搜索到
785
篇与
的结果
-
 PHP常用六大设计模式 PHP常用六大设计模式单例模式特点三私一公 :私有的静态变量(存放实例),私有的构造方法(防止创建实例),私有的克隆方法(防止克隆对象),公有的静态方法(对外界提供实例)应用场景程序应用中,涉及到数据库操作时,如果每次操作的时候连接数据库,会带来大量的资源消耗。可以通过单例模式,创建唯一的数据库连接对象。<?php class Singleton { private static $_instance; private function __construct(){} private function __clone(){} public static function getInstance() { if(self::$_instance instanceof Singleton){//instanceof 判断一个实例是否是某个类的对象 self::$_instance = new Singleton(); } return self::$_instance; } }工厂模式特点将调用对象与创建对象分离 ,调用者直接向工厂请求,减少代码的耦合,提高系统的可维护性与可扩展性。应用场景提供一种类,具有为您创建对象的某些方法,这样就可以使用工厂类创建对象,而不直接使用new。这样如果想更改创建的对象类型,只需更改该工厂即可。//假设3个待实例化的类 class Aclass { } class Bclass { } class Cclass { } class Factory { //定义每个类的类名 const ACLASS = 'Aclass'; const BCLASS = 'Bclass'; const CCLASS = 'Cclass'; public static function getInstance($newclass) { $class = $newclass;//真实项目中这里常常是用来解析路由,加载文件。 return new $class; } } //调用方法: Factory::getInstance(Factory::ACLASS);注册树模式特点注册树模式通过 将对象实例注册到一棵全局的对象树上,需要的时候从对象树上采摘 的模式设计方法。应用场景不管你是通过单例模式还是工厂模式还是二者结合生成的对象,都统统给我“插到”注册树上。我用某个对象的时候,直接从注册树上取一下就好。这和我们使用全局变量一样的方便实用。而且注册树模式还为其他模式提供了一种非常好的想法。 (如下实例是单例,工厂,注册树的联合使用)//创建单例 class Single{ public $hash; static protected $ins=null; final protected function __construct(){ $this->hash=rand(1,9999); } static public function getInstance(){ if (self::$ins instanceof self) { return self::$ins; } self::$ins=new self(); return self::$ins; } } //工厂模式 class RandFactory{ public static function factory(){ return Single::getInstance(); } } //注册树 class Register{ protected static $objects; public static function set($alias,$object){ self::$objects[$alias]=$object; } public static function get($alias){ return self::$objects[$alias]; } public static function _unset($alias){ unset(self::$objects[$alias]); } } //调用 Register::set('rand',RandFactory::factory()); $object=Register::get('rand'); print_r($object);策略模式定义定义一系列算法,将每一个算法封装起来,并让它们可以相互替换。策略模式让算法独立于使用它的客户而变化。特点策略模式提供了 管理相关的算法族 的办法策略模式提供了 可以替换继承关系 的办法使用策略模式可以 避免使用多重条件转移语句应用场景多个类只区别在表现行为不同,可以使用Strategy模式,在运行时动态选择具体要执行的行为。比如上学,有多种策略:走路,公交,地铁…abstract class Strategy { abstract function goSchoole(); } class Run extends Strategy { public function goSchoole() { // TODO: Implement goSchool() method. echo "Run to school <br/>"; } } class Subway extends Strategy { public function goSchoole() { // TODO: Implement goSchool() method. echo "Take the subway to school <br/>"; } } class Bike extends Strategy { public function goSchoole() { // TODO: Implement goSchool() method. echo "Go to school by bike <br/>"; } } class Context { protected $_stratege;//存储传过来的策略对象 public function goSchoole() { $this->_stratege->goSchoole(); } public function setBehavior(Strategy $behavior){//设置策略对象 $this->_stratege = $behavior; } } //调用: $contenx = new Context(); //坐地铁去学校 $contenx->setBehavior(new Subway()); $contenx->goSchoole(); //骑自行车去学校 $contenx->setBehavior(new Bike()); $contenx->goSchoole();适配器模式特点将各种截然不同的函数接口封装成统一的API。应用场景PHP中的数据库操作有MySQL,MySQLi,PDO三种,可以用适配器模式统一成一致,使不同的数据库操作,统一成一样的API。类似的场景还有cache适配器,可以将memcache,redis,file,apc等不同的缓存函数,统一成一致。abstract class Toy { public abstract function openMouth(); public abstract function closeMouth(); } class Dog extends Toy { public function openMouth() { echo "Dog open Mouth<br/>"; } public function closeMouth() { echo "Dog close Mouth<br/>"; } } class Cat extends Toy { public function openMouth() { echo "Cat open Mouth<br/>"; } public function closeMouth() { echo "Cat close Mouth<br/>"; } } //目标角色(红) interface RedTarget { public function doMouthOpen(); public function doMouthClose(); } //目标角色(绿) interface GreenTarget { public function operateMouth($type = 0); } //类适配器角色(红) class RedAdapter implements RedTarget { private $adaptee; function __construct(Toy $adaptee) { $this->adaptee = $adaptee; } //委派调用Adaptee的sampleMethod1方法 public function doMouthOpen() { $this->adaptee->openMouth(); } public function doMouthClose() { $this->adaptee->closeMouth(); } } //类适配器角色(绿) class GreenAdapter implements GreenTarget { private $adaptee; function __construct(Toy $adaptee) { $this->adaptee = $adaptee; } //委派调用Adaptee:GreenTarget的operateMouth方法 public function operateMouth($type = 0) { if ($type) { $this->adaptee->openMouth(); } else { $this->adaptee->closeMouth(); } } } class testDriver { public function run() { //实例化一只狗玩具 $adaptee_dog = new Dog(); echo "给狗套上红枣适配器<br/>"; $adapter_red = new RedAdapter($adaptee_dog); //张嘴 $adapter_red->doMouthOpen(); //闭嘴 $adapter_red->doMouthClose(); echo "给狗套上绿枣适配器<br/>"; $adapter_green = new GreenAdapter($adaptee_dog); //张嘴 $adapter_green->operateMouth(1); //闭嘴 $adapter_green->operateMouth(0); } } //调用 $test = new testDriver(); $test->run();观察者模式特点观察者模式(Observer), 当一个对象状态发生变化时,依赖它的对象全部会收到通知,并自动更新。 观察者模式实现了低耦合,非侵入式的通知与更新机制。应用场景一个事件发生后,要执行一连串更新操作。传统的编程方式,就是在事件的代码之后直接加入处理的逻辑。当更新的逻辑增多之后,代码会变得难以维护。这种方式是耦合的,侵入式的,增加新的逻辑需要修改事件的主体代码。// 主题接口 interface Subject{ public function register(Observer $observer); public function notify(); } // 观察者接口 interface Observer{ public function watch(); } // 主题 class Action implements Subject{ public $_observers=[]; public function register(Observer $observer){ $this->_observers[]=$observer; } public function notify(){ foreach ($this->_observers as $observer) { $observer->watch(); } } } // 观察者 class Cat1 implements Observer{ public function watch(){ echo "Cat1 watches TV<hr/>"; } } class Dog1 implements Observer{ public function watch(){ echo "Dog1 watches TV<hr/>"; } } class People implements Observer{ public function watch(){ echo "People watches TV<hr/>"; } } // 调用实例 $action=new Action(); $action->register(new Cat1()); $action->register(new People()); $action->register(new Dog1()); $action->notify();
PHP常用六大设计模式 PHP常用六大设计模式单例模式特点三私一公 :私有的静态变量(存放实例),私有的构造方法(防止创建实例),私有的克隆方法(防止克隆对象),公有的静态方法(对外界提供实例)应用场景程序应用中,涉及到数据库操作时,如果每次操作的时候连接数据库,会带来大量的资源消耗。可以通过单例模式,创建唯一的数据库连接对象。<?php class Singleton { private static $_instance; private function __construct(){} private function __clone(){} public static function getInstance() { if(self::$_instance instanceof Singleton){//instanceof 判断一个实例是否是某个类的对象 self::$_instance = new Singleton(); } return self::$_instance; } }工厂模式特点将调用对象与创建对象分离 ,调用者直接向工厂请求,减少代码的耦合,提高系统的可维护性与可扩展性。应用场景提供一种类,具有为您创建对象的某些方法,这样就可以使用工厂类创建对象,而不直接使用new。这样如果想更改创建的对象类型,只需更改该工厂即可。//假设3个待实例化的类 class Aclass { } class Bclass { } class Cclass { } class Factory { //定义每个类的类名 const ACLASS = 'Aclass'; const BCLASS = 'Bclass'; const CCLASS = 'Cclass'; public static function getInstance($newclass) { $class = $newclass;//真实项目中这里常常是用来解析路由,加载文件。 return new $class; } } //调用方法: Factory::getInstance(Factory::ACLASS);注册树模式特点注册树模式通过 将对象实例注册到一棵全局的对象树上,需要的时候从对象树上采摘 的模式设计方法。应用场景不管你是通过单例模式还是工厂模式还是二者结合生成的对象,都统统给我“插到”注册树上。我用某个对象的时候,直接从注册树上取一下就好。这和我们使用全局变量一样的方便实用。而且注册树模式还为其他模式提供了一种非常好的想法。 (如下实例是单例,工厂,注册树的联合使用)//创建单例 class Single{ public $hash; static protected $ins=null; final protected function __construct(){ $this->hash=rand(1,9999); } static public function getInstance(){ if (self::$ins instanceof self) { return self::$ins; } self::$ins=new self(); return self::$ins; } } //工厂模式 class RandFactory{ public static function factory(){ return Single::getInstance(); } } //注册树 class Register{ protected static $objects; public static function set($alias,$object){ self::$objects[$alias]=$object; } public static function get($alias){ return self::$objects[$alias]; } public static function _unset($alias){ unset(self::$objects[$alias]); } } //调用 Register::set('rand',RandFactory::factory()); $object=Register::get('rand'); print_r($object);策略模式定义定义一系列算法,将每一个算法封装起来,并让它们可以相互替换。策略模式让算法独立于使用它的客户而变化。特点策略模式提供了 管理相关的算法族 的办法策略模式提供了 可以替换继承关系 的办法使用策略模式可以 避免使用多重条件转移语句应用场景多个类只区别在表现行为不同,可以使用Strategy模式,在运行时动态选择具体要执行的行为。比如上学,有多种策略:走路,公交,地铁…abstract class Strategy { abstract function goSchoole(); } class Run extends Strategy { public function goSchoole() { // TODO: Implement goSchool() method. echo "Run to school <br/>"; } } class Subway extends Strategy { public function goSchoole() { // TODO: Implement goSchool() method. echo "Take the subway to school <br/>"; } } class Bike extends Strategy { public function goSchoole() { // TODO: Implement goSchool() method. echo "Go to school by bike <br/>"; } } class Context { protected $_stratege;//存储传过来的策略对象 public function goSchoole() { $this->_stratege->goSchoole(); } public function setBehavior(Strategy $behavior){//设置策略对象 $this->_stratege = $behavior; } } //调用: $contenx = new Context(); //坐地铁去学校 $contenx->setBehavior(new Subway()); $contenx->goSchoole(); //骑自行车去学校 $contenx->setBehavior(new Bike()); $contenx->goSchoole();适配器模式特点将各种截然不同的函数接口封装成统一的API。应用场景PHP中的数据库操作有MySQL,MySQLi,PDO三种,可以用适配器模式统一成一致,使不同的数据库操作,统一成一样的API。类似的场景还有cache适配器,可以将memcache,redis,file,apc等不同的缓存函数,统一成一致。abstract class Toy { public abstract function openMouth(); public abstract function closeMouth(); } class Dog extends Toy { public function openMouth() { echo "Dog open Mouth<br/>"; } public function closeMouth() { echo "Dog close Mouth<br/>"; } } class Cat extends Toy { public function openMouth() { echo "Cat open Mouth<br/>"; } public function closeMouth() { echo "Cat close Mouth<br/>"; } } //目标角色(红) interface RedTarget { public function doMouthOpen(); public function doMouthClose(); } //目标角色(绿) interface GreenTarget { public function operateMouth($type = 0); } //类适配器角色(红) class RedAdapter implements RedTarget { private $adaptee; function __construct(Toy $adaptee) { $this->adaptee = $adaptee; } //委派调用Adaptee的sampleMethod1方法 public function doMouthOpen() { $this->adaptee->openMouth(); } public function doMouthClose() { $this->adaptee->closeMouth(); } } //类适配器角色(绿) class GreenAdapter implements GreenTarget { private $adaptee; function __construct(Toy $adaptee) { $this->adaptee = $adaptee; } //委派调用Adaptee:GreenTarget的operateMouth方法 public function operateMouth($type = 0) { if ($type) { $this->adaptee->openMouth(); } else { $this->adaptee->closeMouth(); } } } class testDriver { public function run() { //实例化一只狗玩具 $adaptee_dog = new Dog(); echo "给狗套上红枣适配器<br/>"; $adapter_red = new RedAdapter($adaptee_dog); //张嘴 $adapter_red->doMouthOpen(); //闭嘴 $adapter_red->doMouthClose(); echo "给狗套上绿枣适配器<br/>"; $adapter_green = new GreenAdapter($adaptee_dog); //张嘴 $adapter_green->operateMouth(1); //闭嘴 $adapter_green->operateMouth(0); } } //调用 $test = new testDriver(); $test->run();观察者模式特点观察者模式(Observer), 当一个对象状态发生变化时,依赖它的对象全部会收到通知,并自动更新。 观察者模式实现了低耦合,非侵入式的通知与更新机制。应用场景一个事件发生后,要执行一连串更新操作。传统的编程方式,就是在事件的代码之后直接加入处理的逻辑。当更新的逻辑增多之后,代码会变得难以维护。这种方式是耦合的,侵入式的,增加新的逻辑需要修改事件的主体代码。// 主题接口 interface Subject{ public function register(Observer $observer); public function notify(); } // 观察者接口 interface Observer{ public function watch(); } // 主题 class Action implements Subject{ public $_observers=[]; public function register(Observer $observer){ $this->_observers[]=$observer; } public function notify(){ foreach ($this->_observers as $observer) { $observer->watch(); } } } // 观察者 class Cat1 implements Observer{ public function watch(){ echo "Cat1 watches TV<hr/>"; } } class Dog1 implements Observer{ public function watch(){ echo "Dog1 watches TV<hr/>"; } } class People implements Observer{ public function watch(){ echo "People watches TV<hr/>"; } } // 调用实例 $action=new Action(); $action->register(new Cat1()); $action->register(new People()); $action->register(new Dog1()); $action->notify(); -
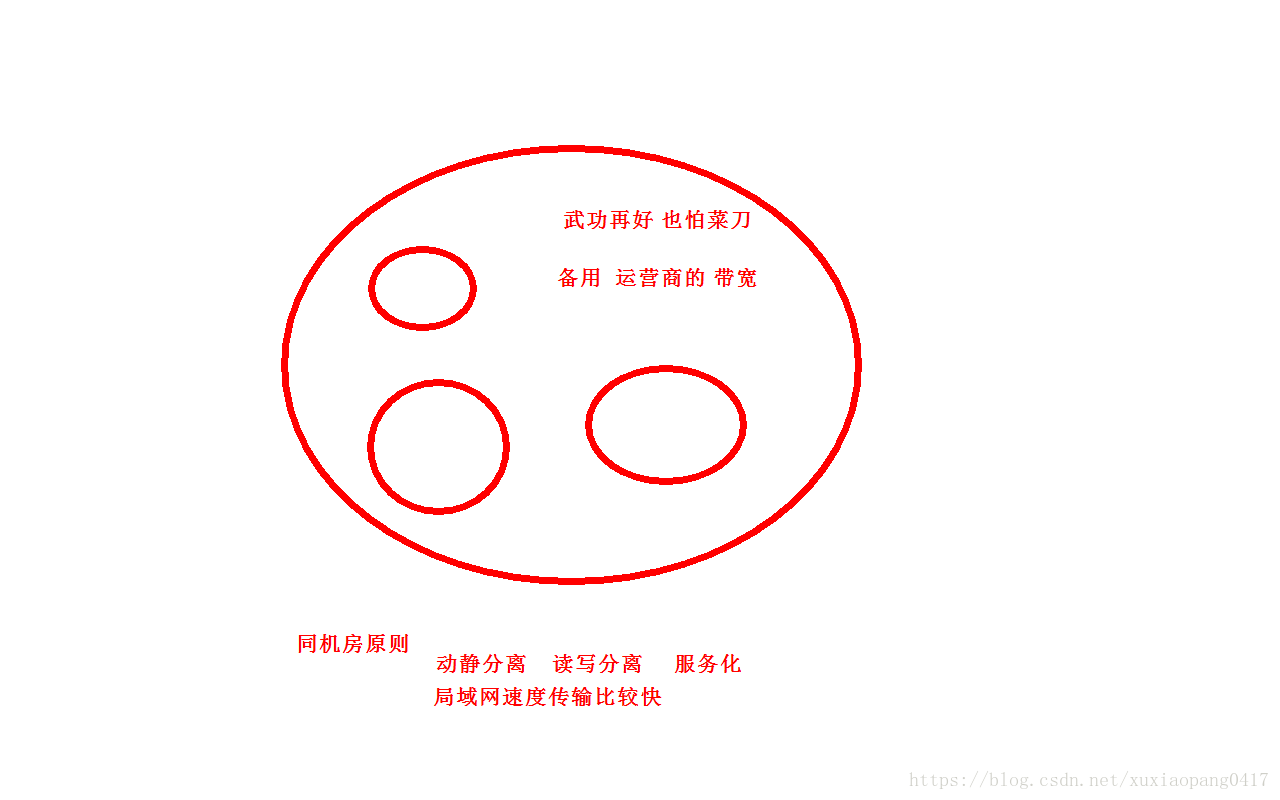
动静分离架构 动静分离架构一、静态页面静态页面,是指互联网架构中,几乎不变的页面(或者变化频率很低)静态页面例如首页等html页面js/css等样式文件jpg/apk等资源文件与之匹配的技术架构来加速静态页面,有与之匹配的技术架构来加速,例如:CDNnginxsquid/varnish二、动态页面动态页面,是指互联网架构中,不同用户不同场景访问,都不一样的页面动态页面例如百度搜索结果页淘宝商品列表页速运个人订单中心页这些页面,不同用户,不同场景访问,大都会动态生成不同的页面。与之匹配的技术架构动态页面,有与之匹配的技术架构,例如:分层架构服务化架构数据库,缓存架构三、互联网动静分离架构动静分离是指,静态页面与动态页面分开不同系统访问的架构设计方法。一般来说:静态页面访问路径短,访问速度快,几毫秒动态页面访问路径长,访问速度相对较慢(数据库的访问,网络传输,业务逻辑计算),几十毫秒甚至几百毫秒,对架构扩展性的要求更高静态页面与动态页面以不同域名区分四、页面静态化既然静态页面访问快,动态页面生成慢,有没有可能,将原本需要动态生成的站点提前生成好,使用静态页面加速技术来访问呢?这就是互联网架构中的“页面静态化”优化技术。举例,如下图,58同城的帖子详情页,原本是需要动态生成的:浏览器发起http请求,访问/detail/12348888x.shtml 详情页web-server层从RESTful接口中,解析出帖子id是12348888service层通过DAO层拼装SQL语句,访问数据库最终获取数据,拼装html返回浏览器而“页面静态化”是指,将帖子ID为12348888的帖子12348888x.shtml提前生成好,由静态页面相关加速技术来加速:这样的话,将极大提升访问速度,减少访问时间,提高用户体验。五、页面静态化的适用场景页面静态化优化后速度会加快,那能不能所有的场景都使用这个优化呢?哪些业务场景适合使用这个架构优化方案呢?一切脱离业务的架构设计都是耍流氓,页面静态化,适用于:总数据量不大,生成静态页面数量不多的业务。例如:58速运的城市页只有几百个,就可以用这个优化,只需提前生成几百个城市的“静态化页面”即可一些二手车业务,只有几万量二手车库存,也可以提前生成这几万量二手车的静态页面像58同城这样的信息模式业务,有几十亿的帖子量,就不太适合于静态化(碎片文件多,反而访问慢)六、总结“页面静态化”是一种将原本需要动态生成的站点提前生成静态站点的优化技术。 总数据量不大,生成静态页面数量不多的业务,非常适合于“页面静态化”优化。
-
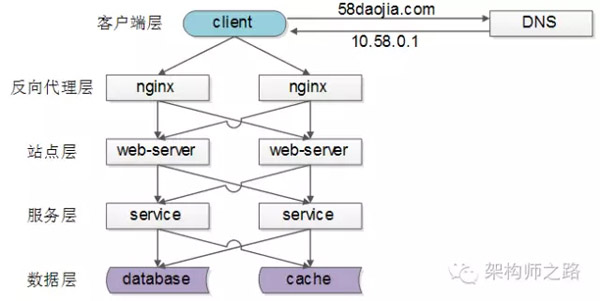
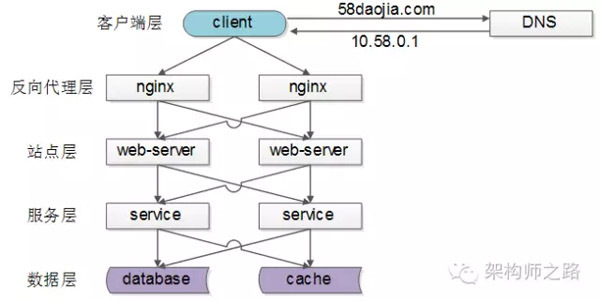
一分钟了解负载均衡的一切 一分钟了解负载均衡的一切什么是负载均衡负载均衡(Load Balance) 是分布式系统架构设计中必须考虑的因素之一,它通常是指, 将请求/数据【均匀】分摊到多个操作单元上执行,负载均衡的关键在于【均匀】。常见的负载均衡方案常见互联网分布式架构如上,分为 客户端层、反向代理nginx层、站点层、服务层、数据层 。可以看到,每一个下游都有多个上游调用,只需要做到,每一个上游都均匀访问每一个下游,就能实现“将请求/数据【均匀】分摊到多个操作单元上执行”。【客户端层->反向代理层】的负载均衡【客户端层】到【反向代理层】的负载均衡,是通过“DNS轮询”实现的:DNS-server对于一个域名配置了多个解析ip,每次DNS解析请求来访问DNS-server,会轮询返回这些ip,保证每个ip的解析概率是相同的。这些ip就是nginx的外网ip,以做到每台nginx的请求分配也是均衡的。【反向代理层->站点层】的负载均衡【反向代理层】到【站点层】的负载均衡,是通过“nginx”实现的。通过修改nginx.conf,可以实现多种负载均衡策略:1)请求轮询:和DNS轮询类似,请求依次路由到各个web-server2)最少连接路由:哪个web-server的连接少,路由到哪个web-server3)ip哈希:按照访问用户的ip哈希值来路由web-server,只要用户的ip分布是均匀的,请求理论上也是均匀的,ip哈希均衡方法可以做到,同一个用户的请求固定落到同一台web-server上,此策略适合有状态服务,例如session(58沈剑备注:可以这么做,但强烈不建议这么做,站点层无状态是分布式架构设计的基本原则之一,session*放到数据层存储)4)…【站点层->服务层】的负载均衡【站点层】到【服务层】的负载均衡,是通过“服务连接池”实现的。上游连接池会建立与下游服务多个连接,每次请求会“随机”选取连接来访问下游服务。上一篇文章《RPC-client实现细节》中有详细的负载均衡、故障转移、超时处理的细节描述,欢迎点击link查阅,此处不再展开。【数据层】的负载均衡在数据量很大的情况下,由于数据层(db,cache)涉及数据的水平切分,所以数据层的负载均衡更为复杂一些,它 分为“数据的均衡”,与“请求的均衡” 。数据的均衡是指:水平切分后的每个服务(db,cache),数据量是差不多的。请求的均衡是指:水平切分后的每个服务(db,cache),请求量是差不多的。常见的水平切分方式业内常见的水平切分方式有这么几种:一、按照range水平切分每一个数据服务,存储一定范围的数据,上图为例:user0服务,存储uid范围1-1kwuser1服务,存储uid范围1kw-2kw好处这个方案的好处是:(1)规则简单,service只需判断一下uid范围就能路由到对应的存储服务(2)数据均衡性较好(3)比较容易扩展,可以随时加一个uid[2kw,3kw]的数据服务不足不足是:(1)请求的负载不一定均衡,一般来说,新注册的用户会比老用户更活跃,大range的服务请求压力会更大二、按照id哈希水平切分每一个数据服务,存储某个key值hash后的部分数据,上图为例:user0服务,存储偶数uid数据user1服务,存储奇数uid数据好处这个方案的好处是:(1)规则简单,service只需对uid进行hash能路由到对应的存储服务(2)数据均衡性较好(3)请求均匀性较好不足不足是:(1)不容易扩展,扩展一个数据服务,hash方法改变时候,可能需要进行数据迁移总结负载均衡(Load Balance)是分布式系统架构设计中必须考虑的因素之一,它通常是指,将请求/数据【均匀】分摊到多个操作单元上执行,负载均衡的关键在于【均匀】。(1)【客户端层】到【反向代理层】的负载均衡,是通过“DNS轮询”实现的(2)【反向代理层】到【站点层】的负载均衡,是通过“nginx”实现的(3)【站点层】到【服务层】的负载均衡,是通过“服务连接池”实现的(4)【数据层】的负载均衡,要考虑“数据的均衡”与“请求的均衡”两个点,常见的方式有“按照范围水平切分”与“hash水平切分”
-
关于负载均衡的一切:总结与思考 关于负载均衡的一切:总结与思考 概述 古人云,不患寡而患不均。 在计算机的世界,这就是大家耳熟能详的 负载均衡(load balancing) ,所谓负载均衡,就是说如果一组计算机节点(或者一组进程)提供相同的(同质的)服务,那么对服务的请求就应该均匀的分摊到这些节点上。负载均衡的前提一定是“provide a single Internet service from multiple servers”, 这些提供服务的节点被称之为server farm、server pool或者backend servers。 这里的服务是广义的,可以是简单的计算,也可能是数据的读取或者存储。负载均衡也不是新事物,这种思想在多核CPU时代就有了,只不过在分布式系统中,负载均衡更是无处不在,这是分布式系统的天然特性决定的,分布式就是利用大量计算机节点完成单个计算机无法完成的计算、存储服务,既然有大量计算机节点,那么均衡的调度就非常重要。 负载均衡的意义在于,让所有节点以最小的代价、最好的状态对外提供服务,这样系统吞吐量最大,性能更高,对于用户而言请求的时间也更小。而且,负载均衡增强了系统的可靠性,最大化降低了单个节点过载、甚至crash的概率。不难想象,如果一个系统绝大部分请求都落在同一个节点上,那么这些请求响应时间都很慢,而且万一节点降级或者崩溃,那么所有请求又会转移到下一个节点,造成雪崩。 事实上,网上有很多文章介绍负载均衡的算法,大多都是大同小异。本文更多的是自己对这些算法的总结与思考。一分钟了解负载均衡的一切 本章节的标题和内容都来自 一分钟了解负载均衡的一切 这一篇文章。当然,原文的标题是夸张了点,不过文中列出了在一个大型web网站中各层是如何用到负载均衡的,一目了然。 常见互联网分布式架构如上,分为客户端层、反向代理nginx层、站点层、服务层、数据层。可以看到,每一个下游都有多个上游调用,只需要做到,每一个上游都均匀访问每一个下游,就能实现“将请求/数据【均匀】分摊到多个操作单元上执行”。 (1)【客户端层】到【反向代理层】的负载均衡,是通过“DNS轮询”实现的 (2)【反向代理层】到【站点层】的负载均衡,是通过“nginx”实现的 (3)【站点层】到【服务层】的负载均衡,是通过“服务连接池”实现的 (4)【数据层】的负载均衡,要考虑“数据的均衡”与“请求的均衡”两个点,常见的方式有“按照范围水平切分”与“hash水平切分”。 数据层的负载均衡,在我之前的《带着问题学习分布式系统之数据分片》 中有详细介绍。算法衡量 在我看来,当我们提到一个负载均衡算法,或者具体的应用场景时,应该考虑以下问题 第一,是否意识到不同节点的服务能力是不一样的,比如CPU、内存、网络、地理位置 第二,是否意识到节点的服务能力是动态变化的,高配的机器也有可能由于一些突发原因导致处理速度变得很慢 第三,是否考虑将同一个客户端,或者说同样的请求分发到同一个处理节点,这对于“有状态”的服务非常重要,比如session,比如分布式存储 第四,谁来负责负载均衡,即谁充当负载均衡器(load balancer),balancer本身是否会成为瓶颈 下面会结合具体的算法来考虑这些问题负载均衡算法轮询算法(round-robin) 思想很简单,就是提供同质服务的节点逐个对外提供服务,这样能做到绝对的均衡。Python示例代码如下 SERVER_LIST = [ '10.246.10.1', '10.246.10.2', '10.246.10.3', ] def round_robin(server_lst, cur = [0]): length = len(server_lst) ret = server_lst[cur[0] % length] cur[0] = (cur[0] + 1) % length return ret 可以看到,所有的节点都是以同样的概率提供服务,即没有考虑到节点的差异,也许同样数目的请求,高配的机器CPU才20%,低配的机器CPU已经80%了加权轮询算法(weight round-robin) 加权轮训算法就是在轮训算法的基础上,考虑到机器的差异性,分配给机器不同的权重,能者多劳。注意,这个权重的分配依赖于请求的类型,比如计算密集型,那就考虑CPU、内存;如果是IO密集型,那就考虑磁盘性能。Python示例代码如下 WEIGHT_SERVER_LIST = { '10.246.10.1': 1, '10.246.10.2': 3, '10.246.10.3': 2, } def weight_round_robin(servers, cur = [0]): weighted_list = [] for k, v in servers.iteritems(): weighted_list.extend([k] * v) length = len(weighted_list) ret = weighted_list[cur[0] % length] cur[0] = (cur[0] + 1) % length return ret随机算法(random) 这个就更好理解了,随机选择一个节点服务,按照概率,只要请求数量足够多,那么也能达到绝对均衡的效果。而且实现简单很多 def random_choose(server_lst): import random random.seed() return random.choice(server_lst)加权随机算法(random) 如同加权轮训算法至于轮训算法一样,也是在随机的时候引入不同节点的权重,实现也很类似。def weight_random_choose(servers): import random random.seed() weighted_list = [] for k, v in servers.iteritems(): weighted_list.extend([k] * v) return random.choice(weighted_list) 当然,如果节点列表以及权重变化不大,那么也可以对所有节点归一化,然后按概率区间选择 def normalize_servers(servers): normalized_servers = {} total = sum(servers.values()) cur_sum = 0 for k, v in servers.iteritems(): normalized_servers[k] = 1.0 * (cur_sum + v) / total cur_sum += v return normalized_servers def weight_random_choose_ex(normalized_servers): import random, operator random.seed() rand = random.random() for k, v in sorted(normalized_servers.iteritems(), key = operator.itemgetter(1)): if v >= rand: return k else: assert False, 'Error normalized_servers with rand %s ' % rand 哈希法(hash) 根据客户端的IP,或者请求的“Key”,计算出一个hash值,然后对节点数目取模。好处就是,同一个请求能够分配到同样的服务节点,这对于“有状态”的服务很有必要 def hash_choose(request_info, server_lst): hashed_request_info = hash(request_info) return server_lst[hashed_request_info % len(server_lst)] 只要hash结果足够分散,也是能做到绝对均衡的。一致性哈希 哈希算法的缺陷也很明显,当节点的数目发生变化的时候,请求会大概率分配到其他的节点,引发到一系列问题,比如sticky session。而且在某些情况,比如分布式存储,是绝对的不允许的。 为了解决这个哈希算法的问题,又引入了一致性哈希算法,简单来说,一个物理节点与多个虚拟节点映射,在hash的时候,使用虚拟节点数目而不是物理节点数目。当物理节点变化的时候,虚拟节点的数目无需变化,只涉及到虚拟节点的重新分配。而且,调整每个物理节点对应的虚拟节点数目,也就相当于每个物理节点有不同的权重最少连接算法(least connection) 以上的诸多算法,要么没有考虑到节点间的差异(轮训、随机、哈希),要么节点间的权重是静态分配的(加权轮训、加权随机、一致性hash)。 考虑这么一种情况,某台机器出现故障,无法及时处理请求,但新的请求还是会以一定的概率源源不断的分配到这个节点,造成请求的积压。因此,根据节点的真实负载,动态地调整节点的权重就非常重要。当然,要获得接节点的真实负载也不是一概而论的事情,如何定义负载,负载的收集是否及时,这都是需要考虑的问题。 每个节点当前的连接数目是一个非常容易收集的指标,因此lease connection是最常被人提到的算法。也有一些侧重不同或者更复杂、更客观的指标,比如最小响应时间(least response time)、最小活跃数(least active)等等。一点思考有状态的请求 首先来看看“算法衡量”中提到的第三个问题:同一个请求是否分发到同样的服务节点,同一个请求指的是同一个用户或者同样的唯一标示。什么时候同一请求最好(必须)分发到同样的服务节点呢?那就是有状态 -- 请求依赖某些存在于内存或者磁盘的数据,比如web请求的session,比如分布式存储。怎么实现呢,有以下几种办法: (1)请求分发的时候,保证同一个请求分发到同样的服务节点。 这个依赖于负载均衡算法,比如简单的轮训,随机肯定是不行的,哈希法在节点增删的时候也会失效。可行的是一致性hash,以及分布式存储中的按范围分段(即记录哪些请求由哪个服务节点提供服务),代价是需要在load balancer中维护额外的数据。 (2)状态数据在backend servers之间共享 保证同一个请求分发到同样的服务节点,这个只是手段,目的是请求能使用到对应的状态数据。如果状态数据能够在服务节点之间共享,那么也能达到这个目的。比如服务节点连接到共享数据库,或者内存数据库如memcached (3)状态数据维护在客户端 这个在web请求中也有使用,即cookie,不过要考虑安全性,需要加密。关于load balancer 接下来回答第四个问题:关于load balancer,其实就是说,在哪里做负载均衡,是客户端还是服务端,是请求的发起者还是请求的3。具体而言,要么是在客户端,根据服务节点的信息自行选择,然后将请求直接发送到选中的服务节点;要么是在服务节点集群之前放一个集中式代理(proxy),由代理负责请求求分发。不管哪一种,至少都需要知道当前的服务节点列表这一基础信息。 如果在客户端实现负载均衡,客户端首先得知道服务器列表,要么是静态配置,要么有简单接口查询,但backend server的详细负载信息,就不适用通过客户端来查询。因此,客户端的负载均衡算法要么是比较简单的,比如轮训(加权轮训)、随机(加权随机)、哈希这几种算法,只要每个客户端足够随机,按照大数定理,服务节点的负载也是均衡的。要在客户端使用较为复杂的算法,比如根据backend的实际负载,那么就需要去额外的负载均衡服务(external load balancing service)查询到这些信息,在grpc中,就是使用的这种办法 可以看到,load balancer与grpc server通信,获得grpc server的负载等具体详细,然后grpc client从load balancer获取这些信息,最终grpc client直连到被选择的grpc server。 而基于Proxy的方式是更为常见的,比如7层的Nginx,四层的F5、LVS,既有硬件路由,也有软件分发。集中式的特点在于方便控制,而且能容易实现一些更精密,更复杂的算法。但缺点也很明显,一来负载均衡器本身可能成为性能瓶颈;二来可能引入额外的延迟,请求一定先发到达负载均衡器,然后到达真正的服务节点。 load balance proxy对于请求的响应(response),要么不经过proxy(三角传输模式),如LVS;要么经过Proxy,如Nginx。下图是LVS示意图(来源见水印) 而如果response也是走load balancer proxy的话,那么整个服务过程对客户端而言就是完全透明的,也防止了客户端去尝试连接后台服务器,提供了一层安全保障! 值得注意的是,load balancer proxy不能成为单点故障(single point of failure),因此一般会设计为高可用的主从结构# 其他 在这篇文章中提到,负载均衡是一种推模型,一定会选出一个服务节点,然后把请求推送过来。而换一种思路,使用消息队列,就变成了拉模型:空闲的服务节点主动去拉取请求进行处理,各个节点的负载自然也是均衡的。消息队列相比负载均衡好处在于,服务节点不会被大量请求冲垮,同时增加服务节点更加容易;缺点也很明显,请求不是事实处理的。 想到另外一个例子,比如在gunicorn这种pre-fork模型中,master(gunicorn 中Arbiter)会fork出指定数量的worker进程,worker进程在同样的端口上监听,谁先监听到网络连接请求,谁就提供服务,这也是worker进程之间的负载均衡。
-
业界异地多活高可用架构设计方案总结 业界异地多活高可用架构设计方案总结异地多活 在近年越来越多大型互联网公司采用的方案, 几乎也是大型应用发展到一定阶段的必然选择 ,综合比较一下各个互联网公司的方案,会发现有很多共性的东西,也有很多差异化的东西,这是最有意思的地方什么是异地多活异地多活一般是指在不同城市建立独立的数据中心,“活”是相对于冷备份而言的,冷备份是备份全量数据,平时不支撑业务需求,只有在主机房出现故障的时候才会切换到备用机房,而多活,是指这些机房在日常的业务中也需要走流量,做业务支撑。冷备份的主要问题是成本高,不跑业务,当主机房出问题的时候,也不一定能成功把业务接管过来。CAP原则分布式架构设计无论怎样都绕不开CAP原则,C一致性 A可用性 P分区容错性,分区容错性是必不可少的,没有分区容错性就相当于退化成了单机系统,所以实际上架构设计是在一致性和可用性一个天平上的两端做衡量。为什么强一致性和高可用性是不能同时满足?假如需要满足强一致性,就需要写入一条数据的时候,扩散到分布式系统里面的每一台机器,每一台机器都回复ACK确认后再给客户端确认,这就是强一致性。如果集群任何一台机器故障了,都回滚数据,对客户端返回失败,因此影响了可用性。如果只满足高可用性,任何一台机器写入成功都返回成功,那么有可能中途因为网络抖动或者其他原因造成了数据不同步,部分客户端独到的仍然是旧数据,因此,无法满足强一致性。异地多活的挑战延迟 异地多活面临的主要挑战是网络延迟,以北京到上海 1468 公里,即使是光速传输,一个来回也需要接近10ms,在实际测试的过程中,发现上海到北京的网络延迟,一般是 30 ms。一致性 用户在任何一个机房写入的数据,是否能在任何一个机房读取的时候返回的值是一致性的。误区所有业务都要异地多活以用户中心为例,注册是没必要做异地多活的,假如用户在A机房注册了,在数据没有向外同步的时候,A机房网络中断,这个时候如果让用户切换到B机房注册,就有可能发生数据不一致,出现两个基本相同的账号,这是不可容忍的。但是相对应的来说,用户登录这种是关键核心业务,就有必要做到异地多活了,用户在A机房登录不了,那就让用户在B机房登录。虽然有极端的情况,用户在A机房修改了密码,但是出现网络中断,B机房的用户仍然保存的是旧密码,但是相对于不可登录来说,这种情况是可容忍的。同时有些业务仍然是无法实现异地多活的,比如涉及到金钱的业务,加入有一个用户有100块,消费了50块,A机房发生异常,数据没有同步出去,这时候用户在B机房登录后发现自己还有100块,可以继续消费,就会对业务造成严重的影响。必须做到实时一致性受限于物理条件,跨地域的网速一定会存在延迟,一般是几十毫秒,如果遇上网络抖动,延迟超过几秒甚至几十秒都有可能。解决方法只能是减少需要同步的数据和只保证数据的最终一致性,有时候用户在A机房修改了一条数据,业务上实际上是能容忍数据的短时间不一致的,即使其他用户在B机房读到的是旧数据,实际上对业务也没有任何影响。只使用存储系统的同步功能大部分场景下,MySQL Redis自带的同步功能已经足以满足需求了,但是在某些极端情况下,可能就不合适了,MySQL的单线程复制可能会产生较大的延迟,Redis可能会有全量复制,所以系统要灵活使用各种解决方案。用消息队列把数据广播到各个数据中心回源读取,当A机房发现没有这条数据的时候,根据路由规则去B机房去读取该数据重新生成数据,A机房登录后生成session数据,这时候A机房挂了,可以把用户切换到B机房,重新生成session数据。实现100%的高可用100%的高可用是无法保证的,硬件的损坏,软件的BUG,光纤传输等太多不可控的因素,而且也要在成本上做一个权衡,尤其是对于强一致性业务,C和A只能取一个平衡,容忍短时间的不可用来保证数据的完全一致性。饿了么异地多活方案特点业务内聚,单个订单的所有流程保证在一个机房内完成调用,不允许进行跨机房调用。每一个机房称为一个ezone,对服务进行分区,让用户,商户,骑手按照规则聚合到一个ezone内。根据业务特点,饿了么选择了把地理位置作为划分业务的单元,以行政省界用围栏把全国分为多个shard。在某个机房出现问题的时候,也可以按照地理位置把用户,商户,骑手打包迁移到别的机房即可。可用性优先,当机房发生故障的时候,优先保证可用,用户可以先下单吃饭,有限时间窗口内的数据不一致可以事后再修复。每个 ezone 都会有全量的业务数据,当一个 ezone 失效后,其他的 ezone 可以接管用户。用户在一个ezone的下单数据,会实时的复制到其他ezone。保证数据的正确性,在切换和故障时,检测到某些订单在两个机房不一致,会锁定改订单,避免错误进一步扩散。通过DRC复制MySQL数据MySQL的数据量最大,每个机房产生的数据,都通过 DRC 复制到其他 ezone,每个ezone的主键取值空间是ezoneid + 固定步长,所以产生的 id 各不相同,数据复制到一起后不会发生主键冲突。按照分区规则,正常情况下,每个 ezone 只会写入自己的数据,但万一出现异常,2个 ezone 同时更新了同一笔数据,就会产生冲突。DRC 支持基于时间戳的冲突解决方案,当一笔数据在两个机房同时被修改时,最后修改的数据会被保留,老的数据会被覆盖。通过Global Zone保证强一致性对于个别一致性要求很高的应用,我们提供了一种强一致的方案(Global Zone),Globa Zone是一种跨机房的读写分离机制,所有的写操作被定向到一个 Master 机房进行,以保证一致性,读操作可以在每个机房的 Slave库执行,也可以 bind 到 Master 机房进行,这一切都基于我们的数据库访问层(DAL)完成,业务基本无感知。新浪微博异地多活方案微博使用了基于 MCQ(微博自研的消息队列)的跨机房消息同步方案,并开发出跨机房消息同步组件 WMB(Weibo Message Broker)。每个机房的缓存是完全独立的,由每个机房的 Processor(专门负责消息处理的程序,类 Storm)根据收到的消息进行缓存更新。由于消息不会重复分发,而且信息完备,所以 MytriggerQ 方案存在的缓存更新脏数据问题就解决了。而当缓存不存在时,会穿透到 MySQL 从库,然后进行回种。可能出现的问题是,缓存穿透,但是 MySQL 从库如果此时出现延迟,这样就会把脏数据种到缓存中。解决方案是做一个延时 10 分钟的消息队列,然后由一个处理程序来根据这个消息做数据的重新载入。一般从库延时时间不超过 10 分钟,而 10 分钟内的脏数据在微博的业务场景下也是可以接受的。由于微博对数据库不是强依赖,加上数据库双写的维护成本过大,选择的方案是数据库通过主从同步的方式进行。这套方案可能的缺点是如果主从同步慢,并且缓存穿透,这时可能会出现脏数据。这种同步方式已运行了三年,整体上非常稳定,没有发生因为数据同步而导致的服务故障。阿里异地多活方案阿里在部署异地多活的时候同样是碰到延时问题,解决方案是访问一次页面的操作都在本机房完成,不做跨机房调用。阿里把业务划分成各种单元,如交易单元,这个单元是完成交易业务,称之为单元化。服务延时让操作全部在同一中心内完成,单元化比如用户进入以后,比如说在淘宝上看商品,浏览商品,搜索、下单、放进购物车等等操作,还包括写数据库,就都是在所进入的那个数据中心中完成的,而不需要跨数据中心部署:异地部署的是流量会爆发式增长的,流量很大的那部分。流量小的,用的不多的,不用异地部署。其他一些功能就会缺失,所以我们在异地部署的并非全站,而是一组业务,这组业务就成为单元比如:在异地只部署跟买家交易相关的核心业务,确保一个买家在淘宝上浏览商品,一直到买完东西的全过程都可以完成路由一致性:买家相关的数据在写的时候,一定是要写在那个单元里。要保障这个用户从进来一直到访问服务,到访问数据库,全链路的路由规则都是完全一致的。如果说某个用户本来应该进A城市的数据中心,但是却因为路由错误,进入了B城市,那看到的数据就是错的了。造成的结果,可能是用户看到的购买列表是空的,这是不能接受的。延时:异地部署,我们需要同步卖家的数据、商品的数据。能接受的延时必须要做到一秒内,即在全国的范围内,都必须做到一秒内把数据同步完中心之间骨干网。数据一致性:把用户操作封闭在一个单元内完成,最关键的是数据。在某个点,必须确保单行的数据在一个地方写,绝对不能在多个地方写。为了做到这一点,必须确定数据的维度。淘宝除了用户本身的信息以外,还会看到所有商品的数据、所有卖家的数据,面对的是买家、卖家和商品三个维度。因为异地的是买家的核心链路,所以选择买家这个维度。按买家维度来切分数据。但因为有三个维度的数据,当操作卖家、商品数据时,就无法封闭。在所有的异地多活项目中,最重要的是保障某个点写进去的数据一定是正确的。这是最大的挑战,也是我们在设计整个方案中的第一原则。业务这一层出故障我们都可以接受,但是不能接受数据故障。多个单元之间一定会有数据同步。一方面,每个单元都需要卖家的数据、商品的数据;另一方面,我们的单元不是全量业务,那一定会有业务需要这个单元,比如说买家在这个单元下了一笔定单,而其他业务有可能也是需要这笔数据,否则可能操作不了,所以需要同步该数据。所以怎样确保每个单元之间的商品、卖家的数据是一致的,然后买家数据中心和单元是一致的,这是非常关键的。总结各种方案都是针对不同的业务场景设计的,所以会有一定的不同,但是基本思路都是一致的。通过各种手段避免进行跨机房调用,消除延迟,让用户无感知。必要的时候通过业务的妥协,牺牲一致性来获取更高的可用性和更低的部署复杂程度。细读CAP理论就知道,这个问题是不存在完美的解决方案的,只有尽量贴合业务,逐渐迭代出更合适的方案。引用:异地多活设计辣么难?其实是你想多了!饿了么异地多活技术实现(一)总体介绍微博“异地多活”部署经验谈绝对干货:解密阿里巴巴“异地多活”技术阿里和微博的异地多活方案zt