搜索到
785
篇与
的结果
-
 Nginx几款负载均衡第三方插件的安装与使用 Nginx几款负载均衡第三方插件的安装与使用0x01:插件说明nginx_upstream_hash :url_hash是nginx的第三方模块,nginx本身不支持,需要第三方模块。nginx在做负载均衡的时, 把转发的URL以hash的形式保存。这样可以保证同一个URL始终分给同一个real server,来提高访问速度。 ** 官网:https://github.com/evanmiller/nginx_upstream_hashnginx-upstream-fair :upstream-fair是比内建的负载均衡更加智能的负载均衡模块, 它采用的不是内建负载均衡使用的轮换的均衡算法,而是可以根据页面大小、加载时间长短智能的进行负载均衡。 官网:https://github.com/gnosek/nginx-upstream-fairngx_http_consistent_hash : 通过一致性哈希算法来选择合适的后端节点 官网:https://github.com/replay/ngx_http_consistent_hashhttps://www.nginx.com/resources/wiki/modules/consistent_hash/0x02:安装说明先分别下载这三款插件wget https://github.com/gnosek/nginx-upstream-fair/archive/master.zip -O nginx-upstream-fair.zip wget https://github.com/evanmiller/nginx_upstream_hash/archive/master.zip -O nginx_upstream_hash.zip wget https://github.com/replay/ngx_http_consistent_hash/archive/master.zip -O ngx_http_consistent_hash.zip解压对应的压缩包unzip nginx-upstream-fair-master.zip unzip nginx_upstream_hash-master.zip unzip ngx_http_consistent_hash-master.zip 查看旧Nginx的安装配置参数 /usr/local/nginx/sbin/nginx -V重新编译添加负载均衡模块./configure --prefix=/usr/local/nginx \ --user=nginx --group=nginx \ --with-http_secure_link_module \ --with-http_stub_status_module \ --with-stream_ssl_preread_module \ --with-http_ssl_module --with-http_image_filter_module \ --add-module=/home/huangjinjin/桌面/fastfds/nginx_upstream_hash-master \ --add-module=/home/huangjinjin/桌面/fastfds/nginx-upstream-fair-master \ --add-module=/home/huangjinjin/桌面/fastfds/ngx_http_consistent_hash-master关键编译参数如--add-module=nginx_upstream_hash-master文件夹安装nginxmake(1) 对于nginx_upstream_hash会出现以下错误ngx_http_upstream_hash_module 的多重定义 说明Nginx内部包含了一个同名的模块。需要对nginx_upstream_hash进行一定的代码修改,ngx_http_upstream_hash_module定义到nginx_upstream_hash-master目录修改ngx_http_upstream_hash_modulengx_module_t ngx_http_upstream_hash_module = { NGX_MODULE_V1, &ngx_http_upstream_hash_module_ctx, /* module context */ ngx_http_upstream_hash_commands, /* module directives */ NGX_HTTP_MODULE, /* module type */ NULL, /* init master */ NULL, /* init module */ NULL, /* init process */ NULL, /* init thread */ NULL, /* exit thread */ NULL, /* exit process */ NULL, /* exit master */ NGX_MODULE_V1_PADDING };修改成ngx_module_t ngx_http_upstream_hash_module_ext = { NGX_MODULE_V1, &ngx_http_upstream_hash_module_ctx, /* module context */ ngx_http_upstream_hash_commands, /* module directives */ NGX_HTTP_MODULE, /* module type */ NULL, /* init master */ NULL, /* init module */ NULL, /* init process */ NULL, /* init thread */ NULL, /* exit thread */ NULL, /* exit process */ NULL, /* exit master */ NGX_MODULE_V1_PADDING };应用这个结构体的代码一并修改。搜索ngx_http_upstream_hash_module改成ngx_http_upstream_hash_module_ext修改config配置文件ngx_addon_name=ngx_http_upstream_hash_module_ext HTTP_MODULES="$HTTP_MODULES ngx_http_upstream_hash_module_ext" NGX_ADDON_SRCS="$NGX_ADDON_SRCS $ngx_addon_dir/ngx_http_upstream_hash_module_ext.c" have=NGX_HTTP_UPSTREAM_HASH . auto/have ~ c文件名字也改下ngx_http_upstream_hash_module.c 改成 ngx_http_upstream_hash_module_ext.c 这样 重新configure和make 才能成功(2)对于nginx-upstream-fair会出现以下错误nginx-upstream-fair/ngx_http_upstream_fair_module.c:543:28: error: ‘ngx_http_upstream_srv_conf_t’ has no member named ‘default_port’到nginx源码目录找到src/http/ngx_http_upstream.h文件 ngx_http_upstream_srv_conf_s结构添加in_port_t default_port;经过错误修复,编译成功后,把objs目录下的nginx文件拷贝到/usr/local/nginx目录即可:cp ./objs/nginx /usr/local/nginx0x03: 基本语法nginx_upstream_hashupstream backend_server { server 127.0.0.1:5000; server 127.0.0.1:5001; server 127.0.0.1:5002; hash $request_uri; hash_again 10; # default 0 }nginx-upstream-fairupstream mongrel { fair; server 127.0.0.1:5000; server 127.0.0.1:5001; server 127.0.0.1:5002; }ngx_http_consistent_hashupstream somestream { consistent_hash $request_uri; server 127.0.0.1:5000; server 127.0.0.1:5001; server 127.0.0.1:5002; }以下三种任君选择,不过nginx_upstream_hash与nginx-upstream-fair已经很久没更新了。
Nginx几款负载均衡第三方插件的安装与使用 Nginx几款负载均衡第三方插件的安装与使用0x01:插件说明nginx_upstream_hash :url_hash是nginx的第三方模块,nginx本身不支持,需要第三方模块。nginx在做负载均衡的时, 把转发的URL以hash的形式保存。这样可以保证同一个URL始终分给同一个real server,来提高访问速度。 ** 官网:https://github.com/evanmiller/nginx_upstream_hashnginx-upstream-fair :upstream-fair是比内建的负载均衡更加智能的负载均衡模块, 它采用的不是内建负载均衡使用的轮换的均衡算法,而是可以根据页面大小、加载时间长短智能的进行负载均衡。 官网:https://github.com/gnosek/nginx-upstream-fairngx_http_consistent_hash : 通过一致性哈希算法来选择合适的后端节点 官网:https://github.com/replay/ngx_http_consistent_hashhttps://www.nginx.com/resources/wiki/modules/consistent_hash/0x02:安装说明先分别下载这三款插件wget https://github.com/gnosek/nginx-upstream-fair/archive/master.zip -O nginx-upstream-fair.zip wget https://github.com/evanmiller/nginx_upstream_hash/archive/master.zip -O nginx_upstream_hash.zip wget https://github.com/replay/ngx_http_consistent_hash/archive/master.zip -O ngx_http_consistent_hash.zip解压对应的压缩包unzip nginx-upstream-fair-master.zip unzip nginx_upstream_hash-master.zip unzip ngx_http_consistent_hash-master.zip 查看旧Nginx的安装配置参数 /usr/local/nginx/sbin/nginx -V重新编译添加负载均衡模块./configure --prefix=/usr/local/nginx \ --user=nginx --group=nginx \ --with-http_secure_link_module \ --with-http_stub_status_module \ --with-stream_ssl_preread_module \ --with-http_ssl_module --with-http_image_filter_module \ --add-module=/home/huangjinjin/桌面/fastfds/nginx_upstream_hash-master \ --add-module=/home/huangjinjin/桌面/fastfds/nginx-upstream-fair-master \ --add-module=/home/huangjinjin/桌面/fastfds/ngx_http_consistent_hash-master关键编译参数如--add-module=nginx_upstream_hash-master文件夹安装nginxmake(1) 对于nginx_upstream_hash会出现以下错误ngx_http_upstream_hash_module 的多重定义 说明Nginx内部包含了一个同名的模块。需要对nginx_upstream_hash进行一定的代码修改,ngx_http_upstream_hash_module定义到nginx_upstream_hash-master目录修改ngx_http_upstream_hash_modulengx_module_t ngx_http_upstream_hash_module = { NGX_MODULE_V1, &ngx_http_upstream_hash_module_ctx, /* module context */ ngx_http_upstream_hash_commands, /* module directives */ NGX_HTTP_MODULE, /* module type */ NULL, /* init master */ NULL, /* init module */ NULL, /* init process */ NULL, /* init thread */ NULL, /* exit thread */ NULL, /* exit process */ NULL, /* exit master */ NGX_MODULE_V1_PADDING };修改成ngx_module_t ngx_http_upstream_hash_module_ext = { NGX_MODULE_V1, &ngx_http_upstream_hash_module_ctx, /* module context */ ngx_http_upstream_hash_commands, /* module directives */ NGX_HTTP_MODULE, /* module type */ NULL, /* init master */ NULL, /* init module */ NULL, /* init process */ NULL, /* init thread */ NULL, /* exit thread */ NULL, /* exit process */ NULL, /* exit master */ NGX_MODULE_V1_PADDING };应用这个结构体的代码一并修改。搜索ngx_http_upstream_hash_module改成ngx_http_upstream_hash_module_ext修改config配置文件ngx_addon_name=ngx_http_upstream_hash_module_ext HTTP_MODULES="$HTTP_MODULES ngx_http_upstream_hash_module_ext" NGX_ADDON_SRCS="$NGX_ADDON_SRCS $ngx_addon_dir/ngx_http_upstream_hash_module_ext.c" have=NGX_HTTP_UPSTREAM_HASH . auto/have ~ c文件名字也改下ngx_http_upstream_hash_module.c 改成 ngx_http_upstream_hash_module_ext.c 这样 重新configure和make 才能成功(2)对于nginx-upstream-fair会出现以下错误nginx-upstream-fair/ngx_http_upstream_fair_module.c:543:28: error: ‘ngx_http_upstream_srv_conf_t’ has no member named ‘default_port’到nginx源码目录找到src/http/ngx_http_upstream.h文件 ngx_http_upstream_srv_conf_s结构添加in_port_t default_port;经过错误修复,编译成功后,把objs目录下的nginx文件拷贝到/usr/local/nginx目录即可:cp ./objs/nginx /usr/local/nginx0x03: 基本语法nginx_upstream_hashupstream backend_server { server 127.0.0.1:5000; server 127.0.0.1:5001; server 127.0.0.1:5002; hash $request_uri; hash_again 10; # default 0 }nginx-upstream-fairupstream mongrel { fair; server 127.0.0.1:5000; server 127.0.0.1:5001; server 127.0.0.1:5002; }ngx_http_consistent_hashupstream somestream { consistent_hash $request_uri; server 127.0.0.1:5000; server 127.0.0.1:5001; server 127.0.0.1:5002; }以下三种任君选择,不过nginx_upstream_hash与nginx-upstream-fair已经很久没更新了。 -
yum安装nginx没有某一模块,该如何添加第三方模块? yum安装nginx没有某一模块,该如何添加第三方模块?本文将以添加--with-stream模块为例,演示如何去添加新的模块进去。需求:生产有个接口是通过socket通信。nginx1.9开始支持tcp层的转发,通过stream实现的,而socket也是基于tcp通信。实现方法:Centos7.5下yum直接安装的nginx,添加新模块支持tcp转发; 重新编译Nginx并添加--with-stream参数。 实现过程:1.查看nginx版本模块nginx -Vnginx version: nginx/1.20.1 built by gcc 4.8.5 20150623 (Red Hat 4.8.5-44) (GCC) built with OpenSSL 1.1.1g FIPS 21 Apr 2020 TLS SNI support enabled configure arguments: --prefix=/usr/share/nginx --sbin-path=/usr/sbin/nginx --modules-path=/usr/lib64/nginx/modules --conf-path=/etc/nginx/nginx.conf --error-log-path=/var/log/nginx/error.log --http-log-path=/var/log/nginx/access.log --http-client-body-temp-path=/var/lib/nginx/tmp/client_body --http-proxy-temp-path=/var/lib/nginx/tmp/proxy --http-fastcgi-temp-path=/var/lib/nginx/tmp/fastcgi --http-uwsgi-temp-path=/var/lib/nginx/tmp/uwsgi --http-scgi-temp-path=/var/lib/nginx/tmp/scgi --pid-path=/run/nginx.pid --lock-path=/run/lock/subsys/nginx --user=nginx --group=nginx --with-compat --with-debug --with-file-aio --with-google_perftools_module --with-http_addition_module --with-http_auth_request_module --with-http_dav_module --with-http_degradation_module --with-http_flv_module --with-http_gunzip_module --with-http_gzip_static_module --with-http_image_filter_module=dynamic --with-http_mp4_module --with-http_perl_module=dynamic --with-http_random_index_module --with-http_realip_module --with-http_secure_link_module --with-http_slice_module --with-http_ssl_module --with-http_stub_status_module --with-http_sub_module --with-http_v2_module --with-http_xslt_module=dynamic --with-mail=dynamic --with-mail_ssl_module --with-pcre --with-pcre-jit --with-stream=dynamic --with-stream_ssl_module --with-stream_ssl_preread_module --with-threads --with-cc-opt='-O2 -g -pipe -Wall -Wp,-D_FORTIFY_SOURCE=2 -fexceptions -fstack-protector-strong --param=ssp-buffer-size=4 -grecord-gcc-switches -specs=/usr/lib/rpm/redhat/redhat-hardened-cc1 -m64 -mtune=generic' --with-ld-opt='-Wl,-z,relro -specs=/usr/lib/rpm/redhat/redhat-hardened-ld -Wl,-E'2.下载一个同版本可编译的nginxcd /opt wget http://nginx.org/download/nginx-1.20.1.tar.gz tar xf nginx-1.20.1.tar.gz && cd nginx-1.20.13.备份原nginx文件mv /usr/sbin/nginx /usr/sbin/nginx.bak cp -r /etc/nginx{,.bak}4.重新编译nginx检查模块是否支持,比如这次添加 limit 限流模块 和 stream 模块:./configure --help | grep limit --without-http_limit_conn_module disable ngx_http_limit_conn_module --without-http_limit_req_module disable ngx_http_limit_req_module --without-stream_limit_conn_module disable ngx_stream_limit_conn_moduleps:-without-http_limit_conn_module disable 表示已有该模块 ,编译时,不需要添加./configure –help | grep stream --without-http_upstream_hash_module disable ngx_http_upstream_hash_module --without-http_upstream_ip_hash_module disable ngx_http_upstream_ip_hash_module --without-http_upstream_least_conn_module disable ngx_http_upstream_least_conn_module --without-http_upstream_random_module disable ngx_http_upstream_random_module --without-http_upstream_keepalive_module disable ngx_http_upstream_keepalive_module --without-http_upstream_zone_module disable ngx_http_upstream_zone_module --with-stream enable TCP/UDP proxy module --with-stream=dynamic enable dynamic TCP/UDP proxy module --with-stream_ssl_module enable ngx_stream_ssl_module --with-stream_realip_module enable ngx_stream_realip_module --with-stream_geoip_module enable ngx_stream_geoip_module --with-stream_geoip_module=dynamic enable dynamic ngx_stream_geoip_module --with-stream_ssl_preread_module enable ngx_stream_ssl_preread_module --without-stream_limit_conn_module disable ngx_stream_limit_conn_module --without-stream_access_module disable ngx_stream_access_module --without-stream_geo_module disable ngx_stream_geo_module --without-stream_map_module disable ngx_stream_map_module --without-stream_split_clients_module disable ngx_stream_split_clients_module --without-stream_return_module disable ngx_stream_return_module --without-stream_set_module disable ngx_stream_set_module --without-stream_upstream_hash_module disable ngx_stream_upstream_hash_module --without-stream_upstream_least_conn_module disable ngx_stream_upstream_least_conn_module --without-stream_upstream_random_module disable ngx_stream_upstream_random_module --without-stream_upstream_zone_module disable ngx_stream_upstream_zone_moduleps:–with-stream enable 表示不支持 ,编译时要自己添加该模块根据第1步查到已有的模块,加上本次需新增的模块:--with-streamcd /opt/nginx-1.20.1 ./configure --prefix=/usr/share/nginx --sbin-path=/usr/sbin/nginx --modules-path=/usr/lib64/nginx/modules --conf-path=/etc/nginx/nginx.conf --error-log-path=/var/log/nginx/error.log --http-log-path=/var/log/nginx/access.log --http-client-body-temp-path=/var/lib/nginx/tmp/client_body --http-proxy-temp-path=/var/lib/nginx/tmp/proxy --http-fastcgi-temp-path=/var/lib/nginx/tmp/fastcgi --http-uwsgi-temp-path=/var/lib/nginx/tmp/uwsgi --http-scgi-temp-path=/var/lib/nginx/tmp/scgi --pid-path=/run/nginx.pid --lock-path=/run/lock/subsys/nginx --user=nginx --group=nginx --with-file-aio --with-ipv6 --with-http_auth_request_module --with-http_ssl_module --with-http_v2_module --with-http_realip_module --with-http_addition_module --with-http_xslt_module=dynamic --with-http_image_filter_module=dynamic --with-http_geoip_module=dynamic --with-http_sub_module --with-http_dav_module --with-http_flv_module --with-http_mp4_module --with-http_gunzip_module --with-http_gzip_static_module --with-http_random_index_module --with-http_secure_link_module --with-http_degradation_module --with-http_slice_module --with-http_stub_status_module --with-http_perl_module=dynamic --with-mail=dynamic --with-mail_ssl_module --with-pcre --with-pcre-jit --with-stream=dynamic --with-stream_ssl_module --with-debug --with-stream以上编译时,如出现缺少依赖,一般需要安装以下模块,安装完再次编译:yum -y install libxml2 libxml2-dev libxslt-devel yum -y install gd-devel yum -y install perl-devel perl-ExtUtils-Embed yum -y install GeoIP GeoIP-devel GeoIP-data yum -y install pcre-devel yum -y install openssl openssl-devel yum -y install gcc 5.编译通过,继续验证继续输入:makemake完成后不要继续输入make install,以免现在的nginx出现问题。以上完成后,会在objs目录下生成一个nginx文件,先验证:/opt/nginx-1.12.2/objs/nginx -t /opt/nginx-1.12.2/objs/nginx -V6.替换Nginx文件并重启cp /opt/nginx-1.12.2/objs/nginx /usr/sbin/ nginx -s reload7.检查nginx -Vnginx version: nginx/1.20.1 built by gcc 4.8.5 20150623 (Red Hat 4.8.5-44) (GCC) built with OpenSSL 1.0.2k-fips 26 Jan 2017 TLS SNI support enabled configure arguments: --prefix=/usr/share/nginx --sbin-path=/usr/sbin/nginx --modules-path=/usr/lib64/nginx/modules --conf-path=/etc/nginx/nginx.conf --error-log-path=/var/log/nginx/error.log --http-log-path=/var/log/nginx/access.log --http-client-body-temp-path=/var/lib/nginx/tmp/client_body --http-proxy-temp-path=/var/lib/nginx/tmp/proxy --http-fastcgi-temp-path=/var/lib/nginx/tmp/fastcgi --http-uwsgi-temp-path=/var/lib/nginx/tmp/uwsgi --http-scgi-temp-path=/var/lib/nginx/tmp/scgi --pid-path=/run/nginx.pid --lock-path=/run/lock/subsys/nginx --user=nginx --group=nginx --with-file-aio --with-ipv6 --with-http_auth_request_module --with-http_ssl_module --with-http_v2_module --with-http_realip_module --with-http_addition_module --with-http_xslt_module=dynamic --with-http_image_filter_module=dynamic --with-http_geoip_module=dynamic --with-http_sub_module --with-http_dav_module --with-http_flv_module --with-http_mp4_module --with-http_gunzip_module --with-http_gzip_static_module --with-http_random_index_module --with-http_secure_link_module --with-http_degradation_module --with-http_slice_module --with-http_stub_status_module --with-http_perl_module=dynamic --with-mail=dynamic --with-mail_ssl_module --with-pcre --with-pcre-jit --with-stream=dynamic --with-stream_ssl_module --with-debug --with-stream新添加的模块在最后,添加模块成功。
-
Google 代码审查指南 Google 代码审查指南简介代码审查是除了代码作者之外,其他人检查代码的过程。 Google 通过 Code Review 来维护代码和产品质量。此文档是 Google Code Review 流程和政策的规范说明。 Google Code Review有两套文档:代码审查者指南:针对代码审查者的详细指南。代码开发者指南:针对 CL 开发者的的详细指南。背景Google 有许多通用工程实践,几乎涵盖所有语言和项目。此文档为长期积累的最佳实践,是集体经验的结晶。我们尽可能地将其公之于众,您的组织和开源项目也会从中受益。术语文档中使用了 Google 内部术语,在此为外部读者澄清:CL:代表“变更列表(changelist)” ,表示已提交到版本控制或正在进行代码审查的自包含更改。有的组织会将其称为“变更(change)”或“补丁(patch)”。LGTM:意思是“我觉得不错(Looks Good to Me)” 。这是批准 CL 时代码审查者所说的。代码审查者应该关注哪些方面?代码审查时应该关注以下方面:设计:代码是否经过精心设计并适合您的系统?功能:代码的行为是否与作者的意图相同?代码是否可以正常响应用户的行为?复杂度:代码能更简单吗?将来其他开发人员能轻松理解并使用此代码吗?测试:代码是否具有正确且设计良好的自动化测试?命名:开发人员是否为变量、类、方法等选择了明确的名称?注释:评论是否清晰有用?风格:代码是否遵守了风格指南?文档:开发人员是否同时更新了相关文档?选择最合适审查者一般而言,您希望找到能在合理的时间内回复您的评论的最合适的审查者。最合适的审查者应该是 能彻底了解和审查您代码的人 。他们 通常是代码的所有者,可能是 OWNERS 文件中的人,也可能不是。 有时 CL 的不同部分可能需要不同的人审查。如果您找到了理想的审查者但他们又没空,那您也至少要抄送他们。面对面审查如果您与有资格做代码审查的人一起结对编程了一段代码,那么该代码将被视为已审查。您还可以进行面对面的代码审查,审查者提问,CL 的开发人员作答。代码审查者指南这是基于过往经验编写的 Code Review 最佳方式建议。其中分为了很多独立的部分,共同组成完整的文档。虽然您不必阅读文档,但通读一遍会对您自己和团队很有帮助。Code Review 标准代码审查的主要目的是确保逐步改善 Google 代码库的整体健康状况。代码审查的所有工具和流程都是为此而设计的。为了实现此目标,必须做出一系列权衡。首先,开发人员必须能够对任务进行 改进 。如果开发者从未向代码库提交过代码,那么代码库的改进也就无从谈起。此外,如果审核人员对代码吹毛求疵,那么开发人员以后也很难再做出改进。另外,审查者有责任确保随着时间的推移,CL 的质量不会使代码库的整体健康状况下降。这可能很棘手,因为通常情况下,代码库健康状况会随着时间的而下降,特别是在对团队有严格的时间要求时,团队往往会采取捷径来达成他们的目标。此外,审查者应对正在审核的代码负责并拥有所有权。审查者希望确保代码库保持一致、可维护及 Code Review 要点 中所提及的所有其他内容。因此,我们将以下规则作为 Code Review 中期望的标准:一般来说,审核人员应该倾向于批准 CL,只要 CL 确实可以提高系统的整体代码健康状态,即使 CL 并不完美。 这是所有 Code Review 指南中的 高级原则 。当然,也有一些限制。例如,如果 CL 添加了审查者认为系统中不需要的功能,那么即使代码设计良好,审查者依然可以拒绝批准它。此处有一个关键点就是没有“完美”的代码,只有 更好 的代码。审查者不该要求开发者在批准程序前仔细清理、润色 CL 每个角落。相反,审查者应该在变更的重要性与取得进展之间取得平衡。审查者不应该追求完美,而应是追求持续改进。不要因为一个 CL不是“完美的”,就将可以提高系统的可维护性、可读性和可理解性的 CL 延迟数天或数周才批准。审核者应该随时在可以改善的地方留下审核评论,但如果评论不是很重要,请在评论语句前加上“Nit:”之类的内容,让开发者知道这条评论是用来指出可以润色的地方,而他们可以选择是否忽略。注意:本文档中没有任何内容证明检查 CL 肯定会使系统的整体代码健康状况恶化。您会做这中事情应该只有在 紧急情况 时。指导代码审查具有向开发人员传授语言、框架或通用软件设计原则新内容的重要功能。留下评论可以帮助开发人员学习新东西 ,这总归是很好的。分享知识是随着长年累月改善系统代码健康状况的一部分。请记住, 如果您的评论纯粹是教育性的,且对于本文档中描述的标准并不重要,请在其前面添加“Nit:”或以其他方式表明作者不必在此 CL 中解决它。原则基于技术事实和数据否决意见和个人偏好。关于代码风格问题, 风格指南 是绝对权威。任何不在风格指南中的纯粹风格点(例如空白等)都是个人偏好的问题。代码风格应该与风格指南中的一致。如果没有以前的风格,请接受作者的风格。软件设计方面几乎不是纯粹的风格或个人偏好问题。软件设计基于基本原则且应该权衡这些原则,而不仅仅是个人意见。有时候会有多种有效的选择。如果作者可以证明(通过数据或基于可靠的工程原理)该方法同样有效,那么审查者应该接受作者的偏好。否则,就要取决于软件设计的标准原则。如果没有其他适用规则,则审查者可以要求作者与当前代码库中的内容保持一致,只要不恶化系统的整体代码健康状况即可。解决冲突如果在代码审查过程中有任何冲突,第一步应该始终是开发人员和审查者根据本文档中的 开发者指南和审查者指南 达成共识。当达成共识变得特别困难时,审阅者和开发者可以进行面对面的会议,或者有 VC 参与调停,而不仅仅是试着通过代码审查评论来解决冲突。 (但是,如果您这样做了,请确保在 CL 的评论中记录讨论结果,以供将来的读者使用。)如果这样还不能解决问题,那么解决该问题最常用方法是将问题升级。通常是将问题升级为更广泛的团队讨论,有一个 TL 权衡,要求维护人员对代码作出决定,或要求工程经理的帮助。 不要因为 CL 的开发者和审查者不能达成一致,就让 CL 在那里卡壳。Code Review 要点注意:在考虑这些要点时,请谨记 “ Code Review 标准 ”。设计审查中最重要的是 CL 的 整体设计。CL 中各种代码的交互是否有意义?此变更是属于您的代码库(codebase)还是属于库(library)?它是否与您系统的其他部分很好地集成?现在是添加此功能的好时机吗?功能这个 CL 是否符合开发者的意图?开发者的意图对代码的用户是否是好的? “用户”通常都是最终用户(当他们受到变更影响时)和开发者(将来必须“使用”此代码)。 大多数情况下,我们希望开发者能够很好地测试 CL,以便在审查时代码能够正常工作。但是,作为审查者,仍然应该考虑边缘情况,寻找并发问题,尝试像用户一样思考,并确保您单纯透过阅读方式审查时,代码没有包含任何 bug。当要检查 CL 的行为会对用户有重大影响时,验证 CL 的变化将变得十分重要。例如 UI 变更。当您只是阅读代码时,很难理解某些变更会如何影响用户。如果在 CL 中打 patch 或自行尝试这样的变更太不方便,您可以让开发人员为您提供功能演示。另一个在代码审查期间特别需要考虑功能的时机,就是如果 CL 中存在某种并行编程,理论上可能导致死锁或竞争条件。通过运行代码很难检测到这些类型的问题,并且通常需要某人(开发者和审查者)仔细思考它们以确保不会引入问题。 (请注意,这也是在可能出现竞争条件或死锁的情况下,不使用并发模型的一个很好的理由——它会使代码审查或理解代码变得非常复杂。)复杂度CL 是否已经超过它原本所必须的复杂度?针对任何层级的 CL 请务必确认这点——每行程序是否过于复杂? 功能太复杂了吗?类太复杂了吗? “太复杂”通常意味着“阅读代码的人无法快速理解。”也可能意味着“开发者在尝试调用或修改此代码时可能会引入错误。” 其中一种复杂性就是过度工程(over-engineering),如开发人员使代码过度通用,超过它原本所需的,或者添加系统当前不需要的功能 。审查者应特别警惕过度工程。未来的问题应该在它实际到达后解决,且届时才能更清晰的看到其真实样貌及在现实环境里的需求,鼓励开发人员解决他们现在需要解决的问题,而不是开发人员推测可能需要在未来解决的问题。测试将要求单元、集成或端到端测试视为应该做的适当变更。 通常,除非 CL 处理紧急情况,否则应在与生产代码相同的 CL 中添加测试。确保 CL 中的测试正确,合理且有用。测试并非用来测试自己本身,且我们很少为测试编写测试——人类必须确保测试有效。当代码被破坏时,测试是否真的会失败? 如果代码发生变化时,它们会开始产生误报吗? 每个测试都会做出简单而有用的断言吗? 不同测试方法的测试是否适当分开?请记住,测试也是必须维护的代码。不要仅仅因为它们不是主二进制文件的一部分而接受测试中的复杂性。命名开发人员是否为所有内容选择了好名字? 一个好名字应该足够长,可以完全传达项目的内容或作用,但又不会太长,以至于难以阅读。注释开发者是否用可理解的英语撰写了清晰的注释?所有注释都是必要的吗?通常,注释解释为什么某些代码存在时很有用,且不应该用来解释某些代码正在做什么。如果代码无法清楚到去解释自己时,那么代码应该变得更简单。有一些例外(正则表达式和复杂算法通常会从解释他们正在做什么事情的注释中获益很多),但大多数注释都是针对代码本身可能无法包含的信息,例如决策背后的推理。 查看此 CL 之前的注释也很有帮助。 也许有一个 TODO 现在可以删除,一个注释建议不要进行这种改变,等等。请注意,注释与类、模块或函数的文档不同,它们应该代表一段代码的目的,如何使用它,以及使用时它的行为方式。风格Google 提供了所有主要语言的风格指南,甚至包括大多数小众语言。确保 CL 遵循适当的风格指南。如果您想改进风格指南中没有的一些样式点,请在评论前加上“Nit:”,让开发人员知道这是您认为可改善代码的小瑕疵,但不是强制性的。不要仅根据个人风格偏好阻止提交 CL。CL 的作者不应在主要风格变更中,包括与其他种类的变更。它会使得很难看到 CL 中的变更了什么,使合并和回滚更复杂,并导致其他问题。例如,如果作者想要重新格式化整个文件,让他们只将重新格式化变为一个 CL,其后再发送另一个包含功能变更的 CL。文档如果 CL 变更了用户构建、测试、交互或发布代码的方式,请检查相关文档是否有更新,包括 README、g3doc 页面和任何生成的参考文档。 如果 CL 删除或弃用代码,请考虑是否也应删除文档。 如果缺少文档,请询问。每一行查看分配给您审查的每行代码。 有时如数据文件、生成的代码或大型数据结构等东西,您可以快速扫过。但不要快速扫过人类编写的类、函数或代码块,并假设其中的内容是 OK 的。显然,某些代码需要比其他代码更仔细的审查——这是您必须做出的判断——但您至少应该确定您理解所有代码正在做什么。如果您觉得这些代码太难以阅读了并减慢您审查的速度,您应该在您尝试继续审核前要让开发者知道这件事,并等待他们为程序做出解释、澄清。在 Google,我们聘请了优秀的软件工程师,您就是其中之一。如果您无法理解代码,那么很可能其他开发人员也不会。因此,当您要求开发人员澄清此代码时,您也会帮助未来的开发人员理解这些代码。如果您了解代码但觉得没有资格做某些部分的审查,请确保 CL 上有一个合格的审查人,特别是对于安全性、并发性、可访问性、国际化等复杂问题。上下文在广泛的上下文下查看 CL 通常很有帮助。 通常,代码审查工具只会显示变更的部分的周围的几行。有时您必须查看整个文件以确保变更确实有意义。例如,您可能只看到添加了四行新代码,但是当您查看整个文件时,您会看到这四行是添加在一个 50 行的方法里,现在确实需要将它们分解为更小的方法。在整个系统的上下文中考虑 CL 也很有用。 这个 CL 是否改善了系统的代码健康状况,还是使整个系统更复杂,测试更少等等?不要接受降低系统代码运行状况的 CL。大多数系统通过许多小的变化而变得复杂,因此防止新变更引入即便很小的复杂性也非常重要。好的事情如果您在 CL 中看到一些不错的东西,请告诉开发者,特别是当他们以一种很好的方式解决了您的的一个评论时。 代码审查通常只关注错误,但也应该为良好实践提供鼓励。在指导方面,比起告诉他们他们做错了什么,有时更有价值的是告诉开发人员他们做对了什么。总结在进行代码审查时,您应该确保:代码设计精良。该功能对代码用户是有好处的。任何 UI 变更都是合理的且看起来是好的。其中任何并行编程都是安全的。代码并不比它需要的复杂。开发人员没有实现他们将来可能需要,但不知道他们现在是否需要的东西。代码有适当的单元测试。测试精心设计。开发人员使用了清晰的名称。评论清晰有用,且大多用来解释为什么而不是做什么。代码有适当记录成文件(通常在 g3doc 中)。代码符合我们的风格指南。确保查看您被要求查看的每一行代码,查看上下文,确保您提高代码健康状况,并赞扬开发人员所做的好事。查看 CL 的步骤总结现在您已经知道了 Code Review 要点 ,那么管理分布在多个文件中的评论的最有效方法是什么?变更是否有意义?它有很好的描述吗?首先看一下变更中最重要的部分。整体设计得好吗?以适当的顺序查看 CL 的其余部分。第一步:全面了解变更查看 CL 描述 和 CL 大致上用来做什么事情。这种变更是否有意义?如果在最初不应该发生这样的变更,请立即回复,说明为什么不应该进行变更。当您拒绝这样的变更时,向开发人员建议应该做什么也是一个好主意。例如,您可能会说“看起来你已经完成一些不错的工作,谢谢!但实际上,我们正朝着删除您在这里修改的 FooWidget 系统的方向演进,所以我们不想对它进行任何新的修改。不过,您来重构下新的 BarWidget 类怎么样?“请注意,审查者不仅拒绝了当前的 CL 并提供了替代建议,而且他们保持礼貌地这样做。这种礼貌很重要,因为我们希望表明,即使不同意,我们也会相互尊重。如果您获得了多个您不想变更的 CL,您应该考虑重整开发团队的开发过程或外部贡献者的发布过程,以便在编写CL之前有更多的沟通。最好在他们完成大量工作之前说“不”,避免已经投入心血的工作现在必须被抛弃或彻底重写。第二步:检查 CL 的主要部分查找作为此 CL “主要”部分的文件。通常,包含大量的逻辑变更的文件就是 CL 的主要部分。先看看这些主要部分。这有助于为 CL 的所有较小部分提供上下文,并且通常可以加速代码审查。如果 CL 太大而无法确定哪些部分是主要部分,请向开发人员询问您应该首先查看的内容,或者要求他们将 CL 拆分为多个 CL(即后文“小型CL”) 。如果在该部分发现存在一些主要的设计问题时,即使没有时间立即查看 CL 的其余部分,也应立即留下评论告知此问题。因为事实上,因为该设计问题足够严重的话,继续审查其余部分很可能只是浪费宝贵的时间,因为其他正在审查的程序可能都将无关或消失。立即发送这些主要设计评论非常重要,有两个主要原因:通常开发者在发出 CL 后,在等待审查时立即开始基于该 CL 的新工作。如果您正在审查的 CL 中存在重大设计问题,那么他们以后的 CL 也必须要返工。您应该赶在他们在有问题的设计上做了太多无用功之前通知他们。主要的设计变更比起小的变更来说需要更长的时间才能完成。开发人员基本都有截止日期;为了完成这些截止日期并且在代码库中仍然保有高质量代码,开发人员需要尽快开始 CL 的任何重大工作。第三步:以适当的顺序查看 CL 的其余部分一旦您确认整个 CL 没有重大的设计问题,试着找出一个逻辑顺序来查看文件,同时确保您不会错过查看任何文件。 通常在查看主要文件之后,最简单的方法是按照代码审查工具向您提供的顺序浏览每个文件。有时在阅读主代码之前先阅读测试也很有帮助,因为这样您就可以了解该变更应当做些什么。Code Review 速度为什么尽快进行 Code Review?在Google,我们优化了开发团队共同开发产品的速度,而不是优化单个开发者编写代码的速度。个人开发的速度很重要,它并不如整个团队的速度那么重要。当代码审查很慢时,会发生以下几件事:整个团队的速度降低了。 是的,对审查没有快速响应的个人的确完成了其他工作。但是,对于团队其他人来说重要的新功能与缺陷修復将会被延迟数天、数周甚至数月,只因为每个 CL 正在等待审查和重新审查。开发者开始抗议代码审查流程。 如果审查者每隔几天只响应一次,但每次都要求对 CL 进行重大更改,那么开发者可能会变得沮丧。通常,开发者将表达对审查者过于“严格”的抱怨。如果审查者请求相同实质性更改(确实可以改善代码健康状况),但每次开发者进行更新时都会快速响应,则抱怨会逐渐消失。大多数关于代码审查流程的投诉实际上是通过加快流程来解决的。代码健康状况可能会受到影响。 如果审查速度很慢,则造成开发者提交不尽如人意的 CL 的压力会越来越大。审查太慢还会阻止代码清理、重构以及对现有 CL 的进一步改进。Code Review 应该有多快?如果您没有处于重点任务的中,那么您应该在收到代码审查后尽快开始。一个工作日是应该响应代码审查请求所需的最长时间(即第二天早上的第一件事)。遵循这些指导意味着典型的 CL 应该在一天内进行多轮审查(如果需要)。速度 vs. 中断有一种情况下个人速度胜过团队速度。 如果您正处于重点任务中,例如编写代码,请不要打断自己进行代码审查。 研究表明,开发人员在被打断后需要很长时间才能恢复到顺畅的开发流程中。因此,编写代码时打断自己实际上比让另一位开发人员等待代码审查的代价更加昂贵。相反,在回复审查请求之前,请等待工作中断点。可能是当你的当前编码任务完成,午餐后,从会议返回,从厨房回来等等。快速响应当我们谈论代码审查的速度时,我们关注的是响应时间,而不是 CL 需要多长时间才能完成整个审查并提交。理想情况下,整个过程也应该是快速的, 快速的个人响应比整个过程快速发生更为重要。 即使有时需要很久才能完成整个审查流程,但在整个过程中获得审查者的快速响应可以显着减轻开发人员对“慢速”代码审查感到的挫败感。如果您太忙而无法对 CL 进行全面审查,您仍然可以发送快速回复,让开发人员知道您什么时候可以开始,或推荐其他能够更快回复的审查人员,或者 提供一些大体的初步评论 。 (注意:这并不意味着您应该中断编码,即使发送这样的响应,也要在工作中的合理断点处发出响应。)重要的是,审查人员要花足够的时间进行审查,确信他们的“LGTM”意味着“此代码符合我们的标准。”但是,理想情况下,个人反应仍然应该很快。跨时区审查在处理时区差异时,尝试在他们还在办公室时回复作者。 如果他们已经下班回家了,那么请确保在第二天回到办公室之前完成审查。带评论的 LGTM为了加快代码审查,在某些情况下,即使他们也在 CL 上留下未解决的评论,审查者也应该给予 LGTM/Approval,这可以是以下任何一种情况:审查者确信开发人员将适当地处理所有审查者的剩余评论。其余的更改很小,不必由开发者完成。如果不清楚的话,审查者应该指定他们想要哪些选项。当开发者和审查者处于不同的时区时,带评论的 LGTM 尤其值得考虑,否则开发者将等待一整天才能获得 “LGTM,Approval”。大型 CL如果有人向您发送了代码审查太大,您不确定何时有时间查看,那么您应该要求开发者将 CL 拆分为几个较小的 CL 而不是一次审查的一个巨大的 CL。这通常可行,对审查者非常有帮助,即使需要开发人员的额外工作。如果 CL 无法分解为较小的 CL,并且您没有时间快速查看整个内容,那么至少要对 CL 的整体设计写一些评论并将其发送回开发人员以进行改进。作为审查者,您的目标之一应该在不牺牲代码健康状况的前提下,始终减少开发者能够快速采取某种进一步的操作的阻力。代码审查随时间推移而改进如果您遵循这些准则,并且您对代码审查非常严格,那么您应该会发现整个代码审核流程会随着时间的推移而变得越来越快。开发者可以了解健康代码所需的内容,并向您发送从一开始就很棒的 CL,且需要的审查时间越来越短。审查者学会快速响应,而不是在审查过程中添加不必要的延迟。但是,从长远来看, 不要为了提高想象中的代码审查速度,而在代码审查标准或质量方面妥协,实际上这样做对于长期来说不会有任何帮助。紧急情况还有一些紧急情况,CL 必须非常快速地通过整个审查流程,并且质量准则将放宽。请查看什么是紧急情况? 中描述的哪些情况属于紧急情况,哪些情况不属于紧急情况。如何撰写 Code Review 评论总结保持友善。解释你的推理。在给出明确的指示与只指出问题并让开发人员自己决定间做好平衡。鼓励开发人员简化代码或添加代码注释,而不仅仅是向你解释复杂性。礼貌一般而言,对于那些正在被您审查代码的人, 除了保持有礼貌且尊重以外,重要的是还要确保您(的评论)是非常清楚且有帮助的。 你并不总是必须遵循这种做法,但在说出可能令人不安或有争议的事情时你绝对应该使用它。 例如:糟糕的示例:“为什么这里你使用了线程,显然并发并没有带来什么好处?”好的示例:“这里的并发模型增加了系统的复杂性,但没有任何实际的性能优势,因为没有性能优势,最好是将这些代码作为单线程处理而不是使用多线程。”解释为什么关于上面的“好”示例,您会注意到的一件事是,它可以帮助开发人员理解您发表评论的原因。 并不总是需要您在审查评论中包含此信息,但有时候提供更多解释,对于表明您的意图,您在遵循的最佳实践,或为您建议如何提高代码健康状况是十分恰当的。给予指导一般来说,修复 CL 是开发人员的责任,而不是审查者。 您无需为开发人员详细设计解决方案或编写代码。但这并不意味着审查者应该没有帮助。一般来说,您应该在指出问题和提供直接指导之间取得适当的平衡。指出问题并让开发人员做出决定通常有助于开发人员学习,并使代码审查变得更容易。它还可能产生更好的解决方案,因为开发人员比审查者更接近代码。但是,有时直接说明,建议甚至代码会更有帮助。 代码审查的主要目标是尽可能获得最佳 CL。第二个目标是提高开发人员的技能,以便他们随着时间的推移需要的审查越来越少。接受解释如果您要求开发人员解释一段您不理解的代码,那通常会导致他们更清楚地重写代码。 偶尔,在代码中添加注释也是一种恰当的响应,只要它不仅仅是解释过于复杂的代码。仅在代码审查工具中编写的解释对未来的代码阅读者没有帮助。这仅在少数情况下是可接受的,例如当您查看一个您不熟悉的领域时,开发人员会用来向您解释普通读者已经知道的内容。处理 Code Review 中的抵触有时开发人员会拖延(Pushback)代码审查。他们要么不同意您的建议,要么抱怨您太严格。谁是对的?当开发人员不同意您的建议时,请先花点时间考虑一下是否正确。通常,他们比你更接近代码,所以他们可能真的对它的某些方面有更好的洞察力。他们的论点有意义吗?从代码健康的角度来看它是否有意义?如果是这样,让他们知道他们是对的,把问题解决。但是,开发人员并不总是对的。在这种情况下,审查人应进一步解释为什么认为他们的建议是正确的。好的解释在描述对开发人员回复的理解的同时,还会解释为什么请求更改。特别是,当审查人员认为他们的建议会改善代码健康状况时,他们应该继续提倡更改,如果他们认为最终的代码质量改进能够证明所需的额外工作是合理的。提高代码健康状况往往只需很小的几步。有时需要几轮解释一个建议才能才能让对方真正理解你的用意。只要确保始终保持礼貌,让开发人员知道你有听到他们在说什么,只是你不同意该论点而已。沮丧的开发者审查者有时认为,如果审查者人坚持改进,开发人员会感到不安。有时候开发人员会感到很沮丧,但这样的感觉通常只会持续很短的时间,后来他们会非常感谢您在提高代码质量方面给他们的帮助。通常情况下,如果您在评论中表现得很有礼貌,开发人员实际上根本不会感到沮丧,这些担忧都仅存在于审核者心中而已。开发者感到沮丧通常更多地与评论的写作方式有关,而不是审查者对代码质量的坚持。稍后清理开发人员拖延的一个常见原因是开发人员(可以理解)希望完成任务。他们不想通过另一轮审查来完成该 CL。所以他们说会在以后的 CL 中清理一些东西,所以您现在应该 LGTM 这个 CL。一些开发人员非常擅长这一点,并会立即编写一个修复问题的后续 CL。但是,经验表明,在开发人员编写原始 CL 后,经过越长的时间这种清理发生的可能性就越小。实际上,通常除非开发人员在当前 CL 之后立即进行清理,否则它就永远不会发生。这不是因为开发人员不负责任,而是因为他们有很多工作要做,清理工作在其他工作中被丢失或遗忘。因此, 在代码进入代码库并“完成”之前,通常最好坚持让开发人员现在清理他们的 CL。让人们“稍后清理东西”是代码库质量退化的常见原因。 如果 CL 引入了新的复杂性,除非是紧急情况,否则必须在提交之前将其清除。如果 CL 暴露了相关的问题并且现在无法解决,那么开发人员应该将 bug 记录下来并分配给自己,避免后续被遗忘。又或者他们可以选择在程序中留下 TODO 的注释并连结到刚记录下的 bug。关于严格性的抱怨如果您以前有相当宽松的代码审查,并转而进行严格的审查,一些开发人员会抱怨得非常大声。通常提高代码审查的速度会让这些抱怨逐渐消失。有时,这些投诉可能需要数月才会消失,但最终开发人员往往会看到严格的代码审查的价值,因为他们会看到代码审查帮助生成的优秀代码。而且一旦发生某些事情时,最响亮的抗议者甚至可能会成为你最坚定的支持者,因为他们会看到审核变严格后所带来的价值。解决冲突如果上述所有操作仍无法解决您与开发人员之间的冲突,请参阅 “ Code Review 标准 ”以获取有助于解决冲突的指导和原则。代码开发者指南本节页面的内容为开发人员进行代码审查的最佳实践。这些指南可帮助您更快地完成审核并获得更高质量的结果。您不必全部阅读它们,但它们适用于每个 Google 开发人员,并且许阅读全文通常会很有帮助。写好 CL 描述CL 描述是进行了哪些更改以及为何更改的公开记录。 CL 将作为版本控制系统中的永久记录,可能会在长时期内被除审查者之外的数百人阅读。开发者将来会根据描述搜索您的 CL。有人可能会仅凭有关联性的微弱印象,但没有更多具体细节的情况下,来查找你的改动。如果所有重要信息都在代码而不是描述中,那么会让他们更加难以找到你的 CL 。首行正在做什么的简短摘要。完整的句子,使用祈使句。后面跟一个空行。CL 描述的第一行应该是关于这个 CL 是做什么的简短摘要,后面跟一个空白行。这是将来大多数的代码搜索者在浏览代码的版本控制历史时,最常被看到的内容,因此第一行应该提供足够的信息,以便他们不必阅读 CL 的整个描述就可以获得这个 CL 实际上是做了什么的信息。按照传统,CL 描述的第一行应该是一个完整的句子,就好像是一个命令(一个命令句)。例如,“Delete the FizzBuzz RPC and replace it with the new system.”而不是“Deleting the FizzBuzz RPC and replacing it with the new system.“ 但是,您不必把其余的描述写成祈使句。Body 是信息丰富的其余描述应该是提供信息的。可能包括对正在解决的问题的简要描述,以及为什么这是最好的方法。如果方法有任何缺点,应该提到它们。如果相关,请包括背景信息,例如错误编号,基准测试结果以及设计文档的链接。即使是小型 CL 也需要注意细节。在 CL 描述中提供上下文以供参照。糟糕的 CL 描述“Fix bug ”是一个不充分的 CL 描述。什么 bug?你做了什么修复?其他类似的不良描述包括:“Fix build.”“Add patch.”“Moving code from A to B.”“Phase 1.”“Add convenience functions.”“kill weird URLs.”其中一些是真正的 CL 描述。他们的作者可能认为自己提供了有用的信息,却没有达到 CL 描述的目的。好的 CL 描述以下是一些很好的描述示例。功能更新rpc:删除 RPC 服务器消息 freelist 上的大小限制。像 FIzzBuzz 这样的服务器有非常大的消息,并且可以从重用中受益。增大 freelist,添加一个 goroutine,缓慢释放 freelist 条目,以便空闲服务器最终释放所有 freelist 条目。前几个词描述了CL实际上做了什么。其余的描述讨论了正在解决的问题,为什么这是一个很好的解决方案,以及有关具体实现的更多信息。重构Construct a Task with a TimeKeeper to use its TimeStr and Now methods.Add a Now method to Task, so the borglet() getter method can be removed (which was only used by OOMCandidate to call borglet’s Now method). This replaces the methods on Borglet that delegate to a TimeKeeper.Allowing Tasks to supply Now is a step toward eliminating the dependency on Borglet. Eventually, collaborators that depend on getting Now from the Task should be changed to use a TimeKeeper directly, but this has been an accommodation to refactoring in small steps.Continuing the long-range goal of refactoring the Borglet Hierarchy.第一行描述了 CL 的作用以及改变。其余的描述讨论了具体的实现,CL 的背景,解决方案并不理想,以及未来的可能方向。它还解释了为什么正在进行此更改。需要上下文的 小 CLCreate a Python3 build rule for status.py.This allows consumers who are already using this as in Python3 to depend on a rule that is next to the original status build rule instead of somewhere in their own tree. It encourages new consumers to use Python3 if they can, instead of Python2, and significantly simplifies some automated build file refactoring tools being worked on currently.第一句话描述实际做了什么。其余的描述解释了为什么正在进行更改并为审查者提供了大量背景信息。在提交 CL 前审查描述CL 在审查期间可能会发生重大变更。在提交 CL 之前检查 CL 描述是必要的,以确保描述仍然反映了 CL 的作用。小型 CL为什么提交小型 CL?小且简单的 CL 是指审查更快。审查者更容易抽多次五分钟时间来审查小型 CL,而不是留出 30 分钟来审查一个大型 CL。审查得更彻底。如果是大的变更,审查者和提交者往往会因为大量细节的讨论翻来覆去而感到沮丧——有时甚至到了重要点被遗漏或丢失的程度。不太可能引入错误。 由于您进行的变更较少,您和您的审查者可以更轻松有效地推断 CL 的影响,并查看是否已引入错误。如果被拒绝,减少浪费的工作。 如果您写了一个巨大的 CL,您的评论者说整个 CL 的方向都错误了,你就浪费了很多精力和时间。更容易合并。 处理大型 CL 需要很长时间,在合并时会出现很多冲突,并且必须经常合并。更容易设计好。 打磨一个小变更的设计和代码健康状况比完善一个大变更的所有细节要容易得多。减少对审查的阻碍。 发送整体变更的自包含部分可让您在等待当前 CL 审核时继续编码。更简单的回滚。 大型 CL 更有可能触及在初始 CL 提交和回滚 CL 之间更新的文件,从而使回滚变得复杂(中间的 CL 也可能需要回滚)。请注意,审查者可以仅凭 CL 过大而自行决定完全拒绝您的变更。通常他们会感谢您的贡献,但要求您以某种方式将其 CL 改成一系列较小的变更。在您编写完变更后,或者需要花费大量时间来讨论为什么审查者应该接受您的大变更,这可能需要做很多工作。首先编写小型 CL 更容易。什么是小型 CL?一般来说, CL 的正确大小是自包含的变更 。这意味着:CL 进行了一项最小的变更,只解决了一件事。通常只是功能的一部分,而不是一个完整的功能。一般来说,因为编写过小的 CL 而犯错也比过大的 CL 犯错要好。与您的审查者讨论以确定可接受的大小。审查者需要了解的关于 CL 的所有内容(除了未来的开发)都在 CL 的描述、现有的代码库或已经审查过的 CL 中。对其用户和开发者来说,在签入 CL 后系统能继续良好的工作。CL 不会过小以致于其含义难以理解。如果您添加新 API,则应在同一 CL 中包含 API 的用法,以便审查者可以更好地了解 API 的使用方式。这也可以防止签入未使用的 API。关于多大算“太大”没有严格的规则。对于 CL 来说,100 行通常是合理的大小,1000 行通常太大,但这取决于您的审查者的判断。变更中包含的文件数也会影响其“大小”。一个文件中的 200 行变更可能没问题,但是分布在 50 个文件中通常会太大。请记住,尽管从开始编写代码开始就您就已经密切参与了代码,但审查者通常不清楚背景信息。对您来说,看起来像是一个可接受的大小的 CL 对您的审查者来说可能是压倒性的。如有疑问,请编写比您认为需要编写的要小的 CL。审查者很少抱怨收到过小的 CL 提交。什么时候大 CL 是可以的?在某些情况下,大变更也是可以接受的:您通常可以将整个文件的删除视为一行变更,因为审核人员不需要很长时间审核。有时一个大的 CL 是由您完全信任的自动重构工具生成的,而审查者的工作只是检查并确定想要这样的变更。但这些 CL 可以更大,尽管上面的一些警告(例如合并和测试)仍然适用。按文件拆分拆分 CL 的另一种方法是对文件进行分组,这些文件需要不同的审查者,否则就是自包含的变更。例如:您发送一个 CL 以修改协议缓冲区,另一个 CL 发送变更使用该原型的代码。您必须在代码 CL 之前提交 proto CL,但它们都可以同时进行审查。如果这样做,您可能希望通知两组审查者您编写的其他 CL,以便他们对您的变更具有更充足的上下文。另一个例子:你发送一个 CL 用于代码更改,另一个用于使用该代码的配置或实验;如果需要,这也更容易回滚,因为配置/实验文件有时会比代码变更更快地推向生产。分离出重构通常最好在功能变更或错误修复的单独 CL 中进行重构。例如,移动和重命名类应该与修复该类中的错误的 CL 不同。审查者更容易理解每个 CL 在单独时引入的更改。但是,修复本地变量名称等小清理可以包含在功能变更或错误修复 CL 中。如果重构大到包含在您当前的 CL 中,会使审查更加困难的话,需要开发者和审查者一起判断是否将其拆开。将相关的测试代码保存在同一个 CL 中避免将测试代码拆分为单独的 CL。验证代码修改的测试应该进入相同的 CL,即使它增加了代码行数。但是,独立的测试修改可以首先进入单独的 CL,类似于重构指南。包括:使用新测试验证预先存在的已提交代码。重构测试代码(例如引入辅助函数)。引入更大的测试框架代码(例如集成测试)。不要破坏构建如果您有几个相互依赖的 CL,您需要找到一种方法来确保在每次提交 CL 后整个系统能够继续运作。否则可能会在您的 CL 提交的几分钟内打破所有开发人员的构建(如果您之后的 CL 提交意外出错,时间可能会甚至更长)。如果不能让它足够小有时你会遇到看起来您的 CL 必须如此庞大,但这通常很少是正确的。习惯于编写小型 CL 的提交者几乎总能找到将功能分解为一系列小变更的方法。在编写大型 CL 之前,请考虑在重构 CL 之前是否可以为更清晰的实现铺平道路。与你的同伴聊聊,看看是否有人想过如何在小型 CL 中实现这些功能。如果以上的努力都失败了(这应该是非常罕见的),那么请在事先征得审查者的同意后提交大型 CL,以便他们收到有关即将发生的事情的警告。在这种情况下,做好完成审查过程需要很长一段时间的准备,对不引入错误保持警惕,并且在编写测试时要更下功夫。如何处理审查者的评论当您发送 CL 进行审查时,您的审查者可能会对您的 CL 发表一些评论。以下是处理审查者评论的一些有用信息。不是针对您审查的目标是保持代码库和产品的质量。当审查者对您的代码提出批评时,请将其视为在帮助您、代码库和 Google,而不是对您或您的能力的个人攻击。有时,审查者会感到沮丧并在评论中表达他们的挫折感。对于审查者来说,这不是一个好习惯,但作为开发人员,您应该为此做好准备。问问自己,“审查者试图与我沟通的建设性意见是什么?”然后像他们实际说的那样操作。永远不要愤怒地回应代码审查评论。这严重违反了专业礼仪且将永远存在于代码审查工具中。如果您太生气或恼火而无法好好的回应,那么请离开电脑一段时间,或者做一些别的事情,直到您感到平静,可以礼貌地回答。一般来说,如果审查者没有以建设性和礼貌的方式提供反馈,请亲自向他们解释。如果您无法亲自或通过视频通话与他们交谈,请向他们发送私人电子邮件。以友善的方式向他们解释您不喜欢的东西以及您希望他们以怎样不同的方式来做些什么。如果他们也以非建设性的方式回复此私人讨论,或者没有预期的效果,那么请酌情上报给您的经理。修复代码如果审查者说他们不了解您的代码中的某些内容,那么您的第一反应应该是澄清代码本身。 如果无法澄清代码,请添加代码注释,以解释代码存在的原因。 只有在想增加的注释看起来毫无意义时,您才能在代码审查工具中进行回复与解释。如果审查者不理解您的某些代码,那么代码的未来读者可能也不会理解。在代码审查工具中回复对未来的代码读者没有帮助,但澄清代码或添加代码注释确可以实实在在得帮助他们。自我反思编写 CL 可能需要做很多工作。在终于发送一个 CL 用于审查后,我们通常会感到满足的,认为它已经完成,并且非常确定不需要进一步的工作。这通常是令人满意的。因此,当审查者回复对可以改进的事情的评论时,很容易本能地认为评论是错误的,审查者正在不必要地阻止您,或者他们应该让您提交 CL。但是,无论您目前多么确定,请花一点时间退一步,考虑审查者是否提供有助于对代码库和对 Google 的有价值的反馈。您首先应该想到的应该是,“审查者是否正确?”如果您无法回答这个问题,那么审查者可能需要澄清他们的意见。如果您已经考虑过并且仍然认为自己是正确的,请随时回答一下为什么您的方法对代码库、用户和/或 Google 更好。通常,审查者实际上是在提供建议,他们希望您自己思考什么是最好的。您可能实际上对审阅者不知道的用户、代码库或 CL 有所了解。所以提供并告诉他们更多的上下文。通常,您可以根据技术事实在自己和审查者之间达成一些共识。解决冲突解决冲突的第一步应该是尝试与审查者达成共识。 如果您无法达成共识,请参阅“ 代码审查标准 ”,该标准提供了在这种情况下遵循的原则。
-
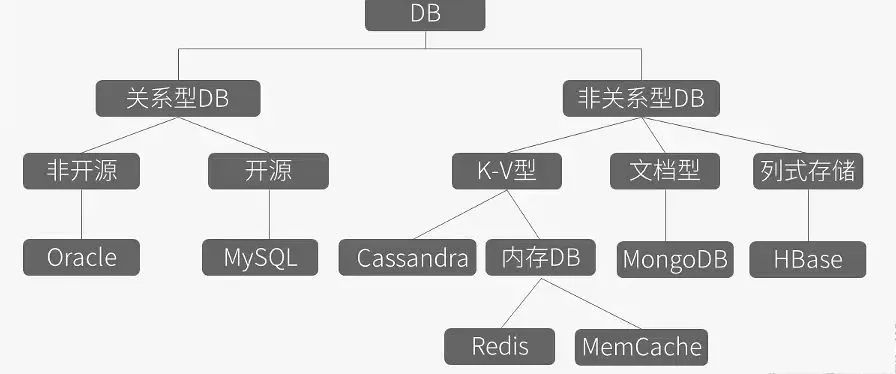
Nosql数据库服务之redis Nosql数据库服务之redis一图详解DB的分支产品Nosql数据库介绍是一种非关系型数据库服务,它能解决常规数据库的并发能力,比如传统的数据库的IO与性能的瓶颈,同样它是关系型数据库的一个补充,有着比较好的高效率与高性能。 专注于key-value查询的redis、memcached、ttserver解决以下问题1)对数据库的高并发读写需求2)大数据的高效存储和访问需求3)高可扩展性和高可用性的需求Nosql数据库的应用环境1)数据模型比较简单2)需要灵活性更强的IT系统3)对数据库的性能要求较高4)不需要高度数据一致性5)对于给定KEY,比较容易映射复杂值的环境Nosql软件的分类与特点1)key-value键值存储数据库(redis、memcached)用于内容缓存,适合负载并扩展大的数据集数据类型是一系列的键值对有快速查询功能,但存储数据少结构化对事务的支持不好,数据库故障产生时不可进行回滚2)列存储数据库(HBase)用于分布式的文件系统以列簇式存储,将同一列数据存在一起查找速度快,可扩展强,更容易进行分布式扩展功能相对局限3)面向文件的数据库(mongoDB)用于WEB应用较多数据类型是一系列键值对查询性能不高,没有统一的查询语法4)图形数据库(Graph)社交网络应用较多不容易做分布式的集群方案常用的Nosql数据库介绍1)memcached是一个开源高性能的,具有分布式内存对象的缓存系统特点1、安装布署简单2、支持高并发、高性能3、通过程序或负载均衡可以实现分布式4、仅为内存缓存,重启服务数据丢失官方网站:http://memcached.org2)memcacheDB是新浪基于memcached开发的一个开源项目,具备了事务恢复功能特点1、高并发读写2、高效存储3、高可用数据存储官方网站:http://memcachedb.org/benchmark.html生产环境如何选择Nosql数据库1、最常规的缓存应用,memcached最合适2、持久化存储方案memcacheDB3、2000万以内数据量的小数据用memcached4、大数据量可以用redisredis持久化数据服务REmote DIctionary server(redis)是一个基于key-value键值对的持久化数据库存储系统,对支持数据存储类型更多,包括字符串、列表、集合等 是一种持久化缓存服务,会周期的把更新的数据写入磁盘以及把修改操作记录追加到文件里记录下来,还支持主从同步模式,是一个开源的基于C语言编写的,支持网络、内存可持久化的日志型、key-value数据库 redis持久服务的特点key-value键值类型存储系统支持数据可靠存储单进程单线程高性能服务器恢复比较慢单机qps(秒并发)可以达到10W适合小数据高速读写访问redis存储系统优、缺点可以持久化存储数据支持每秒10W的读写频率支持丰富的数据类型所有操作都是原子性的支持异机主从复制内存管理开销大(低于物理内存的3/5)不同命令延迟差别大官方网站:http://www.redis.ioredis持久化介绍redis将数据存储于内存中,通过快照、日志两种方式实现持久化存储,前者性能高,会有数据丢失的情况,后者相反。 redis应用场景MYSQL+memcached网站架构的问题:数据量大就需要拆表,需要扩容,数据一致性是个问题1)最佳应用场景就是内存服务2)作为memcached替代方案3)对数据一致性有一定要求但不高的业务4)需要更多数据类型支持的业务5)需要主从同步及负载均衡的业务redis的安装要进行主从同步配置,可以实现故障切换,主上禁用数据持久化,从上配置,内存要够大[root@redis-m tools]# wget http://download.redis.io/releases/redis-2.8.24.tar.gz [root@redis-m tools]#tar zxf redis-2.8.24.tar.gz [root@redis-m tools]#cd redis-2.8.24 [root@redis-m redis-2.8.24]#make [root@redis-m redis-2.8.24]#make PREFIX=/application/redis-2.8.24 install [root@redis-m redis-2.8.24]#ln -s /application/redis-2.8.24 /application/redis [root@redis-m tools]# tree /application/redis /application/redis `-- bin |-- redis-benchmark #性能测试工具 |-- redis-check-aof #检测更新日志 |-- redis-check-dump #检查本地数据库rdb文件 |-- redis-cli #命令行客户端操作工具 |-- redis-sentinel -> redis-server `-- redis-server #服务的启动程序 ### 配置环境变量 [root@redis-m tools]# echo "PATH=/application/redis/bin:$PATH">>/etc/profile [root@redis-m tools]# source /etc/profile [root@redis-m tools]# which redis-server /application/redis/bin/redis-server查看帮助文档[root@redis-m tools]# redis-server --help Usage: ./redis-server [/path/to/redis.conf] [options] ./redis-server - (read config from stdin) ./redis-server -v or --version ./redis-server -h or --help ./redis-server --test-memory <megabytes> Examples: ./redis-server (run the server with default conf) ./redis-server /etc/redis/6379.conf ./redis-server --port 7777 ./redis-server --port 7777 --slaveof 127.0.0.1 8888 ./redis-server /etc/myredis.conf --loglevel verbose 启动服务[root@redis-m ~]# cd /application/redis/ [root@redis-m redis]# ll total 4 drwxr-xr-x 2 root root 4096 Mar 22 04:50 bin [root@redis-m redis]# mkdir conf [root@redis-m redis]# cp /download/tools/redis-2.8.24/redis.conf ./conf/ [root@redis-m redis]# redis-server /application/redis/conf/redis.conf & [6072] 22 Mar 05:00:51.373 # Server started, Redis version 2.8.24 [6072] 22 Mar 05:00:51.374 # WARNING overcommit_memory is set to 0! Background save may fail under low memory condition. To fix this issue add 'vm.overcommit_memory = 1' to /etc/sysctl.conf and then reboot or run the command 'sysctl vm.overcommit_memory=1' for this to take effect. #内存不足的时候,数据加载到磁盘可能失效,可以使用命令解决或修改配置文件 [6072] 22 Mar 05:00:51.375 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128. [6072] 22 Mar 05:00:51.375 * The server is now ready to accept connections on port 6379 [root@redis-m redis]# lsof -i :6379 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME redis-ser 6072 root 4u IPv6 24271 0t0 TCP *:6379 (LISTEN) redis-ser 6072 root 5u IPv4 24273 0t0 TCP *:6379 (LISTEN) vm.overcommit_memory 0表示用户空间请求更多内存时,内核尝试估算出余下可用内存 1表示内核允许最大限度的的使用内存关闭服务命令[root@redis-m redis]# redis-cli shutdown [6072] 22 Mar 05:09:32.699 # User requested shutdown... [6072] 22 Mar 05:09:32.699 * Saving the final RDB snapshot before exiting. [6072] 22 Mar 05:09:32.710 * DB saved on disk [6072] 22 Mar 05:09:32.711 # Redis is now ready to exit, bye bye... [1]+ Done redis-server /application/redis/conf/redis.conf拓展Linux下使用Redis教程
-
PHP常见算法 排序冒泡排序依次比较相邻的两个数,将比较小的数放在前面,比较大的数放在后面。$arr = [8,1,10,9,5,7]; function bubbleSort($arr){ // 外层 for 循环控制循环次数 for ($i=0; $i<count($arr) ; $i++) { //内层 for 循环进行两数交换,找每次的最大数,排到最后 for ($j=0; $j < count($arr)-1; $j++) { //数组里第一个和第二个对比,如果1>2,执行数值互换 if($arr[$j] >$arr[$j+1]){ $x = $arr[$j]; //第一赋给一个变量 $arr[$j] = $arr[$j+1]; //第二赋给第一 $arr[$j+1] = $x; //把变量给第二,结果就是1,2的数值互换 // $a=10; // $b=20; // $x=$a; $x=10 // $a=$b; $a=20 // $b=$X; $b=10 } } } return $arr; } print_r(bubbleSort($arr));快速排序快速排序是对冒泡排序的一种改进。设置一个基准元素,通过排序将需要排序的数据分割成两个部分,其中一部分的所有数据比基准元素小,另一部分的所有数据比基准元素大,然后对这两部分数据分别进行递归快速排序,最后将得到的数据和基准元素进行合并,就得到了所需数据。$arr = [8,1,10,9,5,7]; function quickSort($arr){ $lenth = count($arr);//获取数组个数 if($lenth <= 1){//小于等于一个不用往下走了 return $arr; } //选择基准元素。一般选第一个或最后一个 $first = $arr[0]; $left = array();//接收小于基准元素的值 $right = array();//接收大于基准元素的值 //循环从1开始,因为基准元素是0 for($i=1;$i<$lenth;$i++){ if($arr[$i]<$first){//小于基准元素的值 $left[] = $arr[$i]; }else{//大于基准元素的值 $right[] = $arr[$i]; } } //递归排序 $left = quickSort($left); $right = quickSort($right); //合并返回数组 return array_merge($left,array($first),$right); } print_r(quickSort($arr));选择排序1.找到数组中最小的元素,拎出来,将它和数组的第一个元素交换位置; 2.在剩下的元素中继续寻找最小的元素,拎出来,和数组的第二个元素交换位置; 3.如此循环,直到整个数组排序完成。$arr = [8,1,10,9,5,7]; function selectSort($arr){ //实现思路 双重循环完成,外层控制轮数,当前的最小值。内层 控制的比较次数,$i 当前最小值的位置, 需要参与比较的元素 for($i=0, $len=count($arr); $i<$len-1; $i++){ //先假设最小的值的位置 $p = $i; //$j 当前都需要和哪些元素比较,$i 后边的。 for($j=$i+1; $j<$len; $j++) { //$arr[$p] 是 当前已知的最小值 if($arr[$p] > $arr[$j]){ //比较,发现更小的,记录下最小值的位置;并且在下次比较时,应该采用已知的最小值进行比较。 $p = $j; } } //已经确定了当前的最小值的位置,保存到$p中。如果发现 最小值的位置与当前假设的位置$i不同,则位置互换即可。 if($p != $i){ $tmp = $arr[$p]; $arr[$p] = $arr[$i]; $arr[$i] = $tmp; } } return $arr; } print_r(selectSort($arr));插入排序每次将一个待排序的数据元素,插入到前面已经排好序的数列中的适当位置,使数列依然有序;直到待排序数据元素全部插入完为止。$arr = [8,1,10,9,5,7]; function insertSort($arr){ $count = count($arr); for($i=1; $i<$count; $i++){ $tmp = $arr[$i]; $j = $i - 1; while(isset($arr[$j]) && $arr[$j] > $tmp){ $arr[$j+1] = $arr[$j]; $arr[$j] = $tmp; $j--; } } return $arr; } print_r(insertSort($arr));希尔排序希尔排序(Shell Sort)是插入排序的一种,它是针对直接插入排序算法的改进。该方法又称缩小增量排序,因DL.Shell于1959年提出而得名。希尔排序实质上是一种分组插入方法。它的基本思想是:对于n个待排序的数列,取一个小于n的整数gap(gap被称为步长)将待排序元素分成若干个组子序列,所有距离为gap的倍数的记录放在同一个组中;然后,对各组内的元素进行直接插入排序。 这一趟排序完成之后,每一个组的元素都是有序的。然后减小gap的值,并重复执行上述的分组和排序。重复这样的操作,当gap=1时,整个数列就是有序的。$arr = [8,1,10,9,5,7]; function shellSort(&$arr){ if(!is_array($arr))return;$n=count($arr); for($gap=floor($n/2);$gap>0;$gap=floor($gap/=2)){ for($i=$gap;$i<$n;++$i){ for($j=$i-$gap;$j>=0&&$arr[$j+$gap]<$arr[$j];$j-=$gap){ $temp=$arr[$j]; $arr[$j]=$arr[$j+$gap]; $arr[$j+$gap]=$temp; } } } return $arr; } print_r(shellSort($arr));查找二分查找二分查找也称折半查找(Binary Search),它是一种效率较高的查找方法。但是,折半查找要求线性表必须采用顺序存储结构,而且表中元素按关键字有序排列。首先,假设表中元素是按升序排列,将表中间位置记录的关键字与查找关键字比较,如果两者相等,则查找成功;否则利用中间位置记录将表分成前、后两个子表,如果中间位置记录的关键字大于查找关键字,则进一步查找前一子表,否则进一步查找后一子表。重复以上过程,直到找到满足条件的记录,使查找成功,或直到子表不存在为止,此时查找不成功。/** * 二分查找(Binary Search)算法,也叫折半查找算法。二分查找的思想非常简单,有点类似分治的思想。 * 二分查找针对的是一个有序的数据集合,每次都通过跟区间的中间元素对比, * 将待查找的区间缩小为之前的一半,直到找到要查找的元素,或者区间被缩小为 0。 * * 循环写法 * @param array $array 待查找的数组 * @param int $findVal 要查找的值 * @return int 返回找到的数组键 */ function binarySearch($array, $findVal) { // 非数组或者数组为空,直接返回-1 if (!is_array($array) || empty($array)) { return -1; } // 查找区间,起点和终点 $start = 0; $end = count($array) - 1; while ($start <= $end) { // 以中间点作为参照点比较,取整数 $middle = intval(($start + $end) / 2); if ($array[$middle] > $findVal) { // 查找数比参照点小,则要查找的数在左半边 // 因为 $middle 已经比较过了,这里需要减1 $end = $middle - 1; } elseif ($array[$middle] < $findVal) { // 查找数比参照点大,则要查找的数在右半边 // 因为 $middle 已经比较过了,这里需要加1 $start = $middle + 1; } else { // 查找数与参照点相等,则找到返回 return $middle; } } // 未找到,返回-1 return -1; } // 调用 $array = [10,12,16,19,20,34,56,78,84,95,100]; echo binarySearch($array, 84); /** * 递归写法 * @param array $array 待查找的数组 * @param int $findVal 要查找的值 * @param int $start 查找区间,起点 * @param int $end 查找区间,终点 * @return int 返回找到的数组键 */ function binSearch($array, $findVal, $start, $end) { // 以中间点作为参照点比较,取整数 $middle = intval(($start + $end) / 2); if ($start > $end) { return -1; } if ($findVal > $array[$middle]) { // 查找数比参照点大,则要查找的数在右半边 return binSearch($array, $findVal, $middle + 1, $end); } elseif ($findVal < $array[$middle]) { // 查找数比参照点小,则要查找的数在左半边 return binSearch($array, $findVal, $start, $middle - 1); } else { return $middle; } } // 调用 $arr = [10,12,16,19,20,34,56,78,84,95,100]; var_dump(binSearch($arr, 95, 0, count($arr)-1));