搜索到
785
篇与
的结果
-
 为什么过早的优化是万恶之源? 为什么过早的优化是万恶之源?缘起Donald Knuth(高德纳) 是一位计算机科学界的著名学者和计算机程序设计的先驱之一。他被誉为 计算机科学的“圣经”《计算机程序设计艺术》的作者 ,提出了著名的“大O符号”来描述算法的时间复杂度和空间复杂度,开发了TeX系统用于排版科技文献,获得过图灵奖、冯·诺伊曼奖、美国国家科学奖章等多项荣誉。今天要说的就是他所提出的一条 软件设计重要原则 Premature optimization is the root of all evil 过早优化是万恶之源。 为什么说“过早优化是万恶之源”?我认为过早优化代码会让人陷入到错误的目标中去,从而忽视掉了最重要的目标。举个很简单的例子, 你需要快速构建一个产品来抢占用户,你当下最重要的目标是让这个产品快速上线 ,而不是把这个产品打造的好用(在中国互联网下,这样的事数不胜数), 如果你只关注到后者体验、性能问题而忽视了速度,在当下高度竞争的市场之下,你根本毫无机会。 当然上面这个例子是从感性的层面说的,对很多程序猿来说也可能涉及不到产品层面的内容。我们从软件设计的层面,理性的来说,过早优化可能会导致以下的一些问题:1. 增加代码的复杂性 :过度优化可能会导致代码的复杂性增加,从而降低代码的可读性和可维护性。如果代码过于复杂,可能会导致开发人员难以理解和维护代码,从而增加开发成本和时间。 2. 耗费开发时间和资源 :过度优化可能会导致开发人员花费大量时间和资源在代码的性能优化上,而忽略了其他重要的开发任务。这可能会导致项目进度延误和开发成本增加。 3. 降低代码的可移植性 :过度优化可能会导致代码的可移植性降低。如果代码过于依赖于特定的硬件或操作系统,可能会导致代码无法在其他环境中运行。 4. 降低代码的可扩展性 :过度优化可能会降低代码的可扩展性。如果代码过于依赖于特定的算法或数据结构,可能会导致代码无法适应未来的需求变化。过早优化的典型案例在软件工程史上由于过度关注软件性能导致项目最终失败的案例比比皆是,比如我下面要说的一些项目,在软件工程史上都是非常知名的项目(当然可能有些新生代程序员已经不知道了)。1. IBM OS/360操作系统 :在20世纪60年代,IBM公司开发了OS/360操作系统,这是当时最大的软件工程项目之一。在开发过程中,IBM公司过于关注代码的性能问题,导致代码的复杂性增加,开发时间延误,最终导致项目的失败。我知晓这个项目还是在我最近在阅读的一本软件工程经典书籍《人月神话》中,也推荐大家阅读下,这个项目虽然最终失败了,但也给整个软件工程领域留下了宝贵的经验。 2. Netscape Navigator浏览器 :在20世纪90年代,Netscape公司开发了Navigator浏览器,这是当时最流行的浏览器之一。在开发过程中,Netscape公司过于关注代码的性能问题,导致代码的复杂性增加,开发时间延误,最终导致浏览器市场份额严重下降。 3. Windows Vista操作系统 :在21世纪初,微软公司开发了Windows Vista操作系统,这是当时最大的软件工程项目之一。在开发过程中,微软公司过于关注代码的性能问题,导致代码的复杂性增加,开发时间延误,最终导致操作系统的用户体验不佳,市场反响不佳。话说这个操作系统我还用过呢,用户界面还是很漂亮的,很多UI设计也被沿用到了Window7中。如何识别过早优化在软件开发过程中,如何判断是否过早优化呢?这里有一些概括性的判断标准,可以简单参考下:1. 是否存在性能问题: 如果代码还没有性能问题,那么过早优化就是不必要的。因此,在进行优化之前,应该先测试代码的性能,确定是否存在性能问题。 2. 是否优化了未来可能发生的问题 :如果优化的是未来可能发生的问题,而不是当前存在的问题,那么就可能是过早优化。在进行优化之前,应该优先考虑当前存在的问题,而不是未来可能发生的问题。 3. 是否牺牲了代码的可读性和可维护性 :如果优化代码会导致代码的复杂性增加,降低代码的可读性和可维护性,那么就可能是过早优化。在进行优化之前,应该优先考虑代码的可读性、可维护性和可扩展性。 4. 是否浪费了大量的开发时间和资源 :如果优化代码会浪费大量的开发时间和资源,而不是提高代码的性能和效率,那么就可能是过早优化。在进行优化之前,应该评估优化的成本和收益,确定是否值得进行优化。判断是否过早优化需要根据具体情况进行评估。 在进行优化之前,应该先测试代码的性能,确定是否存在性能问题。同时,也应该优先考虑代码的可读性、可维护性和可扩展性,避免过度优化。总结作为一名在IT领域摸爬滚打多年的工程师,我深有体会地认识到过早优化是软件开发中的一大陷阱。在软件开发的初期,我们可能会过于关注代码的性能问题,而忽略了代码的可读性、可维护性和可扩展性。这种做法可能会导致代码的复杂性增加,降低代码的可读性和可维护性,甚至可能会浪费大量的开发时间和资源。在软件开发过程中,我们应该避免过早优化,而是优先考虑代码的可读性、可维护性和可扩展性。当需要进行性能优化时,应该在代码的基础上进行优化,通过分析性能瓶颈、优化算法和数据结构等方法来提高代码的性能和效率。同时,我们也应该意识到, 性能优化并不是软件开发的唯一目标,我们还应该注重代码的可读性、可维护性和可扩展性,以便保证代码的质量和可靠性。拓展代码优化的好处多多,但是这并不意味着所有的代码都需要进行优化,有时过度的优化反而适得其反——费时、费力、不讨好。“现代计算机科学的鼻祖”Donald Knuth曾说过“过早的优化是万恶之源”,因为:让正确的程序更快,要比让快速的程序正确容易得多。在项目开发中,总是有程序员浪费宝贵的时间去改进那些不需要改进的代码,而没有通过所做的改进增加价值。在对项目进行优化时,究竟哪些地方应该优化,应该如何优化,哪些不应该优化呢?你需要先来了解一下本文所说的这7件事。1. 究竟要优化什么?在优化工作开始的时候,你还尚未明确优化内容和目的,那么你很容易陷入误区。在一开始,你就应该清楚地了解你要达到的效果,以及其他优化相关的各种问题。这些目标需要明确指出(至少精通技术的项目经理可以理解和表达它),接下来,在整个优化过程中,你需要坚持这些目标。在实际的项目开发中,经常会存在各种各样的变数。可能一开始时要优化这一方面,随后你可能会发现需要优化另一方面。这种情况下,你需要清晰地了解这些变化,并确保团队中的每个人都明白目标已经发生了变化。2. 选择一个正确的优化指标选择正确的指标,是优化的一个重要组成部分,你需要按照这些指标来测量优化工作的进展情况。如果指标选择不恰当,或者完全错误,你所做的努力有可能白费了。即使指标正确,也必须有一些辨别。在某些情况下,将最多的努力投入到运行消耗时间最多的那部分代码中,这是实用的策略。但也要记住,Unix/Linux内核的大部分时间花费在了空循环上。需要注意的是,如果你轻易选择了一个很容易达到的指标,这作用不大,因为没有真正解决问题。你有必要选择一个更复杂的、更接近你的目标的指标。3. 优化在刀刃上这是有效优化的关键。找到项目中与你的目标(性能、资源或其他)相背的地方,并将你的努力和时间用在那里。举一个典型的例子,一个Web项目速度比较慢,开发者在优化时将大部分精力放在了数据库优化上,最终发现真正的问题是网络连接慢。另外,不要分心于容易实现的问题。这些问题尽管很容易解决,但可能不是必要的,或与你的目标不相符。容易优化并不意味着值得你花费工夫。4. 优化层次越高越好在一般情况下,优化的层次越高,就会越有效。根据这个标准,最好的优化是找到一个更有效的算法。举个例子,在一个软件开发项目中,有一个重要的应用程序性能较差,于是开发团队开始着手优化,但性能并没有提升太多,之后,项目人员交替,新的开发人员在检查代码时发现,性能问题的核心是由于在表中使用了冒泡排序算法,导致成千上万项的增加。尽管如此,高层次的优化也不是“银弹”。一些基本技术,如将所有东西移到循环语句外,也可以产生一些优化的效果。通常情况下,大量低层次的优化可以产生等同于一个高层次优化的效果。还需要注意的是,高层次优化,会减少一些代码块,那么你之前对这些代码块所做的优化就没有任何意义了,因此,刚开始就应该考虑高层次的优化。5. 不要过早优化在项目早期就进行优化,会导致你的代码难以阅读,或者会影响运行。另一方面,在项目后期,你可能会发现之前所做的优化没有起到任何作用,白白浪费了时间和精力。正确的方式是,你应该将项目开发和优化当作两个独立的步骤来做。6. 依赖性能分析,而不是直觉你往往会认为你已经知道哪里需要优化,这是不可取的,尤其是在复杂的软件系统中,性能分析数据应该是第一位的,最后才是直觉。优化的一个有效的策略是,你要根据所做工作对优化效果的影响来进行排序。在开始工作之前找到影响最大的“路障”,然后再处理小的“路障”。7. 优化不是万金油优化最重要的规则之一是,你无法优化一切,甚至无法同时优化两个问题。比如,优化了速度,可能会增加资源利用;优化了存储的利用率,可能会使其他地方放慢。你需要权衡一下,哪个更符合你的优化目标。
为什么过早的优化是万恶之源? 为什么过早的优化是万恶之源?缘起Donald Knuth(高德纳) 是一位计算机科学界的著名学者和计算机程序设计的先驱之一。他被誉为 计算机科学的“圣经”《计算机程序设计艺术》的作者 ,提出了著名的“大O符号”来描述算法的时间复杂度和空间复杂度,开发了TeX系统用于排版科技文献,获得过图灵奖、冯·诺伊曼奖、美国国家科学奖章等多项荣誉。今天要说的就是他所提出的一条 软件设计重要原则 Premature optimization is the root of all evil 过早优化是万恶之源。 为什么说“过早优化是万恶之源”?我认为过早优化代码会让人陷入到错误的目标中去,从而忽视掉了最重要的目标。举个很简单的例子, 你需要快速构建一个产品来抢占用户,你当下最重要的目标是让这个产品快速上线 ,而不是把这个产品打造的好用(在中国互联网下,这样的事数不胜数), 如果你只关注到后者体验、性能问题而忽视了速度,在当下高度竞争的市场之下,你根本毫无机会。 当然上面这个例子是从感性的层面说的,对很多程序猿来说也可能涉及不到产品层面的内容。我们从软件设计的层面,理性的来说,过早优化可能会导致以下的一些问题:1. 增加代码的复杂性 :过度优化可能会导致代码的复杂性增加,从而降低代码的可读性和可维护性。如果代码过于复杂,可能会导致开发人员难以理解和维护代码,从而增加开发成本和时间。 2. 耗费开发时间和资源 :过度优化可能会导致开发人员花费大量时间和资源在代码的性能优化上,而忽略了其他重要的开发任务。这可能会导致项目进度延误和开发成本增加。 3. 降低代码的可移植性 :过度优化可能会导致代码的可移植性降低。如果代码过于依赖于特定的硬件或操作系统,可能会导致代码无法在其他环境中运行。 4. 降低代码的可扩展性 :过度优化可能会降低代码的可扩展性。如果代码过于依赖于特定的算法或数据结构,可能会导致代码无法适应未来的需求变化。过早优化的典型案例在软件工程史上由于过度关注软件性能导致项目最终失败的案例比比皆是,比如我下面要说的一些项目,在软件工程史上都是非常知名的项目(当然可能有些新生代程序员已经不知道了)。1. IBM OS/360操作系统 :在20世纪60年代,IBM公司开发了OS/360操作系统,这是当时最大的软件工程项目之一。在开发过程中,IBM公司过于关注代码的性能问题,导致代码的复杂性增加,开发时间延误,最终导致项目的失败。我知晓这个项目还是在我最近在阅读的一本软件工程经典书籍《人月神话》中,也推荐大家阅读下,这个项目虽然最终失败了,但也给整个软件工程领域留下了宝贵的经验。 2. Netscape Navigator浏览器 :在20世纪90年代,Netscape公司开发了Navigator浏览器,这是当时最流行的浏览器之一。在开发过程中,Netscape公司过于关注代码的性能问题,导致代码的复杂性增加,开发时间延误,最终导致浏览器市场份额严重下降。 3. Windows Vista操作系统 :在21世纪初,微软公司开发了Windows Vista操作系统,这是当时最大的软件工程项目之一。在开发过程中,微软公司过于关注代码的性能问题,导致代码的复杂性增加,开发时间延误,最终导致操作系统的用户体验不佳,市场反响不佳。话说这个操作系统我还用过呢,用户界面还是很漂亮的,很多UI设计也被沿用到了Window7中。如何识别过早优化在软件开发过程中,如何判断是否过早优化呢?这里有一些概括性的判断标准,可以简单参考下:1. 是否存在性能问题: 如果代码还没有性能问题,那么过早优化就是不必要的。因此,在进行优化之前,应该先测试代码的性能,确定是否存在性能问题。 2. 是否优化了未来可能发生的问题 :如果优化的是未来可能发生的问题,而不是当前存在的问题,那么就可能是过早优化。在进行优化之前,应该优先考虑当前存在的问题,而不是未来可能发生的问题。 3. 是否牺牲了代码的可读性和可维护性 :如果优化代码会导致代码的复杂性增加,降低代码的可读性和可维护性,那么就可能是过早优化。在进行优化之前,应该优先考虑代码的可读性、可维护性和可扩展性。 4. 是否浪费了大量的开发时间和资源 :如果优化代码会浪费大量的开发时间和资源,而不是提高代码的性能和效率,那么就可能是过早优化。在进行优化之前,应该评估优化的成本和收益,确定是否值得进行优化。判断是否过早优化需要根据具体情况进行评估。 在进行优化之前,应该先测试代码的性能,确定是否存在性能问题。同时,也应该优先考虑代码的可读性、可维护性和可扩展性,避免过度优化。总结作为一名在IT领域摸爬滚打多年的工程师,我深有体会地认识到过早优化是软件开发中的一大陷阱。在软件开发的初期,我们可能会过于关注代码的性能问题,而忽略了代码的可读性、可维护性和可扩展性。这种做法可能会导致代码的复杂性增加,降低代码的可读性和可维护性,甚至可能会浪费大量的开发时间和资源。在软件开发过程中,我们应该避免过早优化,而是优先考虑代码的可读性、可维护性和可扩展性。当需要进行性能优化时,应该在代码的基础上进行优化,通过分析性能瓶颈、优化算法和数据结构等方法来提高代码的性能和效率。同时,我们也应该意识到, 性能优化并不是软件开发的唯一目标,我们还应该注重代码的可读性、可维护性和可扩展性,以便保证代码的质量和可靠性。拓展代码优化的好处多多,但是这并不意味着所有的代码都需要进行优化,有时过度的优化反而适得其反——费时、费力、不讨好。“现代计算机科学的鼻祖”Donald Knuth曾说过“过早的优化是万恶之源”,因为:让正确的程序更快,要比让快速的程序正确容易得多。在项目开发中,总是有程序员浪费宝贵的时间去改进那些不需要改进的代码,而没有通过所做的改进增加价值。在对项目进行优化时,究竟哪些地方应该优化,应该如何优化,哪些不应该优化呢?你需要先来了解一下本文所说的这7件事。1. 究竟要优化什么?在优化工作开始的时候,你还尚未明确优化内容和目的,那么你很容易陷入误区。在一开始,你就应该清楚地了解你要达到的效果,以及其他优化相关的各种问题。这些目标需要明确指出(至少精通技术的项目经理可以理解和表达它),接下来,在整个优化过程中,你需要坚持这些目标。在实际的项目开发中,经常会存在各种各样的变数。可能一开始时要优化这一方面,随后你可能会发现需要优化另一方面。这种情况下,你需要清晰地了解这些变化,并确保团队中的每个人都明白目标已经发生了变化。2. 选择一个正确的优化指标选择正确的指标,是优化的一个重要组成部分,你需要按照这些指标来测量优化工作的进展情况。如果指标选择不恰当,或者完全错误,你所做的努力有可能白费了。即使指标正确,也必须有一些辨别。在某些情况下,将最多的努力投入到运行消耗时间最多的那部分代码中,这是实用的策略。但也要记住,Unix/Linux内核的大部分时间花费在了空循环上。需要注意的是,如果你轻易选择了一个很容易达到的指标,这作用不大,因为没有真正解决问题。你有必要选择一个更复杂的、更接近你的目标的指标。3. 优化在刀刃上这是有效优化的关键。找到项目中与你的目标(性能、资源或其他)相背的地方,并将你的努力和时间用在那里。举一个典型的例子,一个Web项目速度比较慢,开发者在优化时将大部分精力放在了数据库优化上,最终发现真正的问题是网络连接慢。另外,不要分心于容易实现的问题。这些问题尽管很容易解决,但可能不是必要的,或与你的目标不相符。容易优化并不意味着值得你花费工夫。4. 优化层次越高越好在一般情况下,优化的层次越高,就会越有效。根据这个标准,最好的优化是找到一个更有效的算法。举个例子,在一个软件开发项目中,有一个重要的应用程序性能较差,于是开发团队开始着手优化,但性能并没有提升太多,之后,项目人员交替,新的开发人员在检查代码时发现,性能问题的核心是由于在表中使用了冒泡排序算法,导致成千上万项的增加。尽管如此,高层次的优化也不是“银弹”。一些基本技术,如将所有东西移到循环语句外,也可以产生一些优化的效果。通常情况下,大量低层次的优化可以产生等同于一个高层次优化的效果。还需要注意的是,高层次优化,会减少一些代码块,那么你之前对这些代码块所做的优化就没有任何意义了,因此,刚开始就应该考虑高层次的优化。5. 不要过早优化在项目早期就进行优化,会导致你的代码难以阅读,或者会影响运行。另一方面,在项目后期,你可能会发现之前所做的优化没有起到任何作用,白白浪费了时间和精力。正确的方式是,你应该将项目开发和优化当作两个独立的步骤来做。6. 依赖性能分析,而不是直觉你往往会认为你已经知道哪里需要优化,这是不可取的,尤其是在复杂的软件系统中,性能分析数据应该是第一位的,最后才是直觉。优化的一个有效的策略是,你要根据所做工作对优化效果的影响来进行排序。在开始工作之前找到影响最大的“路障”,然后再处理小的“路障”。7. 优化不是万金油优化最重要的规则之一是,你无法优化一切,甚至无法同时优化两个问题。比如,优化了速度,可能会增加资源利用;优化了存储的利用率,可能会使其他地方放慢。你需要权衡一下,哪个更符合你的优化目标。 -
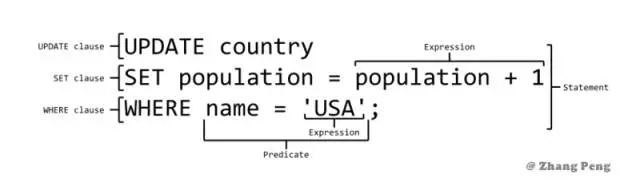
SQL 语法速成手册 SQL 语法速成手册一、基本概念数据库术语数据库(database) - 保存有组织的数据的容器(通常是一个文件或一组文件)。数据表(table) - 某种特定类型数据的结构化清单。模式(schema) - 关于数据库和表的布局及特性的信息。模式定义了数据在表中如何存储,包含存储什么样的数据,数据如何分解,各部分信息如何命名等信息。数据库和表都有模式。列(column) - 表中的一个字段。所有表都是由一个或多个列组成的。行(row) - 表中的一个记录。主键(primary key) - 一列(或一组列),其值能够唯一标识表中每一行。SQL 语法SQL(Structured Query Language),标准 SQL 由 ANSI 标准委员会管理,从而称为 ANSI SQL。各个 DBMS 都有自己的实现,如 PL/SQL、Transact-SQL 等。SQL 语法结构SQL 语法结构包括:子句 - 是语句和查询的组成成分。(在某些情况下,这些都是可选的。)表达式 - 可以产生任何标量值,或由列和行的数据库表谓词 - 给需要评估的 SQL 三值逻辑(3VL)(true/false/unknown)或布尔真值指定条件,并限制语句和查询的效果,或改变程序流程。查询 - 基于特定条件检索数据。这是 SQL 的一个重要组成部分。语句 - 可以持久地影响纲要和数据,也可以控制数据库事务、程序流程、连接、会话或诊断。SQL 语法要点SQL 语句不区分大小写 ,但是数据库表名、列名和值是否区分,依赖于具体的 DBMS 以及配置。例如:SELECT 与 select 、Select 是相同的。多条 SQL 语句必须以分号(;)分隔 。处理 SQL 语句时, 所有空格都被忽略 。SQL 语句可以写成一行,也可以分写为多行。-- 一行 SQL 语句 UPDATE user SET username='robot', password='robot' WHERE username = 'root'; -- 多行 SQL 语句 UPDATE user SET username='robot', password='robot' WHERE username = 'root';SQL 支持三种注释## 注释1 -- 注释2 /* 注释3 */SQL 分类数据定义语言(DDL)数据定义语言(Data Definition Language,DDL)是 SQL 语言集中负责数据结构定义与数据库对象定义的语言。DDL 的主要功能是 定义数据库对象。 DDL 的核心指令是 CREATE、ALTER、DROP。数据操纵语言(DML)数据操纵语言(Data Manipulation Language, DML)是用于数据库操作,对数据库其中的对象和数据运行访问工作的编程语句。DML 的主要功能是 访问数据,因此其语法都是以读写数据库为主。 DML 的核心指令是 INSERT、UPDATE、DELETE、SELECT。这四个指令合称 CRUD(Create, Read, Update, Delete),即增删改查。事务控制语言(TCL)事务控制语言 (Transaction Control Language, TCL) 用于 管理数据库中的事务 。这些用于管理由 DML 语句所做的更改。它还允许将语句分组为逻辑事务。TCL 的核心指令是 COMMIT、ROLLBACK 。数据控制语言(DCL)数据控制语言 (Data Control Language, DCL) 是一种可 对数据访问权进行控制的指令,它可以控制特定用户账户对数据表、查看表、预存程序、用户自定义函数等数据库对象的控制权。 DCL 的核心指令是 GRANT、REVOKE。DCL 以控制用户的访问权限为主,因此其指令作法并不复杂,可利用 DCL 控制的权限有: CONNECT、SELECT、INSERT、UPDATE、DELETE、EXECUTE、USAGE、REFERENCES。 根据不同的 DBMS 以及不同的安全性实体,其支持的权限控制也有所不同。二、增删改查(以下为 DML 语句用法)增删改查,又称为 CRUD,数据库基本操作中的基本操作。插入数据INSERT INTO 语句用于向表中插入新记录。插入完整的行INSERT INTO user VALUES (10, 'root', 'root', 'xxxx@163.com');插入行的一部分INSERT INTO user(username, password, email) VALUES ('admin', 'admin', 'xxxx@163.com');插入查询出来的数据INSERT INTO user(username) SELECT name FROM account;更新数据UPDATE 语句用于更新表中的记录。UPDATE user SET username='robot', password='robot' WHERE username = 'root';删除数据DELETE 语句用于删除表中的记录。 TRUNCATE TABLE 可以清空表,也就是删除所有行。删除表中的指定数据DELETE FROM user WHERE username = 'robot';清空表中的数据TRUNCATE TABLE user;查询数据SELECT 语句用于从数据库中查询数据。DISTINCT 用于返回唯一不同的值。它作用于所有列,也就是说所有列的值都相同才算相同。LIMIT 限制返回的行数。可以有两个参数,第一个参数为起始行,从 0 开始;第二个参数为返回的总行数。ASC :升序(默认)DESC :降序查询单列SELECT prod_name FROM products;查询多列SELECT prod_id, prod_name, prod_price FROM products;查询所有列ELECT * FROM products;查询不同的值SELECT DISTINCT vend_id FROM products;限制查询结果-- 返回前 5 行 SELECT * FROM mytable LIMIT 5; SELECT * FROM mytable LIMIT 0, 5; -- 返回第 3 ~ 5 行 SELECT * FROM mytable LIMIT 2, 3;三、子查询子查询是 嵌套在较大查询中的 SQL 查询。子查询也称为内部查询或内部选择,而包含子查询的语句也称为外部查询或外部选择。子查询可以嵌套在 SELECT,INSERT,UPDATE 或 DELETE 语句内或另一个子查询中。子查询通常会在另一个 SELECT 语句的 WHERE 子句中添加。您可以使用比较运算符,如 >,<,或 =。比较运算符也可以是多行运算符,如 IN,ANY 或 ALL。子查询必须被圆括号 () 括起来。内部查询首先在其父查询之前执行,以便可以将内部查询的结果传递给外部查询。执行过程可以参考下图:子查询的子查询SELECT cust_name, cust_contact FROM customers WHERE cust_id IN (SELECT cust_id FROM orders WHERE order_num IN ( SELECT order_num FROM orderitems WHERE prod_id = 'RGAN01' ) );WHEREWHERE 子句用于过滤记录,即缩小访问数据的范围。WHERE 后跟一个返回 true 或 false 的条件。WHERE 可以与 SELECT,UPDATE 和 DELETE 一起使用。可以在 WHERE 子句中使用的操作符SELECT 语句中的 WHERE 子句SELECT * FROM Customers WHERE cust_name = 'Kids Place';UPDATE 语句中的 WHERE 子句UPDATE Customers SET cust_name = 'Jack Jones' WHERE cust_name = 'Kids Place';DELETE 语句中的 WHERE 子句DELETE FROM Customers WHERE cust_name = 'Kids Place';IN 和 BETWEENIN 操作符在 WHERE 子句中使用,作用是在指定的几个特定值中任选一个值。BETWEEN 操作符在 WHERE 子句中使用,作用是选取介于某个范围内的值。IN 示例SELECT * FROM products WHERE vend_id IN ('DLL01', 'BRS01');BETWEEN 示例SELECT * FROM products WHERE prod_price BETWEEN 3 AND 5;AND、OR、NOTAND、OR、NOT 是用于对过滤条件的逻辑处理指令。AND 优先级高于 OR,为了明确处理顺序,可以使用 ()。AND 操作符表示左右条件都要满足。OR 操作符表示左右条件满足任意一个即可。NOT 操作符用于否定一个条件。AND 示例SELECT prod_id, prod_name, prod_price FROM products WHERE vend_id = 'DLL01' AND prod_price <= 4;OR 示例SELECT prod_id, prod_name, prod_priceFROM productsWHERE vend_id = 'DLL01' OR vend_id = 'BRS01';NOT 示例SELECT * FROM products WHERE prod_price NOT BETWEEN 3 AND 5;LIKELIKE 操作符在 WHERE 子句中使用,作用是确定字符串是否匹配模式。只有字段是文本值时才使用 LIKE。LIKE 支持两个通配符匹配选项:% 和 _。不要滥用通配符,通配符位于开头处匹配会非常慢。% 表示任何字符出现任意次数。_ 表示任何字符出现一次。拓展:mysql使用like% 示例SELECT prod_id, prod_name, prod_price FROM products WHERE prod_name LIKE '%bean bag%';_ 示例SELECT prod_id, prod_name, prod_price FROM products WHERE prod_name LIKE '__ inch teddy bear';四、连接和组合连接(JOIN)如果一个 JOIN 至少有一个公共字段并且它们之间存在关系,则该 JOIN 可以在两个或多个表上工作。连接用于连接多个表,使用 JOIN 关键字,并且条件语句使用 ON 而不是 WHERE。JOIN 保持基表(结构和数据)不变。JOIN 有两种连接类型:内连接和外连接内连接又称等值连接,使用 INNER JOIN 关键字。在没有条件语句的情况下返回笛卡尔积。自连接可以看成内连接的一种,只是连接的表是自身而已。自然连接是把同名列通过 = 测试连接起来的,同名列可以有多个。内连接 vs 自然连接内连接提供连接的列,而自然连接自动连接所有同名列。外连接返回一个表中的所有行,并且仅返回来自次表中满足连接条件的那些行,即两个表中的列是相等的。外连接分为左外连接、右外连接、全外连接(Mysql 不支持)。左外连接就是保留左表没有关联的行。右外连接就是保留右表没有关联的行。连接 vs 子查询连接可以替换子查询,并且比子查询的效率一般会更快。内连接(INNER JOIN)SELECT vend_name, prod_name, prod_price FROM vendors INNER JOIN products ON vendors.vend_id = products.vend_id;自连接select st2.name, st2.grade from new_student st1, new_student st2 where st1.name='小明' and st1.grade < st2.grade;SQL中 JOIN 的两种连接类型 - 自连接自然连接(NATURAL JOIN)SELECT * FROM Products NATURAL JOIN Customers;左连接(LEFT JOIN)SELECT customers.cust_id, orders.order_num FROM customers LEFT JOIN orders ON customers.cust_id = orders.cust_id;右连接(RIGHT JOIN)SELECT customers.cust_id, orders.order_num FROM customers RIGHT JOIN orders ON customers.cust_id = orders.cust_id;组合(UNION)UNION 运算符将两个或更多查询的结果组合起来,并生成一个结果集,其中包含来自 UNION 中参与查询的提取行。UNION 基本规则所有查询的列数和列顺序必须相同。每个查询中涉及表的列的数据类型必须相同或兼容。通常返回的列名取自第一个查询。默认会去除相同行,如果需要保留相同行,使用 UNION ALL。只能包含一个 ORDER BY 子句,并且必须位于语句的最后。应用场景在一个查询中从不同的表返回结构数据。对一个表执行多个查询,按一个查询返回数据。组合查询SELECT cust_name, cust_contact, cust_email FROM customers WHERE cust_state IN ('IL', 'IN', 'MI') UNION SELECT cust_name, cust_contact, cust_email FROM customers WHERE cust_name = 'Fun4All';JOIN vs UNIONJOIN 中连接表的列可能不同,但在 UNION 中,所有查询的列数和列顺序必须相同。UNION 将查询之后的行放在一起(垂直放置),但 JOIN 将查询之后的列放在一起(水平放置),即它构成一个笛卡尔积。五、函数拓展:mysql文本处理🔔 注意:不同数据库的函数往往各不相同,因此不可移植。本节主要以 Mysql 的函数为例。其中, SOUNDEX() 可以将一个字符串转换为描述其语音表示的字母数字模式。SELECT * FROM mytable WHERE SOUNDEX(col1) = SOUNDEX('apple')日期和时间处理日期格式:YYYY-MM-DD时间格式:HH:MM:SSmysql> SELECT NOW(); 2018-4-14 20:25:11AVG() 会忽略 NULL 行。使用 DISTINCT 可以让汇总函数值汇总不同的值。SELECT AVG(DISTINCT col1) AS avg_colFROM mytable六、排序和分组ORDER BYORDER BY 用于对结果集进行排序。ASC :升序(默认)DESC :降序可以按多个列进行排序,并且为每个列指定不同的排序方式 指定多个列的排序方向SELECT * FROM products ORDER BY prod_price DESC, prod_name ASC; GROUP BY GROUP BY 子句将记录分组到汇总行中。 GROUP BY 为每个组返回一个记录。 GROUP BY 通常还涉及聚合:COUNT,MAX,SUM,AVG 等。 GROUP BY 可以按一列或多列进行分组。 GROUP BY 按分组字段进行排序后,ORDER BY 可以以汇总字段来进行排序。分组SELECT cust_name, COUNT(cust_address) AS addr_num FROM Customers GROUP BY cust_name;分组后排序SELECT cust_name, COUNT(cust_address) AS addr_num FROM Customers GROUP BY cust_name ORDER BY cust_name DESC;HAVINGHAVING 用于对汇总的 GROUP BY 结果进行过滤。HAVING 要求存在一个 GROUP BY 子句。WHERE 和 HAVING 可以在相同的查询中。HAVING vs WHEREWHERE 和 HAVING 都是用于过滤。HAVING 适用于汇总的组记录;而 WHERE 适用于单个记录。使用 WHERE 和 HAVING 过滤数据SELECT cust_name, COUNT(*) AS num FROM Customers WHERE cust_email IS NOT NULL GROUP BY cust_name HAVING COUNT(*) >= 1;七、数据定义(以下为 DDL 语句用法)DDL 的主要功能是定义数据库对象(如:数据库、数据表、视图、索引等)。数据库(DATABASE)创建数据库CREATE DATABASE test;删除数据库DROP DATABASE test;选择数据库USE test;数据表(TABLE)创建数据表普通创建CREATE TABLE user ( id int(10) unsigned NOT NULL COMMENT 'Id', username varchar(64) NOT NULL DEFAULT 'default' COMMENT '用户名', password varchar(64) NOT NULL DEFAULT 'default' COMMENT '密码', email varchar(64) NOT NULL DEFAULT 'default' COMMENT '邮箱') COMMENT='用户表';根据已有的表创建新表CREATE TABLE vip_user AS SELECT * FROM user;删除数据表DROP TABLE user;修改数据表添加列ALTER TABLE user ADD age int(3);删除列ALTER TABLE user DROP COLUMN age;修改列ALTER TABLE `user` MODIFY COLUMN age tinyint;添加主键ALTER TABLE user ADD PRIMARY KEY (id);删除主键ALTER TABLE user DROP PRIMARY KEY;视图(VIEW)MySQL高级篇之View视图定义视图是基于 SQL 语句的结果集的可视化的表。视图是虚拟的表,本身不包含数据,也就不能对其进行索引操作。对视图的操作和对普通表的操作一样。作用简化复杂的 SQL 操作,比如复杂的联结;只使用实际表的一部分数据;通过只给用户访问视图的权限,保证数据的安全性;更改数据格式和表示。创建视图CREATE VIEW top_10_user_view AS SELECT id, username FROM user WHERE id < 10;删除视图DROP VIEW top_10_user_view;索引(INDEX)作用通过索引可以更加快速高效地查询数据。用户无法看到索引,它们只能被用来加速查询。注意更新一个包含索引的表需要比更新一个没有索引的表花费更多的时间,这是由于索引本身也需要更新。因此,理想的做法是仅仅在常常被搜索的列(以及表)上面创建索引。唯一索引唯一索引表明此索引的每一个索引值只对应唯一的数据记录。创建索引CREATE INDEX user_indexON user (id);创建唯一索引CREATE UNIQUE INDEX user_indexON user (id);删除索引ALTER TABLE userDROP INDEX user_index;约束SQL 约束用于规定表中的数据规则。如果存在违反约束的数据行为,行为会被约束终止。约束可以在创建表时规定(通过 CREATE TABLE 语句),或者在表创建之后规定(通过 ALTER TABLE 语句)。约束类型NOT NULL - 指示某列不能存储 NULL 值。UNIQUE - 保证某列的每行必须有唯一的值。PRIMARY KEY - NOT NULL 和 UNIQUE 的结合。确保某列(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录。FOREIGN KEY - 保证一个表中的数据匹配另一个表中的值的参照完整性。CHECK - 保证列中的值符合指定的条件。DEFAULT - 规定没有给列赋值时的默认值。创建表时使用约束条件:CREATE TABLE Users ( Id INT(10) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '自增Id', Username VARCHAR(64) NOT NULL UNIQUE DEFAULT 'default' COMMENT '用户名', Password VARCHAR(64) NOT NULL DEFAULT 'default' COMMENT '密码', Email VARCHAR(64) NOT NULL DEFAULT 'default' COMMENT '邮箱地址', Enabled TINYINT(4) DEFAULT NULL COMMENT '是否有效', PRIMARY KEY (Id)) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8mb4 COMMENT='用户表';八、事务处理(以下为 TCL 语句用法)不能回退 SELECT 语句,回退 SELECT 语句也没意义;也不能回退 CREATE 和 DROP 语句。MySQL 默认是隐式提交,每执行一条语句就把这条语句当成一个事务然后进行提交。当出现 START TRANSACTION 语句时,会关闭隐式提交;当 COMMIT 或 ROLLBACK 语句执行后,事务会自动关闭,重新恢复隐式提交。通过 set autocommit=0 可以取消自动提交,直到 set autocommit=1 才会提交;autocommit 标记是针对每个连接而不是针对服务器的。指令START TRANSACTION - 指令用于标记事务的起始点。SAVEPOINT - 指令用于创建保留点。ROLLBACK TO - 指令用于回滚到指定的保留点;如果没有设置保留点,则回退到 START TRANSACTION 语句处。COMMIT - 提交事务。-- 开始事务START TRANSACTION;-- 插入操作 A START TRANSACTION; -- 插入操作 AINSERT INTO `user` VALUES (1, 'root1', 'root1', 'xxxx@163.com'); -- 创建保留点 updateA SAVEPOINT updateA; -- 插入操作 B INSERT INTO `user` VALUES (2, 'root2', 'root2', 'xxxx@163.com'); -- 回滚到保留点 updateA ROLLBACK TO updateA; -- 提交事务,只有操作 A 生效 COMMIT;九、权限控制(以下为 DCL 语句用法)GRANT 和 REVOKE 可在几个层次上控制访问权限:整个服务器,使用 GRANT ALL 和 REVOKE ALL;整个数据库,使用 ON database.*;特定的表,使用 ON database.table;特定的列;特定的存储过程。新创建的账户没有任何权限。账户用 username@host 的形式定义,username@% 使用的是默认主机名。MySQL 的账户信息保存在 mysql 这个数据库中。USE mysql;SELECT user FROM user;创建账户CREATE USER myuser IDENTIFIED BY 'mypassword';修改账户名UPDATE user SET user='newuser' WHERE user='myuser'; FLUSH PRIVILEGES;删除账户DROP USER myuser;查看权限SHOW GRANTS FOR myuser;授予权限GRANT SELECT, INSERT ON *.* TO myuser;删除权限REVOKE SELECT, INSERT ON *.* FROM myuser;更改密码SET PASSWORD FOR myuser = 'mypass';十、存储过程存储过程可以看成是对一系列 SQL 操作的批处理;使用存储过程的好处代码封装,保证了一定的安全性;代码复用;由于是预先编译,因此具有很高的性能。创建存储过程命令行中创建存储过程需要自定义分隔符,因为命令行是以 ; 为结束符,而存储过程中也包含了分号,因此会错误把这部分分号当成是结束符,造成语法错误。包含 in、out 和 inout 三种参数。给变量赋值都需要用 select into 语句。每次只能给一个变量赋值,不支持集合的操作。创建存储过程DROP PROCEDURE IF EXISTS `proc_adder`; DELIMITER ;; CREATE DEFINER=`root`@`localhost` PROCEDURE `proc_adder`(IN a int, IN b int, OUT sum int) BEGIN DECLARE c int; if a is null then set a = 0; end if; if b is null then set b = 0; end if; set sum = a + b; END; DELIMITER;使用存储过程set @b=5; call proc_adder(2,@b,@s); select @s as sum;十一、游标游标(cursor)是一个存储在 DBMS 服务器上的数据库查询,它不是一条 SELECT 语句,而是被该语句检索出来的结果集。在存储过程中使用游标可以对一个结果集进行移动遍历。游标主要用于交互式应用,其中用户需要对数据集中的任意行进行浏览和修改。使用游标的四个步骤:声明游标,这个过程没有实际检索出数据;打开游标;取出数据;关闭游标;DELIMITER $ CREATE PROCEDURE getTotal() BEGIN DECLARE total INT; -- 创建接收游标数据的变量 DECLARE sid INT; DECLARE sname VARCHAR(10); -- 创建总数变量 DECLARE sage INT; -- 创建结束标志变量 DECLARE done INT DEFAULT false; -- 创建游标 DECLARE cur CURSOR FOR SELECT id,name,age from cursor_table where age>30; -- 指定游标循环结束时的返回值 DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = true; SET total = 0; OPEN cur; FETCH cur INTO sid, sname, sage; WHILE(NOT done) DO SET total = total + 1; FETCH cur INTO sid, sname, sage; END WHILE; CLOSE cur; SELECT total; END $ DELIMITER ; -- 调用存储过程 call getTotal();十二、触发器触发器是一种与表操作有关的数据库对象,当触发器所在表上出现指定事件时,将调用该对象,即表的操作事件触发表上的触发器的执行。可以使用触发器来进行审计跟踪,把修改记录到另外一张表中。MySQL 不允许在触发器中使用 CALL 语句 ,也就是不能调用存储过程。BEGIN 和 END当触发器的触发条件满足时,将会执行 BEGIN 和 END 之间的触发器执行动作。🔔 注意:在 MySQL 中,分号 ; 是语句结束的标识符,遇到分号表示该段语句已经结束,MySQL 可以开始执行了。因此,解释器遇到触发器执行动作中的分号后就开始执行,然后会报错,因为没有找到和 BEGIN 匹配的 END。这时就会用到 DELIMITER 命令(DELIMITER 是定界符,分隔符的意思)。它是一条命令,不需要语句结束标识,语法为:DELIMITER new_delemiter。new_delemiter 可以设为 1 个或多个长度的符号,默认的是分号 ;,我们可以把它修改为其他符号,如 $ - DELIMITER $ 。在这之后的语句,以分号结束,解释器不会有什么反应,只有遇到了 $,才认为是语句结束。注意,使用完之后,我们还应该记得把它给修改回来。NEW 和 OLDMySQL 中定义了 NEW 和 OLD 关键字,用来表示触发器的所在表中,触发了触发器的那一行数据。在 INSERT 型触发器中,NEW 用来表示将要(BEFORE)或已经(AFTER)插入的新数据;在 UPDATE 型触发器中,OLD 用来表示将要或已经被修改的原数据,NEW 用来表示将要或已经修改为的新数据;在 DELETE 型触发器中,OLD 用来表示将要或已经被删除的原数据;使用方法: NEW.columnName (columnName 为相应数据表某一列名)创建触发器提示:为了理解触发器的要点,有必要先了解一下创建触发器的指令。CREATE TRIGGER 指令用于创建触发器。语法:CREATE TRIGGER trigger_name trigger_time trigger_event ON table_name FOR EACH ROW BEGIN trigger_statements END;说明:trigger_name:触发器名trigger_time: 触发器的触发时机。取值为 BEFORE 或 AFTER。trigger_event: 触发器的监听事件。取值为 INSERT、UPDATE 或 DELETE。table_name: 触发器的监听目标。指定在哪张表上建立触发器。FOR EACH ROW: 行级监视,Mysql 固定写法,其他 DBMS 不同。trigger_statements: 触发器执行动作。是一条或多条 SQL 语句的列表,列表内的每条语句都必须用分号 ; 来结尾。示例:DELIMITER $ CREATE TRIGGER `trigger_insert_user` AFTER INSERT ON `user` FOR EACH ROW BEGIN INSERT INTO `user_history`(user_id, operate_type, operate_time) VALUES (NEW.id, 'add a user', now()); END $ DELIMITER ;查看触发器SHOW TRIGGERS;删除触发器DROP TRIGGER IF EXISTS trigger_insert_user;
-
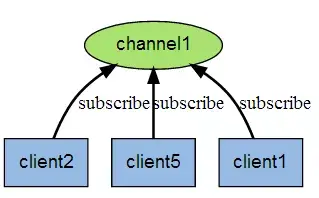
Redis简易入门15招 Redis简易入门15招1、Redis简介REmote DIctionary Server(Redis) 是一个由 Salvatore Sanfilippo写的key-value存储系统 。Redis是一个开源的使用ANSI C语言编写、遵守BSD协议、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。它通常被称为 数据结构服务器 ,因为值(value)可以是 字符串(String), 哈希(Map), 列表(list), 集合(sets) 和 有序集合(sorted sets)等类型。大家都知道了redis是基于key-value的no sql数据库,因此,先来了解一下关于key相关的知识点1、任何二进制的序列都可以作为key使用2、Redis有统一的规则来设计key3、对key-value允许的最大长度是512MB Redis重大版本整理(Redis2.6-Redis7.0)2、支持的语言ActionScript Bash C C# C++ Clojure Common LispCrystal D Dart Elixir emacs lisp Erlang Fancy gawk GNU Prolog Go Haskell Haxe Io Java Javascript Julia Lua Matlab mruby Nim Node.js Objective-C OCaml Pascal Perl PHP Pure Data Python R Racket Rebol Ruby Rust Scala Scheme Smalltalk Swift Tcl VB VCL3、Redis的应用场景到底有哪些?1、最常用的就是会话缓存2、消息队列,比如支付3、活动排行榜或计数4、发布、订阅消息(消息通知)5、商品列表、评论列表等拓展:Redis 16大应用场景4、Redis安装关于redis安装与相关的知识点介绍请参考 Nosql数据库服务之redis 安装的大概步骤如下: Redis是c语言开发的,安装redis需要c语言的编译环境如果没有gcc需要在线安装:yum install gcc-c++第一步:获取源码包:wget http://download.redis.io/releases/redis-3.0.0.tar.gz第二步:解压缩redis:tar zxvf redis-3.0.0.tar.gz第三步:编译。进入redis源码目录(cd redis-3.0.0)。执行 make第四步:安装。make install PREFIX=/usr/local/redisPREFIX参数指定redis的安装目录5、Redis数据类型Redis常用五种数据类型1、string(字符串)2、hash(哈希)3、list(列表)4、set(集合)5、zset(sorted set 有序集合)拓展:Redis data typesstring(字符串)它是redis最基本的数据类型,一个key对应一个value,需要注意是一个键值最大存储512MB。127.0.0.1:6379> set key "hello world" OK 127.0.0.1:6379> get key "hello world" 127.0.0.1:6379> getset key "nihao" "hello world" 127.0.0.1:6379> mset key1 "hi" key2 "nihao" key3 "hello" OK 127.0.0.1:6379> get key1 "hi" 127.0.0.1:6379> get key2 "nihao" 127.0.0.1:6379> get key3 "hello"相关命令介绍set 为一个Key设置value(值)get 获得某个key对应的value(值)getset 为一个Key设置value(值)并返回对应的值mset 为多个key设置value(值)hash(哈希)redis hash是一个键值对的集合, 是一个string类型的field和value的映射表,适合用于存储对象127.0.0.1:6379> hset redishash 1 "001" (integer) 1 127.0.0.1:6379> hget redishash 1 "001" 127.0.0.1:6379> hmset redishash 1 "001" 2 "002" OK 127.0.0.1:6379> hget redishash 1 "001" 127.0.0.1:6379> hget redishash 2 "002" 127.0.0.1:6379> hmget redishash 1 2 1) "001" 2) "002"相关命令介绍hset 将Key对应的hash中的field配置为value,如果hash不存则自动创建,hget 获得某个hash中的field配置的值hmset 批量配置同一个hash中的多个field值hmget 批量获得同一个hash中的多个field值list(列表)是redis简单的字符串列表,它按插入顺序排序127.0.0.1:6379> lpush word hi (integer) 1 127.0.0.1:6379> lpush word hello (integer) 2 127.0.0.1:6379> rpush word world (integer) 3 127.0.0.1:6379> lrange word 0 2 1) "hello" 2) "hi" 3) "world" 127.0.0.1:6379> llen word (integer) 3相关命令介绍lpush 向指定的列表左侧插入元素,返回插入后列表的长度rpush 向指定的列表右侧插入元素,返回插入后列表的长度llen 返回指定列表的长度lrange 返回指定列表中指定范围的元素值set(集合)是string类型的无序集合,也不可重复127.0.0.1:6379> sadd redis redisset (integer) 1 127.0.0.1:6379> sadd redis redisset1 (integer) 1 127.0.0.1:6379> sadd redis redisset2 (integer) 1 127.0.0.1:6379> smembers redis 1) "redisset1" 2) "redisset" 3) "redisset2" 127.0.0.1:6379> sadd redis redisset2 (integer) 0 127.0.0.1:6379> smembers redis 1) "redisset1" 2) "redisset" 3) "redisset2" 127.0.0.1:6379> smembers redis 1) "redisset1" 2) "redisset3" 3) "redisset" 4) "redisset2" 127.0.0.1:6379> srem redis redisset (integer) 1 127.0.0.1:6379> smembers redis 1) "redisset1" 2) "redisset3" 3) "redisset2"相关命令介绍sadd 添加一个string元素到key对应的set集合中,成功返回1,如果元素存在返回0smembers 返回指定的集合中所有的元素srem 删除指定集合的某个元素拓展:集合(Set)的排序问题zset(sorted set 有序集合)是string类型的有序集合,也不可重复 sorted set中的每个元素都需要指定一个分数,根据分数对元素进行升序排序,如果多个元素有相同的分数,则以字典序进行升序排序, sorted set 因此非常适合实现排名127.0.0.1:6379> zadd nosql 0 001 (integer) 1 127.0.0.1:6379> zadd nosql 0 002 (integer) 1 127.0.0.1:6379> zadd nosql 0 003 (integer) 1 127.0.0.1:6379> zcount nosql 0 0 (integer) 3 127.0.0.1:6379> zcount nosql 0 3 (integer) 3 127.0.0.1:6379> zrem nosql 002 (integer) 1 127.0.0.1:6379> zcount nosql 0 3 (integer) 2 127.0.0.1:6379> zscore nosql 003 "0" 127.0.0.1:6379> zrangebyscore nosql 0 10 1) "001" 2) "003" 127.0.0.1:6379> zadd nosql 1 003 (integer) 0 127.0.0.1:6379> zadd nosql 1 004 (integer) 1 127.0.0.1:6379> zrangebyscore nosql 0 10 1) "001" 2) "003" 3) "004" 127.0.0.1:6379> zadd nosql 3 005 (integer) 1 127.0.0.1:6379> zadd nosql 2 006 (integer) 1 127.0.0.1:6379> zrangebyscore nosql 0 10 1) "001" 2) "003" 3) "004" 4) "006" 5) "005"相关命令介绍zadd 向指定的sorteset中添加1个或多个元素zrem 从指定的sorteset中删除1个或多个元素zcount 查看指定的sorteset中指定分数范围内的元素数量zscore 查看指定的sorteset中指定分数的元素zrangebyscore 查看指定的sorteset中指定分数范围内的所有元素6、键值相关的命令 127.0.0.1:6379> exists key (integer) 1 127.0.0.1:6379> exists key1 (integer) 1 127.0.0.1:6379> exists key100 (integer) 0 127.0.0.1:6379> get key "nihao,hello" 127.0.0.1:6379> get key1 "hi" 127.0.0.1:6379> del key1 (integer) 1 127.0.0.1:6379> get key1 (nil) 127.0.0.1:6379> rename key key0 OK 127.0.0.1:6379> get key(nil) 127.0.0.1:6379> get key0 "nihao,hello" 127.0.0.1:6379> type key0 stringexists #确认key是否存在del #删除keyexpire #设置Key过期时间(单位秒)persist #移除Key过期时间的配置rename #重命名keytype #返回值的类型7、Redis服务相关的命令127.0.0.1:6379> select 0 OK 127.0.0.1:6379> info # Server redis_version:3.0.6 redis_git_sha1:00000000 redis_git_dirty:0 redis_build_id:347e3eeef5029f3 redis_mode:standalone os:Linux 3.10.0-693.el7.x86_64 x86_64 arch_bits:64 multiplexing_api:epoll gcc_version:4.8.5 process_id:31197 run_id:8b6ec6ad5035f5df0b94454e199511084ac6fb12 tcp_port:6379 uptime_in_seconds:8514 uptime_in_days:0 hz:10 lru_clock:14015928 config_file:/usr/local/redis/redis.conf -------------------省略N行 127.0.0.1:6379> CONFIG GET 0 (empty list or set) 127.0.0.1:6379> CONFIG GET 15 (empty list or set)slect #选择数据库(数据库编号0-15)quit #退出连接info #获得服务的信息与统计monitor #实时监控config get #获得服务配置flushdb #删除当前选择的数据库中的keyflushall #删除所有数据库中的key8、Redis的发布与订阅Redis发布与订阅(pub/sub)是它的一种消息通信模式,一方发送信息,一方接收信息。下图是三个客户端同时订阅同一个频道下图是有新信息发送给频道1时,就会将消息发送给订阅它的三个客户端9、Redis事务Redis(非原子性)事务可以一次执行多条命令1、发送exec命令前放入队列缓存,结束事务2、收到exec命令后执行事务操作,如果某一命令执行失败,其它命令仍可继续执行3、一个事务执行的过程中,其它客户端提交的请求不会被插入到事务执行的命令列表中一个事务经历三个阶段开始事务(命令:multi) 命令执行 结束事务(命令:exec)127.0.0.1:6379> MULTI OK 127.0.0.1:6379> set key key1 QUEUED 127.0.0.1:6379> get key QUEUED 127.0.0.1:6379> rename key key001 QUEUED 127.0.0.1:6379> exec 1) OK 2) "key1" 3) OKRedis事务相关命令:MULTI :开启事务,redis会将后续的命令逐个放入队列中,然后使用EXEC命令来原子化执行这个命令系列。EXEC:执行事务中的所有操作命令。DISCARD:取消事务,放弃执行事务块中的所有命令。WATCH:监视一个或多个key,如果事务在执行前,这个key(或多个key)被其他命令修改,则事务被中断,不会执行事务中的任何命令。UNWATCH:取消WATCH对所有key的监视。为什么Redis不支持事务回滚? 多数事务失败是由语法错误或者数据结构类型错误导致的,语法错误说明在命令入队前就进行检测的,而类型错误是在执行时检测的,Redis为提升性能而采用这种简单的事务,这是不同于关系型数据库的。严格的说Redis的命令是原子性的,而事务是非原子性的,我们要让Redis事务完全具有事务回滚的能力,需要借助于命令WATCH来实现。拓展彻底搞懂 Redis 事务10、Redis安全配置可以通过修改配置文件设备密码参数来提高安全性 #requirepass foobared去掉注释#号就可以配置密码 没有配置密码的情况下查询如下127.0.0.1:6379> CONFIG GET requirepass 1) "requirepass" 2) ""配置密码之后,就需要进行认证127.0.0.1:6379> CONFIG GET requirepass (error) NOAUTH Authentication required. 127.0.0.1:6379> AUTH foobared #认证OK 127.0.0.1:6379> CONFIG GET requirepass 1) "requirepass" 2) "foobared"11、Redis持久化Redis持久有两种方式:Snapshotting(快照),Append-only file(AOF)Snapshotting(快照)1、将存储在内存的数据以快照的方式写入二进制文件中,如默认dump.rdb中 2、save 900 1 #900秒内如果超过1个Key被修改,则启动快照保存 3、save 300 10 #300秒内如果超过10个Key被修改,则启动快照保存 4、save 60 10000 #60秒内如果超过10000个Key被修改,则启动快照保存Append-only file(AOF)1、使用AOF持久时,服务会将每个收到的写命令通过write函数追加到文件中(appendonly.aof) 2、AOF持久化存储方式参数说明 appendonly yes #开启AOF持久化存储方式 appendfsync always #收到写命令后就立即写入磁盘,效率最差,效果最好 appendfsync everysec #每秒写入磁盘一次,效率与效果居中 appendfsync no #完全依赖OS,效率最佳,效果没法保证拓展Redis 持久化详解及配置12、Redis 性能测试自带相关测试工具 [root@test ~]# redis-benchmark --help Usage: redis-benchmark [-h <host>] [-p <port>] [-c <clients>] [-n <requests]> [-k <boolean>] -h <hostname> Server hostname (default 127.0.0.1) -p <port> Server port (default 6379) -s <socket> Server socket (overrides host and port) -a <password> Password for Redis Auth -c <clients> Number of parallel connections (default 50) -n <requests> Total number of requests (default 100000) -d <size> Data size of SET/GET value in bytes (default 2) -dbnum <db> SELECT the specified db number (default 0) -k <boolean> 1=keep alive 0=reconnect (default 1) -r <keyspacelen> Use random keys for SET/GET/INCR, random values for SADD Using this option the benchmark will expand the string __rand_int__ inside an argument with a 12 digits number in the specified range from 0 to keyspacelen-1. The substitution changes every time a command is executed. Default tests use this to hit random keys in the specified range. -P <numreq> Pipeline <numreq> requests. Default 1 (no pipeline). -q Quiet. Just show query/sec values --csv Output in CSV format -l Loop. Run the tests forever -t <tests> Only run the comma separated list of tests. The test names are the same as the ones produced as output. -I Idle mode. Just open N idle connections and wait. Examples: Run the benchmark with the default configuration against 127.0.0.1:6379: $ redis-benchmark Use 20 parallel clients, for a total of 100k requests, against 192.168.1.1: $ redis-benchmark -h 192.168.1.1 -p 6379 -n 100000 -c 20 Fill 127.0.0.1:6379 with about 1 million keys only using the SET test: $ redis-benchmark -t set -n 1000000 -r 100000000 Benchmark 127.0.0.1:6379 for a few commands producing CSV output: $ redis-benchmark -t ping,set,get -n 100000 --csv Benchmark a specific command line: $ redis-benchmark -r 10000 -n 10000 eval 'return redis.call("ping")' 0 Fill a list with 10000 random elements: $ redis-benchmark -r 10000 -n 10000 lpush mylist __rand_int__ On user specified command lines __rand_int__ is replaced with a random integer with a range of values selected by the -r option.实际测试同时执行100万的请求[root@test ~]# redis-benchmark -n 1000000 -q PING_INLINE: 152578.58 requests per second PING_BULK: 150308.14 requests per second SET: 143266.47 requests per second GET: 148632.58 requests per second INCR: 145857.64 requests per second LPUSH: 143781.45 requests per second LPOP: 147819.66 requests per second SADD: 138350.86 requests per second SPOP: 134282.27 requests per second LPUSH (needed to benchmark LRANGE): 141302.81 requests per second LRANGE_100 (first 100 elements): 146756.67 requests per second LRANGE_300 (first 300 elements): 148104.27 requests per second LRANGE_500 (first 450 elements): 152671.75 requests per second LRANGE_600 (first 600 elements): 148104.27 requests per second MSET (10 keys): 132731.62 requests per second13、Redis的备份与恢复Redis自动备份有两种方式第一种是通过dump.rdb文件实现备份第二种使用aof文件实现自动备份dump.rdb备份Redis服务 默认的自动文件备份方式(AOF没有开启的情况下) ,在服务启动时,就会自动从 dump.rdb 文件中去加载数据。具体配置在redis.confsave 900 1 save 300 10 save 60 10000也可以手工执行save命令实现手动备份127.0.0.1:6379> set name key OK 127.0.0.1:6379> SAVE OK 127.0.0.1:6379> set name key1 OK 127.0.0.1:6379> BGSAVE Background saving startedredis快照到dump文件时,会自动生成dump.rdb的文件# The filename where to dump the DB dbfilename dump.rdb -rw-r--r-- 1 root root 253 Apr 17 20:17 dump.rdbSAVE 命令表示使用 主进程将当前数据库快照到dump文件BGSAVE 命令表示, 主进程会fork一个子进程来进行快照备份两种备份不同之处,前者会阻塞主进程,后者不会。恢复举例# Note that you must specify a directory here, not a file name.dir /usr/local/redisdata/ #备份文件存储路径 127.0.0.1:6379> CONFIG GET dir 1) "dir" 2) "/usr/local/redisdata" 127.0.0.1:6379> set key 001 OK 127.0.0.1:6379> set key1 002 OK 127.0.0.1:6379> set key2 003 OK 127.0.0.1:6379> save OK将备份文件备份到其它目录[root@test ~]# ll /usr/local/redisdata/ total 4 -rw-r--r-- 1 root root 49 Apr 17 21:24 dump.rdb [root@test ~]# date Tue Apr 17 21:25:38 CST 2018 [root@test ~]# cp ./dump.rdb /tmp/删除数据127.0.0.1:6379> del key1 (integer) 1 127.0.0.1:6379> get key1 (nil)关闭服务,将原备份文件拷贝回save备份目录[root@test ~]# redis-cli -a foobared shutdown [root@test ~]# lsof -i :6379 [root@test ~]# cp /tmp/dump.rdb /usr/local/redisdata/ cp: overwrite ‘/usr/local/redisdata/dump.rdb’? y [root@test ~]# redis-server /usr/local/redis/redis.conf & [1] 31487登录查看数据是否恢复[root@test ~]# redis-cli -a foobared 127.0.0.1:6379> mget key key1 key2 1) "001" 2) "002" 3) "003"AOF自动备份redis服务 默认是关闭此项配置###### APPEND ONLY MODE ########## appendonly no # The name of the append only file (default: "appendonly.aof") appendfilename "appendonly.aof" # appendfsync always appendfsync everysec # appendfsync no配置文件的相关参数,前面已经详细介绍过。AOF文件备份,是备份所有的历史记录以及执行过的命令,和mysql binlog很相似,在恢复时就是重新执次一次之前执行的命令,需要注意的就是在恢复之前,和数据库恢复一样需要手工删除执行过的del或误操作的命令。AOF与dump备份不同1、aof文件备份与dump文件备份不同2、服务读取文件的优先顺序不同,会按照以下优先级进行启动 如果只配置AOF,重启时加载AOF文件恢复数据如果同时 配置了RBD和AOF,启动是只加载AOF文件恢复数据 如果只配置RBD,启动时将加载dump文件恢复数据注意:只要配置了aof,但是没有aof文件,这个时候启动的数据库会是空的14、Redis 生产优化介绍1、内存管理优化 hash-max-ziplist-entries 512 hash-max-ziplist-value 64 list-max-ziplist-entries 512 list-max-ziplist-value 64 #list的成员与值都不太大的时候会采用紧凑格式来存储,相对内存开销也较小在linux环境运行Redis时,如果系统的内存比较小,这个时候自动备份会有可能失败,需要修改系统的vm.overcommit_memory 参数,这个参数是linux系统的内存分配策略0 表示内核将检查是否有足够的可用内存供应用进程使用;如果有足够的可用内存,内存申请允许;否则,内存申请失败,并把错误返回给应用进程。1 表示内核允许分配所有的物理内存,而不管当前的内存状态如何。2 表示内核允许分配超过所有物理内存和交换空间总和的内存Redis官方的说明是, 建议将vm.overcommit_memory的值修改为1 ,可以用下面几种方式进行修改:(1)编辑/etc/sysctl.conf 改vm.overcommit_memory=1,然后sysctl -p 使配置文件生效(2)sysctl vm.overcommit_memory=1(3)echo 1 > /proc/sys/vm/overcommit_memory2、内存预分配3、持久化机制定时快照:效率不高,会丢失数据AOF:保持数据完整性(一个实例的数量不要太大2G最大)优化总结1)根据业务需要选择合适的数据类型2)当业务场景不需持久化时就关闭所有持久化方式(采用ssd磁盘来提升效率)3)不要使用虚拟内存的方式,每秒实时写入AOF4)不要让REDIS所在的服务器物理内存使用超过内存总量的3/55)要使用maxmemory6)大数据量按业务分开使用多个redis实例15、Redis集群应用集群是将 多个redis实例集中 在一起, 实现同一业务需求 ,或者 实现高可用与负载均衡 到底有哪些集群方案呢?1、haproxy+keepalived+redis集群1)通过redis的配置文件,实现主从复制、读写分离2)通过haproxy的配置,实现负载均衡,当从故障时也会及时从集群中T除3)利用keepalived来实现负载的高可用2、redis官方Sentinel集群管理工具Redis集群生产环境高可用方案实战过程 1)sentinel负责对集群中的主从服务监控、提醒和自动故障转移2)redis集群负责对外提供服务关于redis sentinel cluster集群配置可参考3、Redis ClusterRedis Cluster是Redis的分布式解决方案 ,在Redis 3.0版本正式推出的,有效解决了Redis分布式方面的需求。当遇到单机内存、并发、流量等瓶颈时,可以采用Cluster架构达到负载均衡的目的。1)官方推荐,毋庸置疑。2)去中心化,集群最大可增加1000个节点,性能随节点增加而线性扩展。3)管理方便,后续可自行增加或摘除节点,移动分槽等等。4)简单,易上手。
-
Redis 使用的 10 个小技巧 Redis 使用的 10 个小技巧Redis 在当前的技术社区里是非常热门的。从来自 Antirez 一个小小的个人项目到成为内存数据存储行业的标准,Redis已经走过了很长的一段路。随之而来的一系列最佳实践,使得大多数人可以正确地使用 Redis。下面我们将探索正确使用 Redis 的10个技巧。1、停止使用 KEYS *Okay,以挑战这个命令开始这篇文章,或许并不是一个好的方式,但其确实可能是最重要的一点。很多时候当我们关注一个redis实例的统计数据,我们会快速地输入”KEYS *”命令,这样key的信息会很明显地展示出来。平心而论,从程序化的角度出发往往倾向于写出下面这样的伪代码:for key in 'keys *': doAllTheThings()但是当你有1300万个key时,执行速度将会变慢。因为KEYS命令的时间复杂度是O(n),其中n是要返回的keys的个数,这样这个命令的复杂度就取决于数据库的大小了。并且在这个操作执行期间,其它任何命令在你的实例中都无法执行。作为一个替代命令,看一下 SCAN 吧,其允许你以一种更友好的方式来执行… SCAN 通过增量迭代的方式来扫描数据库。这一操作基于游标的迭代器来完成的,因此只要你觉得合适,你可以随时停止或继续。2、找出拖慢 Redis 的罪魁祸首由于 Redis 没有非常详细的日志,要想知道在 Redis 实例内部都做了些什么是非常困难的。幸运的是 Redis 提供了一个下面这样的命令统计工具:127.0.0.1:6379> INFO commandstatsCommandstatscmdstat_get:calls=78,usec=608,usec_per_call=7.79 cmdstat_setex:calls=5,usec=71,usec_per_call=14.20 cmdstat_keys:calls=2,usec=42,usec_per_call=21.00 cmdstat_info:calls=10,usec=1931,usec_per_call=193.10通过这个工具可以查看所有命令统计的快照,比如命令执行了多少次,执行命令所耗费的毫秒数(每个命令的总时间和平均时间)只需要简单地执行 CONFIG RESETSTAT 命令就可以重置,这样你就可以得到一个全新的统计结果。3、 将 Redis-Benchmark 结果作为参考,而不要一概而论Redis 之父 Salvatore 就说过:“通过执行GET/SET命令来测试Redis就像在雨天检测法拉利的雨刷清洁镜子的效果”。很多时候人们跑到我这里,他们想知道为什么自己的Redis-Benchmark统计的结果低于最优结果 。但我们必须要把各种不同的真实情况考虑进来,例如:可能受到哪些客户端运行环境的限制?是同一个版本号吗?测试环境中的表现与应用将要运行的环境是否一致?Redis-Benchmark的测试结果提供了一个保证你的 Redis-Server 不会运行在非正常状态下的基准点,但是你永远不要把它作为一个真实的“压力测试”。压力测试需要反应出应用的运行方式,并且需要一个尽可能的和生产相似的环境。4、Hashes 是你的最佳选择以一种优雅的方式引入 hashes 吧。hashes 将会带给你一种前所未有的体验。之前我曾看到过许多类似于下面这样的key结构:foo:first_name foo:last_name foo:address上面的例子中,foo 可能是一个用户的用户名,其中的每一项都是一个单独的 key。这就增加了 犯错的空间,和一些不必要的 key。使用 hash 代替吧,你会惊奇地发现竟然只需要一个 key :127.0.0.1:6379> HSET foo first_name "Joe" (integer) 1 127.0.0.1:6379> HSET foo last_name "Engel" (integer) 1 127.0.0.1:6379> HSET foo address "1 Fanatical Pl" (integer) 1 127.0.0.1:6379> HGETALL foo 1) "first_name" 2) "Joe" 3) "last_name" 4) "Engel" 5) "address" 6) "1 Fanatical Pl" 127.0.0.1:6379> HGET foo first_name "Joe"5、设置 key 值的存活时间无论什么时候,只要有可能就利用key超时的优势。一个很好的例子就是储存一些诸如临时认证key之类的东西。当你去查找一个授权key时——以OAUTH为例——通常会得到一个超时时间。这样在设置key的时候,设成同样的超时时间,Redis就会自动为你清除!而不再需要使用KEYS *来遍历所有的key了,怎么样很方便吧?6、 选择合适的回收策略既然谈到了清除key这个话题,那我们就来聊聊回收策略。当 Redis 的实例空间被填满了之后,将会尝试回收一部分key。根据你的使用方式,我强烈建议使用 volatile-lru 策略——前提是你对key已经设置了超时。但如果你运行的是一些类似于 cache 的东西,并且没有对 key 设置超时机制,可以考虑使用 allkeys-lru 回收机制。我的建议是先在这里查看一下可行的方案。7、如果你的数据很重要,请使用 Try/Except如果必须确保关键性的数据可以被放入到 Redis 的实例中,我强烈建议将其放入 try/except 块中。几乎所有的Redis客户端采用的都是“发送即忘”策略,因此经常需要考虑一个 key 是否真正被放到 Redis 数据库中了。至于将 try/expect 放到 Redis 命令中的复杂性并不是本文要讲的,你只需要知道这样做可以确保重要的数据放到该放的地方就可以了。8、不要耗尽一个实例无论什么时候,只要有可能就分散多redis实例的工作量。从3.0.0版本开始,Redis就支持集群了。Redis集群允许你基于key范围分离出部分包含主/从模式的key。完整的集群背后的“魔法”可以在这里找到。但如果你是在找教程,那这里是一个再适合不过的地方了。如果不能选择集群,考虑一下命名空间吧,然后将你的key分散到多个实例之中。关于怎样分配数据,在redis.io网站上有这篇精彩的评论。9、内核越多越好吗?!当然是错的。Redis 是一个单线程进程,即使启用了持久化最多也只会消耗两个内核。除非你计划在一台主机上运行多个实例——希望只会是在开发测试的环境下!——否则的话对于一个 Redis 实例是不需要2个以上内核的。10、高可用到目前为止 Redis Sentinel 已经经过了很全面的测试,很多用户已经将其应用到了生产环境中(包括 ObjectRocket )。如果你的应用重度依赖于 Redis ,那就需要想出一个高可用方案来保证其不会掉线。
-