440 227.50 440 300.52 227.50第二部分:查询分组统计结果Rank:所有语句的排名,默认按查询时间降序排列,通过 --order-by 指定Query ID:语句的 ID,(去掉多余空格和文本字符,计算 hash 值)Response:总的响应时间time:该查询在本次分析中总的时间占比calls:执行次数,即本次分析总共有多少条这种类型的查询语句R/Call:平均每次执行的响应时间V/M:响应时间 Variance-to-mean 的比率Item:查询对象ProfileRank Query ID Response time Calls R/Call V/M Item==== ================== ============= ===== ====== ===== ===============1 0xF9A57DD5A41825CA 2.0529 76.2% 1 2.0529 0.00 SELECT2 0x4194D8F83F4F9365 0.6401 23.8% 1 0.6401 0.00 SELECT wx_member_base第三部分:每一种查询的详细统计结果由下面查询的详细统计结果,最上面的表格列出了执行次数、最大、最小、平均、95% 等各项目的统计。ID:查询的 ID 号,和上图的 Query ID 对应Databases:数据库名Users:各个用户执行的次数(占比)Query_time distribution :查询时间分布,长短体现区间占比,本例中 1s-10s 之间查询数量是 10s 以上的两倍。Tables:查询中涉及到的表Explain:SQL 语句Query 1: 0 QPS, 0x concurrency, ID 0xF9A57DD5A41825CA at byte 802 __This item is included in the report because it matches --limit.Scores: V/M = 0.00Time range: all events occurred at 2016-11-22 06:11:40Attribute pct total min max avg 95% stddev median============ === ======= ======= ======= ======= ======= ======= =======Count 50 1Exec time 76 2s 2s 2s 2s 2s 0 2sLock time 0 0 0 0 0 0 0 0Rows sent 20 1 1 1 1 1 0 1Rows examine 0 0 0 0 0 0 0 0Query size 3 15 15 15 15 15 0 15String:Databases testHosts 192.168.8.1Users mysqlQuery_time distribution1us10us100us1ms10ms100ms1s10s+EXPLAIN /!50100 PARTITIONS/select sleep(2)\G使用例子1.直接分析慢查询文件pt-query-digest slow.log > slow_report.log2.分析最近12小时内的查询pt-query-digest --since=12h slow.log > slow_report2.log3.分析指定时间范围内的查询pt-query-digest slow.log --since '2020-01-07 09:30:00' --until '2020-01-07 10:00:00'> > slow_report3.log3.分析指含有select语句的慢查询pt-query-digest --filter '$event->{fingerprint} =~ m/^select/i' slow.log> slow_report4.log4.分析最近12小时内的查询pt-query-digest --since=12h slow.log > slow_report2.log5.针对某个用户的慢查询pt-query-digest --filter '($event->{user} || "") =~ m/^root/i' slow.log> slow_report5.log6.查询所有所有的全表扫描或full join的慢查询pt-query-digest --filter '(($event->{Full_scan} || "") eq "yes") ||(($event->{Full_join} || "") eq "yes")' slow.log> slow_report6.log7.把查询保存到query_review表pt-query-digest --user=root –password=abc123 --review h=localhost,D=test,t=query_review--create-review-table slow.log8.把查询保存到query_history表pt-query-digest --user=root –password=abc123 --review h=localhost,D=test,t=query_history--create-review-table slow.log_0001pt-query-digest --user=root –password=abc123 --review h=localhost,D=test,t=query_history--create-review-table slow.log_00029.通过tcpdump抓取mysql的tcp协议数据,然后再分析tcpdump -s 65535 -x -nn -q -tttt -i any -c 1000 port 3306 > mysql.tcp.txtpt-query-digest --type tcpdump mysql.tcp.txt> slow_report9.log10.分析binlogmysqlbinlog mysql-bin.000093 > mysql-bin000093.sqlpt-query-digest --type=binlog mysql-bin000093.sql > slow_report10.log11.分析general logpt-query-digest --type=genlog localhost.log > slow_report11.log安装遇到的问题问题:[root@vipstone bin]# pt-query-digest /usr/local/mysql/data/slow.logCan't locate Digest/MD5.pm in @INC (@INC contains: /usr/local/lib64/perl5 /usr/local/share/perl5 /usr/lib64/perl5/vendor_perl /usr/share/perl5/vendor_perl /usr/lib64/perl5 /usr/share/perl5 .) at /usr/local/bin/pt-query-digest line 2470.BEGIN failed--compilation aborted at /usr/local/bin/pt-query-digest line 2470.解决:yum -y install perl-Digest-MD5
MySQL 慢查询分析工具~pt-query-digest 详解 MySQL 慢查询分析工具~pt-query-digest 详解介绍pt-query-digest 是用于分析 mysql 慢查询的一个工具,它可以分析 binlog、general log、slowlog,也可以通过 SHOW PROCESSLIST 或者通过 tcpdump 抓取的 MySQL 协议数据来进行分析。可以把分析结果输出到文件中,分析过程是先对查询语句的条件进行参数化,然后对参数化以后的查询进行分组统计,统计出各查询的执行时间、次数、占比等,可以借助分析结果找出问题进行优化。安装(yum 安装)yum install perl-DBIyum install perl-DBD-MySQLyum install perl-Time-HiResyum install perl-IO-Socket-SSLwget percona.com/get/pt-query-digestchmod u+x pt-query-digestmv pt-query-digest /usr/bin/语法pt-query-digest [OPTIONS] [FILES] [DSN]--create-review-table 当使用 --review 参数把分析结果输出到表中时,如果没有表就自动创建。--create-history-table 当使用 --history 参数把分析结果输出到表中时,如果没有表就自动创建。--filter 对输入的慢查询按指定的字符串进行匹配过滤后再进行分析。--limit 限制输出结果百分比或数量,默认值是 20, 即将最慢的 20 条语句输出,如果是 50% 则按总响应时间占比从大到小排序,输出到总和达到 50% 位置截止。--host mysql 服务器地址--user mysql 用户名--password mysql 用户密码--history 将分析结果保存到表中,分析结果比较详细,下次再使用 --history 时,如果存在相同的语句,且查询所在的时间区间和历史表中的不同,则会记录到数据表中,可以通过查询同一 CHECKSUM 来比较某类型查询的历史变化。--review 将分析结果保存到表中,这个分析只是对查询条件进行参数化,一个类型的查询一条记录,比较简单。当下次使用 --review 时,如果存在相同的语句分析,就不会记录到数据表中。--output 分析结果输出类型,值可以是 report (标准分析报告)、slowlog (Mysql slow log)、json、json-anon,一般使用 report,以便于阅读。--since 从什么时间开始分析,值为字符串,可以是指定的某个”yyyy-mm-dd [hh:mm:ss]” 格式的时间点,也可以是简单的一个时间值:s (秒)、h (小时)、m (分钟)、d (天),如 12h 就表示从 12 小时前开始统计。--until 截止时间,配合 —since 可以分析一段时间内的慢查询。分析 pt-query-digest 输出结果第一部分:总体统计结果Overall:总共有多少条查询Time range:查询执行的时间范围unique:唯一查询数量,即对查询条件进行参数化以后,总共有多少个不同的查询total:总计 min:最小 max:最大 avg:平均95%:把所有值从小到大排列,位置位于 95% 的那个数,这个数一般最具有参考价值median:中位数,把所有值从小到大排列,位置位于中间那个数该工具执行日志分析的用户时间,系统时间,物理内存占用大小,虚拟内存占用大小340ms user time, 140ms system time, 23.99M rss, 203.11M vsz工具执行时间Current date: Fri Nov 25 02:37:18 2016运行分析工具的主机名Hostname: localhost.localdomain被分析的文件名Files: slow.log语句总数量,唯一的语句数量,QPS,并发数Overall: 2 total, 2 unique, 0.01 QPS, 0.01x concurrency __日志记录的时间范围Time range: 2016-11-22 06:06:18 to 06:11:40属性 总计 最小 最大 平均 95% 标准 中等Attribute total min max avg 95% stddev median============ ======= ======= ======= ======= ======= ======= =======语句执行时间Exec time 3s 640ms 2s 1s 2s 999ms 1s锁占用时间Lock time 1ms 0 1ms 723us 1ms 1ms 723us发送到客户端的行数Rows sent 5 1 4 2.50 4 2.12 2.50select语句扫描行数Rows examine 186.17k 0 186.17k 93.09k 186.17k 131.64k 93.09k查询的字符数Query size 455 15 440 227.50 440 300.52 227.50第二部分:查询分组统计结果Rank:所有语句的排名,默认按查询时间降序排列,通过 --order-by 指定Query ID:语句的 ID,(去掉多余空格和文本字符,计算 hash 值)Response:总的响应时间time:该查询在本次分析中总的时间占比calls:执行次数,即本次分析总共有多少条这种类型的查询语句R/Call:平均每次执行的响应时间V/M:响应时间 Variance-to-mean 的比率Item:查询对象ProfileRank Query ID Response time Calls R/Call V/M Item==== ================== ============= ===== ====== ===== ===============1 0xF9A57DD5A41825CA 2.0529 76.2% 1 2.0529 0.00 SELECT2 0x4194D8F83F4F9365 0.6401 23.8% 1 0.6401 0.00 SELECT wx_member_base第三部分:每一种查询的详细统计结果由下面查询的详细统计结果,最上面的表格列出了执行次数、最大、最小、平均、95% 等各项目的统计。ID:查询的 ID 号,和上图的 Query ID 对应Databases:数据库名Users:各个用户执行的次数(占比)Query_time distribution :查询时间分布,长短体现区间占比,本例中 1s-10s 之间查询数量是 10s 以上的两倍。Tables:查询中涉及到的表Explain:SQL 语句Query 1: 0 QPS, 0x concurrency, ID 0xF9A57DD5A41825CA at byte 802 __This item is included in the report because it matches --limit.Scores: V/M = 0.00Time range: all events occurred at 2016-11-22 06:11:40Attribute pct total min max avg 95% stddev median============ === ======= ======= ======= ======= ======= ======= =======Count 50 1Exec time 76 2s 2s 2s 2s 2s 0 2sLock time 0 0 0 0 0 0 0 0Rows sent 20 1 1 1 1 1 0 1Rows examine 0 0 0 0 0 0 0 0Query size 3 15 15 15 15 15 0 15String:Databases testHosts 192.168.8.1Users mysqlQuery_time distribution1us10us100us1ms10ms100ms1s10s+EXPLAIN /!50100 PARTITIONS/select sleep(2)\G使用例子1.直接分析慢查询文件pt-query-digest slow.log > slow_report.log2.分析最近12小时内的查询pt-query-digest --since=12h slow.log > slow_report2.log3.分析指定时间范围内的查询pt-query-digest slow.log --since '2020-01-07 09:30:00' --until '2020-01-07 10:00:00'> > slow_report3.log3.分析指含有select语句的慢查询pt-query-digest --filter '$event->{fingerprint} =~ m/^select/i' slow.log> slow_report4.log4.分析最近12小时内的查询pt-query-digest --since=12h slow.log > slow_report2.log5.针对某个用户的慢查询pt-query-digest --filter '($event->{user} || "") =~ m/^root/i' slow.log> slow_report5.log6.查询所有所有的全表扫描或full join的慢查询pt-query-digest --filter '(($event->{Full_scan} || "") eq "yes") ||(($event->{Full_join} || "") eq "yes")' slow.log> slow_report6.log7.把查询保存到query_review表pt-query-digest --user=root –password=abc123 --review h=localhost,D=test,t=query_review--create-review-table slow.log8.把查询保存到query_history表pt-query-digest --user=root –password=abc123 --review h=localhost,D=test,t=query_history--create-review-table slow.log_0001pt-query-digest --user=root –password=abc123 --review h=localhost,D=test,t=query_history--create-review-table slow.log_00029.通过tcpdump抓取mysql的tcp协议数据,然后再分析tcpdump -s 65535 -x -nn -q -tttt -i any -c 1000 port 3306 > mysql.tcp.txtpt-query-digest --type tcpdump mysql.tcp.txt> slow_report9.log10.分析binlogmysqlbinlog mysql-bin.000093 > mysql-bin000093.sqlpt-query-digest --type=binlog mysql-bin000093.sql > slow_report10.log11.分析general logpt-query-digest --type=genlog localhost.log > slow_report11.log安装遇到的问题问题:[root@vipstone bin]# pt-query-digest /usr/local/mysql/data/slow.logCan't locate Digest/MD5.pm in @INC (@INC contains: /usr/local/lib64/perl5 /usr/local/share/perl5 /usr/lib64/perl5/vendor_perl /usr/share/perl5/vendor_perl /usr/lib64/perl5 /usr/share/perl5 .) at /usr/local/bin/pt-query-digest line 2470.BEGIN failed--compilation aborted at /usr/local/bin/pt-query-digest line 2470.解决:yum -y install perl-Digest-MD5 -
MySQL 的学习资源史上最全 MySQL 的学习资源史上最全github欢迎对 MySQL 感兴趣的同学一起来完善这个有意义的项目:MySQL 精进大全 https://github.com/zhangdejian/MySQL_Refinement_Resource官方资料MySQL 官方文档MySQL Server Blogmariadb 的关于查询优化的文档书籍基础版:《MySQL必知必会》《数据库系统概念》高级版:《高性能MySQL(第3版)》《MySQL技术内幕(第4版)》《MySQL技术内幕 InnoDB存储引擎》《MySQL性能调优与架构设计--全册》《深入理解MySQL》《MySQL DBA修炼之道》《数据库查询优化器的艺术》《MySQL运维内参》《Effective MySQL:Optimizing SQL Statements》《数据库事务处理的艺术》《事务处理概念与技术》《MySQL DBA工作笔记》大神博客何登成 何登成的技术博客 (阿里数据库专家)淘宝丁奇 追风刀・丁奇 - ITeye 技术网站周振兴 @淘宝 花名:苏普 一个故事 @MySQL DBAorczhou 的博客Jeremy Cole 的博客那海蓝蓝(李海翔)的博客taobao 月报mysql_lover 的博客非官方优化文档优秀公众号我们都是小青蛙 (掘金 MySQL 小册的作者)张德 Talk (MySQL 持续精进)DBAplus 社群 (数据库专业公众号)杨建荣的学习笔记学习网站菜鸟 MySQL 教程MySQL Tutorial阿里云大学免费教程《MySQL 数据库入门学习》、《MySQL 高级应用 - 索引和锁》慕课网免费视频教程优秀专栏掘金小册 《MySQL 是怎样运行的:从根儿上理解 MySQL》 (强烈推荐,既便宜又通俗易懂,目前讲得最好的专栏之一)极客时间专栏:MySQL 实战 45 讲(丁奇的专栏,干货很多)优秀文章一张图彻底搞懂 MySQL 的 explain一张图彻底搞懂 MySQL 的锁机制MySQL 知识点总结数据库事务与 MySQL 事务总结MySQL 的万字总结(缓存,索引,Explain,事务,redo 日志等)我以为我对 Mysql 索引很了解,直到我遇到了阿里的面试官腾讯面试:一条 SQL 语句执行得很慢的原因有哪些?— 不看后悔系列你知道 MySQL 的 Limit 有性能问题吗数据库面试题 (开发者必看)后端程序员必备:mysql 数据库相关流程图 / 原理图数据库两大神器【索引和锁】客官,这里有一份《MySQL 必知必会》读书笔记,请您笑纳!《金三银四》面试官:说说事务的 ACID,什么是脏读、幻读?推荐收藏!MySQL 重要知识点 / 面试题总结不就是 SELECT COUNT 语句吗,竟然能被面试官虐的体无完肤一次难得的分库分表实践MySQL 规范面试 (MySQL 索引为啥要选择 B+ 树)这个 SQL 问题绝对能让你对 MySQL 的理解更进一步!MySQL 社区规范 | 数据库篇MySQL 避坑宝典 – 来自小米的开源工具MySQL 细致总结之中级篇MySQL 索引和 SQL 调优MySQL 优化原理MySQL 优化面试一千行 MySQL 命令MySQL 优化那些事儿项目中常用的 19 条 MySQL 优化MySQL 命令,一篇文章替你全部搞定从根上理解 MySQL 的事务MySQL 快速创建千万级测试数据为什么开发人员必须要了解数据库锁?一次诡异的线上数据库的死锁问题排查过程亿级流量系统架构之如何设计每秒十万查询的高并发架构【石杉的架构笔记】一条 SQL 语句在 MySQL 中是如何执行的深入理解分布式事务Mysql 百万级数据迁移实战笔记关于 MySQL 的知识点与面试常见问题都在这里「mysql 优化专题」程序员面试都用得上的索引优化手册 (5)【面试重点】MySql 日常指导,及大表优化思路MySQL 在并发场景下的问题及解决思路彻底搞懂 MySQL 事务的隔离级别
-
一张图彻底搞定 explain 一张图彻底搞定 explainexplain 关键字可以模拟 MySQL 优化器执行 SQL 语句,可以很好的分析 SQL 语句或表结构的性能瓶颈。explain 的用途表的读取顺序如何数据读取操作有哪些操作类型哪些索引可以使用哪些索引被实际使用表之间是如何引用每张表有多少行被优化器查询......explain 的执行效果mysql> explain select * from subject where id = 1 \G id: 1select_type: SIMPLE table: subjectpartitions: NULL type: constpossible_keys: PRIMARY key: PRIMARYkey_len: 4 ref: const rows: 1filtered: 100.00 Extra: NULLexplain 包含的字段id //select查询的序列号,包含一组数字,表示查询中执行select子句或操作表的顺序select_type //查询类型table //正在访问哪个表partitions //匹配的分区type //访问的类型possible_keys //显示可能应用在这张表中的索引,一个或多个,但不一定实际使用到key //实际使用到的索引,如果为NULL,则没有使用索引key_len //表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度ref //显示索引的哪一列被使用了,如果可能的话,是一个常数,哪些列或常量被用于查找索引列上的值rows //根据表统计信息及索引选用情况,大致估算出找到所需的记录所需读取的行数filtered //查询的表行占表的百分比Extra //包含不适合在其它列中显示但十分重要的额外信息图片版文字版id 字段id 相同执行顺序从上至下例子:explain select subject.* from subject,student_score,teacher where subject.id = student_id and subject.teacher_id = teacher.id;读取顺序:subject > teacher > student_scoreid 不同如果是子查询,id的序号会递增,id的值越大优先级越高,越先被执行例子:explain select score.* from student_score as score where subject_id = (select id from subject where teacher_id = (select id from teacher where id = 2));读取顺序:teacher > subject > student_scoreid 相同又不同id如果相同,可以认为是一组,从上往下顺序执行在所有组中,id值越大,优先级越高,越先执行例子:explain select subject.* from subject left join teacher on subject.teacher_id = teacher.id -> union -> select subject.* from subject right join teacher on subject.teacher_id = teacher.id; 读取顺序:2.teacher > 2.subject > 1.subject > 1.teacherselect_type 字段SIMPLE简单查询,不包含子查询或Union查询例子:explain select subject.* from subject,student_score,teacher where subject.id = student_id and subject.teacher_id = teacher.id;PRIMARY查询中若包含任何复杂的子部分,最外层查询则被标记为主查询例子:explain select score.* from student_score as score where subject_id = (select id from subject where teacher_id = (select id from teacher where id = 2));SUBQUERY在select或where中包含子查询例子:explain select score.* from student_score as score where subject_id = (select id from subject where teacher_id = (select id from teacher where id = 2));DERIVED在FROM列表中包含的子查询被标记为DERIVED(衍生),MySQL会递归执行这些子查询,把结果放在临时表中备注:MySQL5.7+ 进行优化了,增加了derived_merge(派生合并),默认开启,可加快查询效率UNION若第二个select出现在uion之后,则被标记为UNION例子:explain select subject.* from subject left join teacher on subject.teacher_id = teacher.id -> union -> select subject.* from subject right join teacher on subject.teacher_id = teacher.id;UNION RESULT从UNION表获取结果的select例子:explain select subject.* from subject left join teacher on subject.teacher_id = teacher.id -> union -> select subject.* from subject right join teacher on subject.teacher_id = teacher.id;type 字段NULL>system>const>eq_ref>ref>fulltext>ref_or_null>index_merge>unique_subquery>index_subquery>range>index>ALL //最好到最差备注:掌握以下10种常见的即可NULL>system>const>eq_ref>ref>ref_or_null>index_merge>range>index>ALLNULLMySQL能够在优化阶段分解查询语句,在执行阶段用不着再访问表或索引例子:explain select min(id) from subject;system表只有一行记录(等于系统表),这是const类型的特列,平时不大会出现,可以忽略const表示通过索引一次就找到了,const用于比较primary key或uique索引,因为只匹配一行数据,所以很快,如主键置于where列表中,MySQL就能将该查询转换为一个常量例子:explain select * from teacher where teacher_no = 'T2010001';eq_ref唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配,常见于主键或唯一索引扫描例子:explain select subject.* from subject left join teacher on subject.teacher_id = teacher.id;ref非唯一性索引扫描,返回匹配某个单独值的所有行本质上也是一种索引访问,返回所有匹配某个单独值的行然而可能会找到多个符合条件的行,应该属于查找和扫描的混合体例子:explain select subject.* from subject,student_score,teacher where subject.id = student_id and subject.teacher_id = teacher.id;ref_or_null类似ref,但是可以搜索值为NULL的行例子:explain select * from teacher where name = 'wangsi' or name is null;index_merge表示使用了索引合并的优化方法例子:explain select * from teacher where id = 1 or teacher_no = 'T2010001' .range只检索给定范围的行,使用一个索引来选择行,key列显示使用了哪个索引一般就是在你的where语句中出现between、<>、in等的查询。例子:explain select * from subject where id between 1 and 3;indexFull index Scan,Index与All区别:index只遍历索引树,通常比All快因为索引文件通常比数据文件小,也就是虽然all和index都是读全表,但index是从索引中读取的,而all是从硬盘读的。例子:explain select id from subject;ALLFull Table Scan,将遍历全表以找到匹配行例子:explain select * from subject;table 字段数据来自哪张表possible_keys 字段显示可能应用在这张表中的索引,一个或多个查询涉及到的字段若存在索引,则该索引将被列出,但不一定被实际使用key 字段 实际使用到的索引,如果为NULL,则没有使用索引查询中若使用了覆盖索引(查询的列刚好是索引),则该索引仅出现在key列表key_len 字段 表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度在不损失精确度的情况下,长度越短越好key_len显示的值为索引字段最大的可能长度,并非实际使用长度即key_len是根据定义计算而得,不是通过表内检索出的ref 字段 显示索引的哪一列被使用了,如果可能的话,是一个常数,哪些列或常量被用于查找索引列上的值rows 字段 根据表统计信息及索引选用情况,大致估算出找到所需的记录所需读取的行数partitions 字段 匹配的分区filtered 字段 查询的表行占表的百分比Extra 字段 包含不适合在其它列中显示但十分重要的额外信息Using filesort说明MySQL会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取MySQL中无法利用索引完成的排序操作称为“文件排序”例子:explain select * from subject order by name;Using temporary使用了临时表保存中间结果,MySQL在对结果排序时使用临时表,常见于排序order by 和分组查询group by例子:explain select subject.* from subject left join teacher on subject.teacher_id = teacher.id -> union -> select subject.* from subject right join teacher on subject.teacher_id = teacher.id;Using index表示相应的select操作中使用了覆盖索引(Covering Index),避免访问了表的数据行,效率不错!如果同时出现using where,表明索引被用来执行索引键值的查找如果没有同时出现using where,表明索引用来读取数据而非执行查找动作例子:explain select subject.* from subject,student_score,teacher where subject.id = student_id and subject.teacher_id = teacher.id;备注:覆盖索引:select的数据列只用从索引中就能够取得,不必读取数据行,MySQL可以利用索引返回select列表中的字段,而不必根据索引再次读取数据文件,即查询列要被所建的索引覆盖Using where使用了where条件例子:explain select subject.* from subject,student_score,teacher where subject.id = student_id and subject.teacher_id = teacher.id;Using join buffer使用了连接缓存例子:explain select student.,teacher.,subject.* from student,teacher,subject;impossible wherewhere子句的值总是false,不能用来获取任何元组例子:explain select * from teacher where name = 'wangsi' and name = 'lisi';distinct一旦mysql找到了与行相联合匹配的行,就不再搜索了例子:explain select distinct teacher.name from teacher left join subject on teacher.id = subject.teacher_id;Select tables optimized awaySELECT操作已经优化到不能再优化了(MySQL根本没有遍历表或索引就返回数据了)例子:explain select min(id) from subject;使用的数据表create table subject( -> id int(10) auto_increment, -> name varchar(20), -> teacher_id int(10), -> primary key (id), -> index idx_teacher_id (teacher_id));//学科表create table teacher( -> id int(10) auto_increment, -> name varchar(20), -> teacher_no varchar(20), -> primary key (id), -> unique index unx_teacher_no (teacher_no(20)));//教师表create table student( -> id int(10) auto_increment, -> name varchar(20), -> student_no varchar(20), -> primary key (id), -> unique index unx_student_no (student_no(20)));//学生表create table student_score( -> id int(10) auto_increment, -> student_id int(10), -> subject_id int(10), -> score int(10), -> primary key (id), -> index idx_student_id (student_id), -> index idx_subject_id (subject_id));//学生成绩表alter table teacher add index idx_name(name(20));//教师表增加名字普通索引数据填充: insert into student(name,student_no) values ('zhangsan','20200001'),('lisi','20200002'),('yan','20200003'),('dede','20200004');insert into teacher(name,teacher_no) values('wangsi','T2010001'),('sunsi','T2010002'),('jiangsi','T2010003'),('zhousi','T2010004');insert into subject(name,teacher_id) values('math',1),('Chinese',2),('English',3),('history',4);insert into student_score(student_id,subject_id,score) values(1,1,90),(1,2,60),(1,3,80),(1,4,100),(2,4,60),(2,3,50),(2,2,80),(2,1,90),(3,1,90),(3,4,100),(4,1,40),(4,2,80),(4,3,80),(4,5,100);
-
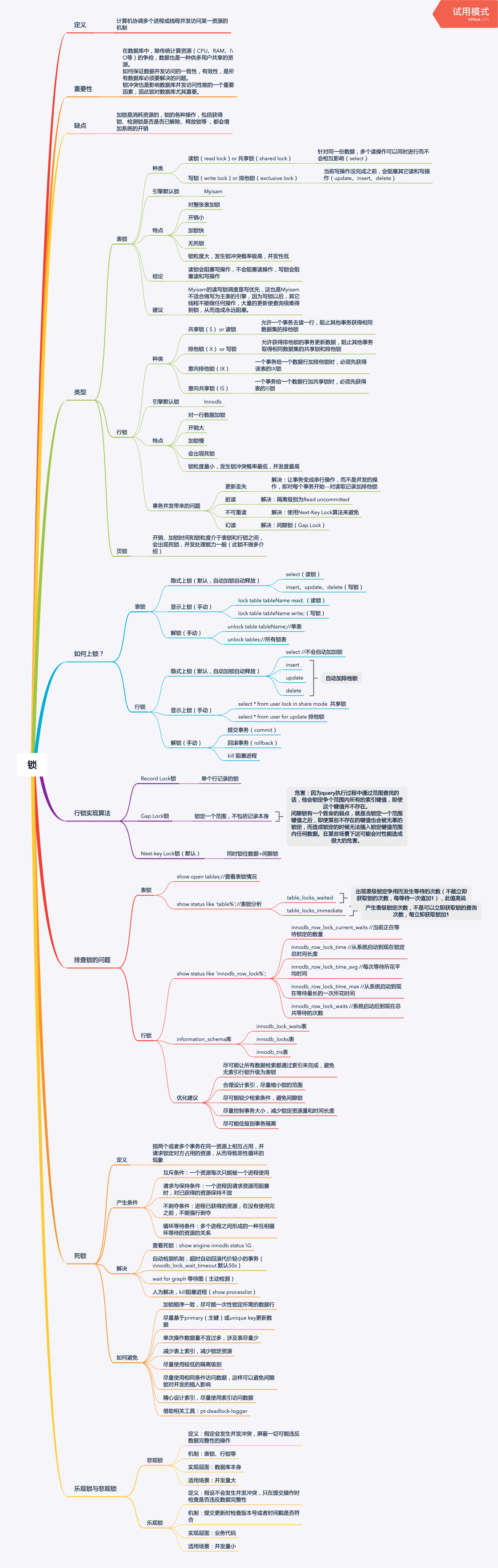
一张图彻底搞懂 MySQL 的锁机制 一张图彻底搞懂 MySQL 的锁机制锁在 MySQL 中是非常重要的一部分,锁对 MySQL 的数据访问并发有着举足轻重的影响。锁涉及到的知识篇幅也很多,所以要啃完并消化到自己的肚子里,是需要静下心好好反反复复几遍地细细品味。本文是对锁的一个大概的整理,一些相关深入的细节,还是需要找到相关书籍来继续夯实。锁的认识1.1 锁的解释计算机协调多个进程或线程并发访问某一资源的机制。1.2 锁的重要性在数据库中,除传统计算资源(CPU、RAM、I\O等)的争抢,数据也是一种供多用户共享的资源。如何保证数据并发访问的一致性,有效性,是所有数据库必须要解决的问题。锁冲突也是影响数据库并发访问性能的一个重要因素,因此锁对数据库尤其重要。1.3 锁的缺点加锁是消耗资源的,锁的各种操作,包括获得锁、检测锁是否已解除、释放锁等 ,都会增加系统的开销。1.4 简单的例子现如今网购已经特别普遍了,比如淘宝双十一活动,当天的人流量是千万及亿级别的,但商家的库存是有限的。系统为了保证商家的商品库存不发生超卖现象,会对商品的库存进行锁控制。当有用户正在下单某款商品最后一件时,系统会立马对该件商品进行锁定,防止其他用户也重复下单,直到支付动作完成才会释放(支付成功则立即减库存售罄,支付失败则立即释放)。锁的类型2.1 表锁种类读锁(read lock),也叫共享锁(shared lock)针对同一份数据,多个读操作可以同时进行而不会互相影响(select)写锁(write lock),也叫排他锁(exclusive lock)当前操作没完成之前,会阻塞其它读和写操作(update、insert、delete)存储引擎默认锁MyISAM特点对整张表加锁开销小加锁快无死锁锁粒度大,发生锁冲突概率大,并发性低结论读锁会阻塞写操作,不会阻塞读操作写锁会阻塞读和写操作建议MyISAM的读写锁调度是写优先,这也是MyISAM不适合做写为主表的引擎,因为写锁以后,其它线程不能做任何操作,大量的更新使查询很难得到锁,从而造成永远阻塞。2.2 行锁种类读锁(read lock),也叫共享锁(shared lock)允许一个事务去读一行,阻止其他事务获得相同数据集的排他锁写锁(write lock),也叫排他锁(exclusive lock)允许获得排他锁的事务更新数据,阻止其他事务取得相同数据集的共享锁和排他锁意向共享锁(IS)一个事务给一个数据行加共享锁时,必须先获得表的IS锁意向排它锁(IX)一个事务给一个数据行加排他锁时,必须先获得该表的IX锁存储引擎默认锁InnoDB特点对一行数据加锁开销大加锁慢会出现死锁锁粒度小,发生锁冲突概率最低,并发性高事务并发带来的问题更新丢失解决:让事务变成串行操作,而不是并发的操作,即对每个事务开始---对读取记录加排他锁脏读解决:隔离级别为Read uncommitted不可重读解决:使用Next-Key Lock算法来避免幻读解决:间隙锁(Gap Lock)2.3 页锁开销、加锁时间和锁粒度介于表锁和行锁之间,会出现死锁,并发处理能力一般(此锁不做多介绍)如何上锁?3.1 表锁隐式上锁(默认,自动加锁自动释放)select //上读锁insert、update、delete //上写锁显式上锁(手动)lock table tableName read;//读锁lock table tableName write;//写锁解锁(手动)unlock tables;//所有锁表session01 session02lock table teacher read;// 上读锁select from teacher; // 可以正常读取 select from teacher;// 可以正常读取update teacher set name = 3 where id =2;// 报错因被上读锁不能写操作 update teacher set name = 3 where id =2;// 被阻塞unlock tables;// 解锁update teacher set name = 3 where id =2;// 更新操作成功session01 session02lock table teacher write;// 上写锁select from teacher; // 可以正常读取 select from teacher;// 被阻塞update teacher set name = 3 where id =2;// 可以正常更新操作 update teacher set name = 4 where id =2;// 被阻塞unlock tables;// 解锁select * from teacher;// 读取成功update teacher set name = 4 where id =2;// 更新操作成功3.2 行锁隐式上锁(默认,自动加锁自动释放)select //不会上锁insert、update、delete //上写锁显式上锁(手动)select * from tableName lock in share mode;//读锁select * from tableName for update;//写锁解锁(手动)提交事务(commit)回滚事务(rollback)kill 阻塞进程session01 session02begin;select * from teacher where id = 2 lock in share mode;// 上读锁select * from teacher where id = 2;// 可以正常读取update teacher set name = 3 where id =2;// 可以更新操作 update teacher set name = 5 where id =2;// 被阻塞commit;update teacher set name = 5 where id =2;// 更新操作成功session01 session02begin;select * from teacher where id = 2 for update;// 上写锁select * from teacher where id = 2;// 可以正常读取update teacher set name = 3 where id =2;// 可以更新操作 update teacher set name = 5 where id =2;// 被阻塞rollback;update teacher set name = 5 where id =2;// 更新操作成功为什么上了写锁,别的事务还可以读操作?因为InnoDB有MVCC机制(多版本并发控制),可以使用快照读,而不会被阻塞。行锁的实现算法4.1 Record Lock 锁单个行记录上的锁Record Lock总是会去锁住索引记录,如果InnoDB存储引擎表建立的时候没有设置任何一个索引,这时InnoDB存储引擎会使用隐式的主键来进行锁定4.2 Gap Lock 锁当我们用范围条件而不是相等条件检索数据,并请求共享或排他锁时,InnoDB会给符合条件的已有数据记录的索引加锁,对于键值在条件范围内但并不存在的记录。优点:解决了事务并发的幻读问题不足:因为query执行过程中通过范围查找的话,他会锁定争个范围内所有的索引键值,即使这个键值并不存在。间隙锁有一个致命的弱点,就是当锁定一个范围键值之后,即使某些不存在的键值也会被无辜的锁定,而造成锁定的时候无法插入锁定键值范围内任何数据。在某些场景下这可能会对性能造成很大的危害。4.3 Next-key Lock 锁同时锁住数据+间隙锁在Repeatable Read隔离级别下,Next-key Lock 算法是默认的行记录锁定算法。4.4 行锁的注意点只有通过索引条件检索数据时,InnoDB才会使用行级锁,否则会使用表级锁(索引失效,行锁变表锁)即使是访问不同行的记录,如果使用的是相同的索引键,会发生锁冲突如果数据表建有多个索引时,可以通过不同的索引锁定不同的行如何排查锁?5.1 表锁查看表锁情况show open tables;表锁分析show status like 'table%';table_locks_waited出现表级锁定争用而发生等待的次数(不能立即获取锁的次数,每等待一次值加1),此值高说明存在着较严重的表级锁争用情况table_locks_immediate产生表级锁定次数,不是可以立即获取锁的查询次数,每立即获取锁加15.2 行锁行锁分析show status like 'innodb_row_lock%';innodb_row_lock_current_waits //当前正在等待锁定的数量innodb_row_lock_time //从系统启动到现在锁定总时间长度innodb_row_lock_time_avg //每次等待所花平均时间innodb_row_lock_time_max //从系统启动到现在等待最长的一次所花时间innodb_row_lock_waits //系统启动后到现在总共等待的次数information_schema 库innodb_lock_waits表innodb_locks表innodb_trx表优化建议尽可能让所有数据检索都通过索引来完成,避免无索引行锁升级为表锁合理设计索引,尽量缩小锁的范围尽可能较少检索条件,避免间隙锁尽量控制事务大小,减少锁定资源量和时间长度尽可能低级别事务隔离死锁6.1 解释指两个或者多个事务在同一资源上相互占用,并请求锁定对方占用的资源,从而导致恶性循环的现象6.2 产生的条件互斥条件:一个资源每次只能被一个进程使用请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放不剥夺条件:进程已获得的资源,在没有使用完之前,不能强行剥夺循环等待条件:多个进程之间形成的一种互相循环等待的资源的关系6.1 解决查看死锁:show engine innodb status \G自动检测机制,超时自动回滚代价较小的事务(innodb_lock_wait_timeout 默认50s)人为解决,kill阻塞进程(show processlist)wait for graph 等待图(主动检测)6.1 如何避免加锁顺序一致,尽可能一次性锁定所需的数据行尽量基于primary(主键)或unique key更新数据单次操作数据量不宜过多,涉及表尽量少减少表上索引,减少锁定资源尽量使用较低的隔离级别尽量使用相同条件访问数据,这样可以避免间隙锁对并发的插入影响精心设计索引,尽量使用索引访问数据借助相关工具:pt-deadlock-logger乐观锁与悲观锁7.1 悲观锁解释假定会发生并发冲突,屏蔽一切可能违反数据完整性的操作实现机制表锁、行锁等实现层面数据库本身适用场景并发量大7.2 乐观锁解释假设不会发生并发冲突,只在提交操作时检查是否违反数据完整性实现机制提交更新时检查版本号或者时间戳是否符合实现层面业务代码适用场景并发量小
-
添加一个mysql用户并给予权限 老板:让你添加一个mysql用户并给予权限这么费劲吗?前言今天,程序员小王被老板训了一顿,还被扣了 1k 的工资,原因就是因为有一个项目已经上线,客户这边要求给数据库新添加一个用户,并给予用户某些权限,但是小王由于对这么方面有点生疏,都是现百度现实现,导致工作效率低,引发了老板的不满。小王痛定思痛,下决心要搞明白 mysql 的创建用户及授权,经过查阅各种资料学习, 小王对此了解的八九不离十了,从而在老板面前硬了起来……一、新建一个用户老板:给我新建一个用户joytom,密码设置为123321,并任意远程主机都能访问,五分钟完成,实现不了就给我提桶走人!小王会心一笑,对创建用户的命令早已滚瓜烂熟了,于是熟练的操作了起来:1、创建用户命令:CREATE USER ‘username‘@’host’ IDENTIFIED BY ‘password’;属性名 含义username 登陆用户名host 指定可访问的 ip,如果指定所有 ip 都能访问,将其设为通配符 % 即可。password 登陆密码,如果密码为空则无需密码2、创建用户mysql> CREATE USER 'joytom'@'%' IDENTIFIED BY '123321';Query OK, 0 rows affected (0.00 sec)查看一下是否创建成功:mysql> select user,host from user;userhostcopytest%joytom%test%root127.0.0.1root::1 localhostrootlocalhost vm-8-5-centosrootvm-8-5-centos10 rows in set (0.00 sec)3、从另一台服务器上远程登录一下:[root@instance-lzmtqrkn ~]# mysql -h 创建用户的服务器公网ip -P 3306 -u joytom -p123321Welcome to the MySQL monitor. Commands end with ; or \g.Your MySQL connection id is 784Server version: 5.6.49-log Source distributionCopyright (c) 2000, 2020, Oracle and/or its affiliates. All rights reserved.Oracle is a registered trademark of Oracle Corporation and/or itsaffiliates. Other names may be trademarks of their respectiveowners.Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.mysql> show databases;Databaseinformation_schema1 row in set (0.03 sec)查看一下数据库,发现是没有权限的,只能看到 information_schema 数据库。二、为用户授权创建完用户后……老板:好,比以前有进步了,那你再给joytom这个用户设置一个权限,只允许查询和修改copytest数据库中的student表。小王信手拈来,又熟练的操作了一波:1、给用户授权命令grant privileges on database.tablename to “username”@’host’;privileges:用户的操作权限,如 SELECT,INSERT,UPDATE 等,如果要授予所的权限则使用 ALL。属性名 含义privileges 用户的操作权限,如 SELECT,INSERT,UPDATE 等,如果要授予所的权限则使用 ALL。database 如果不指定数据库,直接 . 即可,如果指定数据库但不指定表名,则 database.* 即可。username 登陆的用户名host 给予授权的主机 ip,例如我想让用户A的ip使用joytom用户所授予的权限,但是不想让用户B的ip来使用joytom用户的权限。2、给 joytom 用户授可查、改的权限。mysql> grant select,update on copytest.student to "joytom"@'%';Query OK, 0 rows affected (0.00 sec)3、另一台服务器去测试:发现能看到 copytest 数据库:mysql> show databases;Databaseinformation_schemacopytest2 rows in set (0.04 sec)查看一下 copytest 数据库中的 student 表:mysql> use copytest;Database changedmysql> select * from student;idname1王2李3张3 rows in set (0.04 sec)修改一下 student 表:mysql> update student set name = '小王' where id = 1;Query OK, 1 row affected (0.04 sec)Rows matched: 1 Changed: 1 Warnings: 0mysql> select * from student;idname1小王2李3张3 rows in set (0.04 sec)那删除一下 student 表中的数据呢:mysql> delete from student where id = 1;ERROR 1142 (42000): DELETE command denied to user 'joytom'@'xxxxxx' for table 'student'发现没有删除的权限,只能进行查询和修改。4、在给 joytom 用户增加一个查看视图的权限mysql> grant SHOW VIEW on copytest.student to "joytom"@'%';Query OK, 0 rows affected (0.00 sec)mysql> flush privileges;Query OK, 0 rows affected (0.01 sec)之前是只有查询和修改的权限,现在在查看一下:mysql> show grants for 'joytom'@'%';Grants for joytom@%GRANT USAGE ON . TO 'joytom'@'%' IDENTIFIED BY PASSWORD '*437F1809645E0A92DAB553503D2FE21DB91270FD'GRANT SELECT, UPDATE, SHOW VIEW ON copytest.student TO 'joytom'@'%'2 rows in set (0.00 sec)发现,已经有了查看视图的权限。三、撤销用户权限老板:咳咳,很好,现在 joytom 不是有三个权限了么(查询,修改,查询视图),那你把查询视图的权限给去掉,只留查询和修改。小王心中暗喜,这我都学了,很基础的啊……1、撤销用户权限命令revoke privileges ON database.tablename FROM ‘username‘@’host’;撤销(revoke)的和授予(grant)的基本一样,除了 revoke(对应 grant)和 from(对应 to)2、撤销 joytom 用户的查看视图的权限mysql> revoke SHOW VIEW on copytest.student from "joytom"@'%';Query OK, 0 rows affected (0.00 sec)mysql> flush privileges;Query OK, 0 rows affected (0.00 sec)再次查看:mysql> show grants for 'joytom'@'%';Grants for joytom@%GRANT USAGE ON . TO 'joytom'@'%' IDENTIFIED BY PASSWORD '*437F1809645E0A92DAB553503D2FE21DB91270FD'GRANT SELECT, UPDATE ON copytest.student TO 'joytom'@'%'2 rows in set (0.00 sec)发现已经没了查看视图的权限。grant, revoke 用户权限后,该用户只有重新连接 MySQL 数据库,权限才能生效。四、删除一个用户老板:把 joytom 这个用户删掉让我看看。小王:好嘞,40 秒完事。1、删除用户命令drop user username@host2、删除用户先查看一下现在的所有用户:mysql> select user,host from user;userhostcopytest%joytom%test%root127.0.0.1root::1 localhostrootlocalhost vm-8-5-centosrootvm-8-5-centos10 rows in set (0.00 sec)删除 joytom:mysql> drop user joytom@'%';Query OK, 0 rows affected (0.00 sec)再次查看,发现已经没了 joytom 这个用户:mysql> select user,host from user;userhostcopytest%test%root127.0.0.1root::1 localhostrootlocalhost vm-8-5-centosrootvm-8-5-centos10 rows in set (0.00 sec)五、修改用户的密码老板:把 joytom 这个用户密码修改一下。小王:好嘞老板。1、修改用户密码命令set PASSWORD FOR ‘username‘@’%’ = PASSWORD (‘要修改的密码’)2、修改用户SET PASSWORD FOR 'joytom'@'%' = PASSWORD('123123');六、密码过期和锁定用户老板大喜:非常好非常好,加薪 2k,继续努力,另外给其它同事讲一下密码过期和锁定用户的问题。感谢老板,我会继续努力,我这就去整理一下课件。1、关于密码过期在 MySQL5.6.6 版本起,增加了 password_expired 功能,它允许设置 MySQL 数据库用户的密码过期时间。这个特性已经添加到 mysql.user 数据表,它的默认值是”N”,表示已禁用密码过期功能强制设置为密码过期:mysql> ALTER USER 'joytom'@'%' PASSWORD EXPIRE;Query OK, 0 rows affected (0.00 sec)强制设置密码过期后,虽然能够登陆,但是一切权限都为空了。2、关于 mysql5.7 锁定用户在创建的时候锁定用户:CREATE USER 'username'@'host' account unlock;已存在的时候锁定用户:ALTER USER 'joytom'@'%' ACCOUNT LOCK;解锁账号:ALTER USER 'joytom'@'%' ACCOUNT UNLOCK七、权限常用关键字老板:现在你对 mysql 的权限管理掌握的还算可以了,咳咳,今天下班前给我整理一个权限常用关键字,整理不好就加会班吧。小王想,幸亏这个我在学的时候就已经整理过啊,看样今天不用加班了!