搜索到
786
篇与
的结果
-
 安装虚拟机VMware Workstation17Pro 下载https://www.vmware.com/cn/products/workstation-pro/workstation-pro-evaluation.html激活密钥VMware Workstation 17 Pro 激活密钥JU090-6039P-08409-8J0QH-2YR7F4A4RR-813DK-M81A9-4U35H-06KNDNZ4RR-FTK5H-H81C1-Q30QH-1V2LA4Y09U-AJK97-089Z0-A3054-83KLA4C21U-2KK9Q-M8130-4V2QH-CF810MC60H-DWHD5-H80U9-6V85M-8280DZA30U-DXF84-4850Q-UMMXZ-W6K8FAC590-2XW97-48EFZ-TZPQE-MYHEAYF39K-DLFE5-H856Z-6NWZE-XQ2XDAC15R-FNZ16-H8DWQ-WFPNV-M28E2CZ1J8-A0D82-489LZ-ZMZQT-P3KX6YA11K-6YE8H-H89ZZ-EXM59-Y6AR0
安装虚拟机VMware Workstation17Pro 下载https://www.vmware.com/cn/products/workstation-pro/workstation-pro-evaluation.html激活密钥VMware Workstation 17 Pro 激活密钥JU090-6039P-08409-8J0QH-2YR7F4A4RR-813DK-M81A9-4U35H-06KNDNZ4RR-FTK5H-H81C1-Q30QH-1V2LA4Y09U-AJK97-089Z0-A3054-83KLA4C21U-2KK9Q-M8130-4V2QH-CF810MC60H-DWHD5-H80U9-6V85M-8280DZA30U-DXF84-4850Q-UMMXZ-W6K8FAC590-2XW97-48EFZ-TZPQE-MYHEAYF39K-DLFE5-H856Z-6NWZE-XQ2XDAC15R-FNZ16-H8DWQ-WFPNV-M28E2CZ1J8-A0D82-489LZ-ZMZQT-P3KX6YA11K-6YE8H-H89ZZ-EXM59-Y6AR0 -
win下docker安装和使用 安装下载安装包:https://docs.docker.com/desktop/install/windows-install/下载 Linux 内核更新包适用于 x64 计算机的 WSL2 Linux 内核更新包解决docker下载镜像速度慢问题阿里云镜像加速器:https://阿里ID.mirror.aliyuncs.com复制上面镜像加速地址,在Docker Desktop设置如下{ "builder": { "gc": { "defaultKeepStorage": "20GB", "enabled": true } }, "experimental": true, "features": { "buildkit": true }, "registry-mirrors": [ "https://阿里ID.mirror.aliyuncs.com" ] }experimental默认为false,这里改成true后才能保存,然后再改回来使用命令行输入docker run hello-world
-
-
漫谈oop与pop 在我们的编程生涯中,不得不面对两种编程思想oop与pop。啥是oop?面向对象程序设计(Object Oriented Programming) 作为一种新方法,其本质是以建立模型体现出来的抽象思维过程和面向对象的方法。模型是用来反映现实世界中事物特征的。任何一个模型都不可能反映客观事物的一切具体特征,只能对事物特征和变化规律的一种抽象,且在它所涉及的范围内更普遍、更集中、更深刻地描述客体的特征。通过建立模型而达到的抽象是人们对客体认识的深化。啥是pop?“面向过程”(Procedure Oriented) 是一种以过程为中心的编程思想。这些都是以什么正在发生为主要目标进行编程,不同于面向对象的是谁在受影响。与面向对象明显的不同就是封装、继承、类。简写为POP。两者区别1、 面向过程 是 以过程为中心 的编程思想, 着重于做什么 ; 面向对象 是 以事物为中心 的编程思想, 着重于谁来做 。2、 面向过程适合小项目,它的执行效率高 ,毕竟是从上到下,有前后顺序依次执行,过程相对来说简单干脆, 不过程序拓展性不好,维护成本较高(通过缓存、静态化可以解决面向过程编程的执行效率问题) ; 面向对象适合中大型项目, 它的执行过程可谓曲折,总是爱 new个对象再去实现 ,即便如此,它的 继承,封装,多态 的特性,使得 程序易拓展易维护 。经典例子之把大象装进冰箱比如,以“ 把大象装进冰箱 ”举例。面向过程实现面向过程实现有 三个步骤 :1、打开冰箱门2、把大象装进去3、关上冰箱门这就是典型的分析出问题所需的步骤,然后用函数将这些步骤一步一步的实现,使用的时候在一个一个的依次调用就可以了。可以看出, 面向过程编程关注的主体是过程、步骤。面向对象实现面向对象实现也是 三个步骤 :1、先找出对象,大象对象和冰箱对象2、分析对象的功能大象对象:大象走进冰箱冰箱对象:冰箱门打开和关闭3、使用大象和冰箱对象的功能,冰箱执行冰箱开门功能,然后大象执行大象走进冰箱功能,最后冰箱执行关闭冰箱功能。可以看出, 面向对象编程关注的主体是事物、对象。 另外,在面向对象的编程中, 万物皆可对象 。 面向对象的 方法主要是把事物给对象化 ,包括其属性和行为。面向对象编程 更贴近实际生活 的思想。总体来说 面向对象的底层还是面向过程 ,面向过程 抽象成类,然后封装,方便使用 就是面向对象,这也就解释了,为什么上面 面向对象与面向过程的实现 有这么多 相似之处,殊途同归。
-
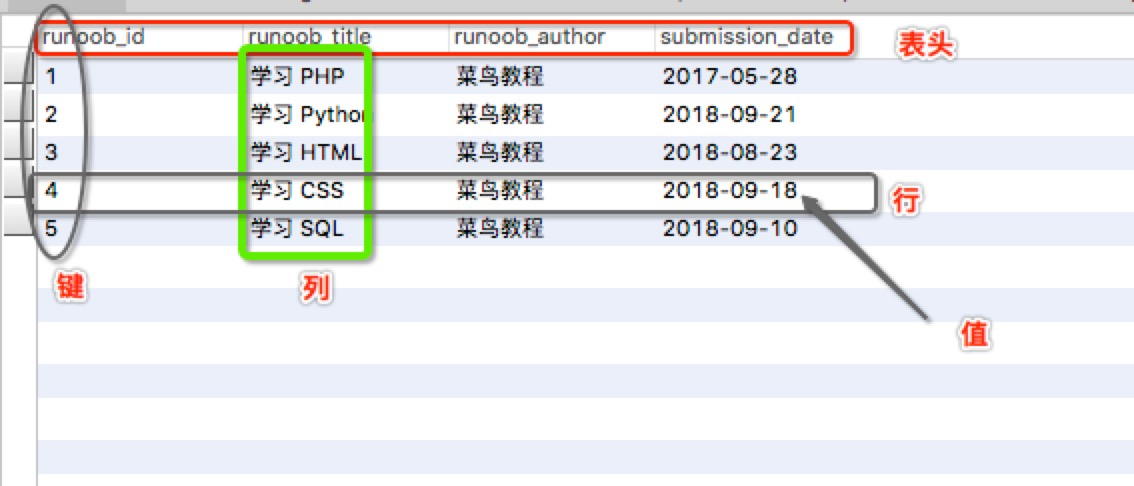
MySQL入门到工匠 入门简介什么是数据库?数据库(Database)是 按照数据结构来组织、存储和管理数据的仓库 。每个数据库都有一个或多个不同的 API 用于创建,访问,管理,搜索和复制所保存的数据 。我们也 可以将数据存储在文件中,但是在文件中读写数据速度相对较慢 。所以,现在我们 使用关系型数据库管理系统(RDBMS)来存储和管理大数据量 。所谓的关系型数据库,是建立在 关系模型 基础上的数据库,借助于 集合代数等数学概念和方法 来处理数据库中的数据。RDBMS 即关系数据库管理系统(Relational Database Management System)的特点:1.数据以表格的形式出现2.每行为各种记录名称3.每列为记录名称所对应的数据域4.许多的行和列组成一张表单5.若干的表单组成database术语RDBMS 术语在我们开始学习MySQL 数据库前,让我们先了解下RDBMS的一些术语:1.数据库: 数据库是一些关联表的集合。2.数据表: 表是数据的矩阵。在一个数据库中的表看起来像一个简单的电子表格。3.列: 一列(数据元素) 包含了相同类型的数据, 例如邮政编码的数据。4.行: 一行(=元组,或记录)是一组相关的数据,例如一条用户订阅的数据。5.冗余: 存储两倍数据,冗余降低了性能,但提高了数据的安全性。6.主键: 主键是唯一的。一个数据表中只能包含一个主键。你可以使用主键来查询数据。7.外键: 外键用于关联两个表。8.复合键: 复合键(组合键)将多个列作为一个索引键,一般用于复合索引。9.索引: 使用索引可快速访问数据库表中的特定信息。索引是对数据库表中一列或多列的值进行排序的一种结构。类似于书籍的目录。10.参照完整性: 参照的完整性要求关系中不允许引用不存在的实体。与实体完整性是关系模型必须满足的完整性约束条件,目的是保证数据的一致性。MySQL 为 关系型数据库(Relational Database Management System) , 这种所谓的 "关系型"可以理解为"表格"的概念, 一个关系型数据库由一个或数个表格组成 , 如图所示的一个表格:表头(header): 每一列的名称;列(col): 具有相同数据类型的数据的集合;行(row): 每一行用来描述某条记录的具体信息;值(value): 行的具体信息, 每个值必须与该列的数据类型相同;键(key): 键的值在当前列中具有唯一性。特点MySQL 是一个关系型数据库管理系统,由瑞典 MySQL AB 公司开发,目前属于 Oracle 公司。MySQL 是一种关联数据库管理系统,关联数据库将数据保存在不同的表中,而不是将所有数据放在一个大仓库内,这样就增加了速度并提高了灵活性。MySQL 是开源的,所以你不需要支付额外的费用。MySQL 支持大型的数据库。可以处理拥有上千万条记录的大型数据库。MySQL 使用标准的 SQL 数据语言形式。MySQL 可以运行于多个系统上,并且支持多种语言。这些编程语言包括 C、C++、Python、Java、Perl、PHP、Eiffel、Ruby 和 Tcl 等。MySQL 对PHP有很好的支持,PHP 是目前最流行的 Web 开发语言。MySQL 支持大型数据库,支持 5000 万条记录的数据仓库,32 位系统表文件最大可支持 4GB,64 位系统支持最大的表文件为8TB。MySQL 是可以定制的,采用了 GPL 协议,你可以修改源码来开发自己的 MySQL 系统。三范式第一范式:属性不可分割。第二范式:每个数据表必须拥有主键,并且唯一标识整个数据表。第三范式:消除数据冗余,信息只在一个数据表存储,不能存储在多张数据表。然后通过外键进行关联。8.0 新特性1. 默认字符集由latin1变为utf8mb4在8.0版本之前,默认字符集为latin1,utf8指向的是utf8mb3,8.0版本默认字符集为utf8mb4,utf8默认指向的也是utf8mb4 。注:在Percona Server 8.0.15版本上测试,utf8仍然指向的是utf8mb3,与官方文档有出入。Warning | 3719 | 'utf8' is currently an alias for the character set UTF8MB3, but will be an alias for UTF8MB4 in a future release. Please consider using UTF8MB4 in order to be unambiguous. |2. MyISAM系统表全部换成InnoDB表系统表全部换成 事务型的innodb表 ,默认的MySQL实例将不包含任何MyISAM表,除非手动创建MyISAM表。//MySQL 5.7 mysql> select distinct(ENGINE) from information_schema.tables; +--------------------+ | ENGINE | +--------------------+ | MEMORY | | InnoDB | | MyISAM | | CSV | | PERFORMANCE_SCHEMA | | NULL | +--------------------+ 6 rows in set (0.00 sec) //MySQL 8.0 mysql> select distinct(ENGINE) from information_schema.tables; +--------------------+ | ENGINE | +--------------------+ | NULL | | InnoDB | | CSV | | PERFORMANCE_SCHEMA | +--------------------+ 4 rows in set (0.00 sec)3. 自增变量持久化在8.0之前的版本,自增主键AUTO_INCREMENT的值如果大于max(primary key)+1,在MySQL重启后,会重置AUTO_INCREMENT=max(primary key)+1,这种现象在某些情况下会导致业务主键冲突或者其他难以发现的问题 。自增主键重启重置的问题很早就被发现(https://bugs.mysql.com/bug.php?id=199),一直到8.0才被解决,8.0版本将会对AUTO_INCREMENT值进行持久化,MySQL重启后,该值将不会改变。4. DDL原子化InnoDB表的 DDL支持事务完整性,要么成功要么回滚 ,将DDL操作 回滚日志 写入到 data dictionary 数据字典表 mysql.innodb_ddl_log 中用于回滚操作,该表是 隐藏 的表,通过 show tables 无法看到。通过 设置参数 ,可将ddl操作日志打印 输出到mysql错误日志 中。mysql> set global log_error_verbosity=3; mysql> set global innodb_print_ddl_logs=1; mysql> create table t1(c int) engine=innodb; // MySQL错误日志: 2018-06-26T11:25:25.817245+08:00 44 [Note] [MY-012473] [InnoDB] InnoDB: DDL log insert : [DDL record: DELETE SPACE, id=41, thread_id=44, space_id=6, old_file_path=./db/t1.ibd] 2018-06-26T11:25:25.817369+08:00 44 [Note] [MY-012478] [InnoDB] InnoDB: DDL log delete : by id 41 2018-06-26T11:25:25.819753+08:00 44 [Note] [MY-012477] [InnoDB] InnoDB: DDL log insert : [DDL record: REMOVE CACHE, id=42, thread_id=44, table_id=1063, new_file_path=db/t1] 2018-06-26T11:25:25.819796+08:00 44 [Note] [MY-012478] [InnoDB] InnoDB: DDL log delete : by id 42 2018-06-26T11:25:25.820556+08:00 44 [Note] [MY-012472] [InnoDB] InnoDB: DDL log insert : [DDL record: FREE, id=43, thread_id=44, space_id=6, index_id=140, page_no=4] 2018-06-26T11:25:25.820594+08:00 44 [Note] [MY-012478] [InnoDB] InnoDB: DDL log delete : by id 43 2018-06-26T11:25:25.825743+08:00 44 [Note] [MY-012485] [InnoDB] InnoDB: DDL log post ddl : begin for thread id : 44 2018-06-26T11:25:25.825784+08:00 44 [Note] [MY-012486] [InnoDB] InnoDB: DDL log post ddl : end for thread id : 44来看 另外一个例子,库里只有一个t1表,drop table t1,t2; 试图删除t1,t2两张表,在5.7中,执行报错,但是t1表被删除,在8.0中执行报错,但是t1表没有被删除 ,证明了8.0 DDL操作的原子性,要么全部成功,要么回滚。// MySQL 5.7 mysql> show tables; +---------------+ | Tables_in_db | +---------------+ | t1 | +---------------+ 1 row in set (0.00 sec) mysql> drop table t1, t2; ERROR 1051 (42S02): Unknown table 'db.t2' mysql> show tables; Empty set (0.00 sec) // MySQL 8.0 mysql> show tables; +---------------+ | Tables_in_db | +---------------+ | t1 | +---------------+ 1 row in set (0.00 sec) mysql> drop table t1, t2; ERROR 1051 (42S02): Unknown table 'db.t2' mysql> show tables; +---------------+ | Tables_in_db | +---------------+ | t1 | +---------------+ 1 row in set (0.00 sec)5. 参数修改持久化MySQL 8.0版本 支持在线修改全局参数并持久化 ,通过加上 PERSIST 关键字,可以 将修改的参数持久化到新的配置文件(mysqld-auto.cnf)中 , 重启MySQ L时,可以从该配置文件获取到最新的配置参数。例如执行:set PERSIST expire_logs_days=10 ;系统会在数据目录下生成一个包含json格式的 mysqld-auto.cnf 的文件 ,格式化后如下所示,当 my.cnf 和 mysqld-auto.cnf 同时存在时, 后者具有更高优先级 。{ "Version": 1, "mysql_server": { "expire_logs_days": { "Value": "10", "Metadata": { "Timestamp": 1529657078851627, "User": "root", "Host": "localhost" } } } }6. 新增降序索引MySQL在语法上 很早就已经支持降序索引,但实际上创建的仍然是升序索引 ,如下 MySQL 5.7 所示,c2字段降序,但是从 show create table 看c2仍然是 升序 。 8.0可以看到,c2字段降序。// MySQL 5.7 mysql> create table t1(c1 int,c2 int,index idx_c1_c2(c1,c2 desc)); Query OK, 0 rows affected (0.03 sec) mysql> show create table t1\G *************************** 1. row *************************** Table: t1 Create Table: CREATE TABLE `t1` ( `c1` int(11) DEFAULT NULL, `c2` int(11) DEFAULT NULL, KEY `idx_c1_c2` (`c1`,`c2`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 1 row in set (0.00 sec) // MySQL 8.0 mysql> create table t1(c1 int,c2 int,index idx_c1_c2(c1,c2 desc)); Query OK, 0 rows affected (0.06 sec) mysql> show create table t1\G *************************** 1. row *************************** Table: t1 Create Table: CREATE TABLE `t1` ( `c1` int(11) DEFAULT NULL, `c2` int(11) DEFAULT NULL, KEY `idx_c1_c2` (`c1`,`c2` DESC) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci ROW_FORMAT=DYNAMIC 1 row in set (0.00 sec)再来看看 降序索引在执行计划中的表现 ,在t1表插入10万条随机数据,查看 select * from t1 order by c1 , c2 desc; 的执行计划。从执行计划上可以看出,5.7的扫描数100113远远大于8.0的5行,并且使用了 filesort 。DELIMITER ;; CREATE PROCEDURE test_insert () BEGIN DECLARE i INT DEFAULT 1; WHILE i<100000 DO insert into t1 select rand()*100000, rand()*100000; SET i=i+1; END WHILE ; commit; END;; DELIMITER ; CALL test_insert(); // MySQL 5.7 mysql> explain select * from t1 order by c1 , c2 desc limit 5; +----+-------------+-------+------------+-------+---------------+-----------+---------+------+--------+----------+-----------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+-----------+---------+------+--------+----------+-----------------------------+ | 1 | SIMPLE | t1 | NULL | index | NULL | idx_c1_c2 | 10 | NULL | 100113 | 100.00 | Using index; Using filesort | +----+-------------+-------+------------+-------+---------------+-----------+---------+------+--------+----------+-----------------------------+ 1 row in set, 1 warning (0.00 sec) // MySQL 8.0 mysql> explain select * from t1 order by c1 , c2 desc limit 5; +----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-------------+ | 1 | SIMPLE | t1 | NULL | index | NULL | idx_c1_c2 | 10 | NULL | 5 | 100.00 | Using index | +----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-------------+ 1 row in set, 1 warning (0.00 sec)降序索引 只是对查询中特定的排序顺序有效,如果使用不当,反而查询效率更低 ,比如上述查询排序条件改为 order by c1 desc, c2 desc ,这种情况下, 5.7的执行计划要明显好于8.0的 ,如下:// MySQL 5.7 mysql> explain select * from t1 order by c1 desc , c2 desc limit 5; +----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-------------+ | 1 | SIMPLE | t1 | NULL | index | NULL | idx_c1_c2 | 10 | NULL | 5 | 100.00 | Using index | +----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-------------+ 1 row in set, 1 warning (0.01 sec) // MySQL 8.0 mysql> explain select * from t1 order by c1 desc , c2 desc limit 5; +----+-------------+-------+------------+-------+---------------+-----------+---------+------+--------+----------+-----------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+-----------+---------+------+--------+----------+-----------------------------+ | 1 | SIMPLE | t1 | NULL | index | NULL | idx_c1_c2 | 10 | NULL | 100429 | 100.00 | Using index; Using filesort | +----+-------------+-------+------------+-------+---------------+-----------+---------+------+--------+----------+-----------------------------+ 1 row in set, 1 warning (0.01 sec)7. group by 不再隐式排序mysql 8.0 对于group by 字段不再隐式排序,如 需要排序,必须显式加上order by 子句。// 表结构 mysql> show create table tb1\G *************************** 1. row *************************** Table: tb1 Create Table: CREATE TABLE `tb1` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(50) DEFAULT NULL, `group_own` int(11) DEFAULT '0', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=11 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci ROW_FORMAT=DYNAMIC 1 row in set (0.00 sec) // 表数据 mysql> select * from tb1; +----+------+-----------+ | id | name | group_own | +----+------+-----------+ | 1 | 1 | 0 | | 2 | 2 | 0 | | 3 | 3 | 0 | | 4 | 4 | 0 | | 5 | 5 | 5 | | 8 | 8 | 1 | | 10 | 10 | 5 | +----+------+-----------+ 7 rows in set (0.00 sec) # MySQL 5.7 mysql> select count(id), group_own from tb1 group by group_own; +-----------+-----------+ | count(id) | group_own | +-----------+-----------+ | 4 | 0 | | 1 | 1 | | 2 | 5 | +-----------+-----------+ 3 rows in set (0.00 sec) # MySQL 8.0.11 mysql> select count(id), group_own from tb1 group by group_own; +-----------+-----------+ | count(id) | group_own | +-----------+-----------+ | 4 | 0 | | 2 | 5 | | 1 | 1 | +-----------+-----------+ 3 rows in set (0.00 sec) // MySQL 8.0.11显式地加上order by进行排序 mysql> select count(id), group_own from tb1 group by group_own order by group_own; +-----------+-----------+ | count(id) | group_own | +-----------+-----------+ | 4 | 0 | | 1 | 1 | | 2 | 5 | +-----------+-----------+ 3 rows in set (0.00 sec)8. JSON特性增强MySQL 8 大幅改进了对 JSON 的支持,添加了 基于路径查询参数从 JSON 字段中抽取数据 的 JSON_EXTRACT() 函数,以及 用于将数据分别组合到 JSON 数组和对象中 的 JSON_ARRAYAGG() 和 JSON_OBJECTAGG() 聚合函数。在主从复制中,新增参数 binlog_row_value_options ,控制JSON数据的传输方式,允许对于Json类型部分修改, 在binlog中只记录修改的部分 ,减少json大数据在只有少量修改的情况下,对资源的占用。9. redo & undo 日志加密增加以下 两个参数 ,用于控制redo、undo日志的加密。innodb_undo_log_encrypt innodb_undo_log_encrypt11. innodb select for update跳过锁等待select ... for update,select ... for share(8.0新增语法) 添加 NOWAIT、SKIP LOCKED语法,跳过锁等待,或者跳过锁定。 在5.7及之前的版本,select...for update,如果获取不到锁,会一直等待,直到innodb_lock_wait_timeout超时。 在8.0版本,通过添加nowait,skip locked语法,能够立即返回。 如果查询的行已经加锁,那么nowait会立即报错返回,而skip locked也会立即返回,只是返回的结果中不包含被锁定的行。// session1: mysql> begin; mysql> select * from t1 where c1 = 2 for update; +------+-------+ | c1 | c2 | +------+-------+ | 2 | 60530 | | 2 | 24678 | +------+-------+ 2 rows in set (0.00 sec) // session2: mysql> select * from t1 where c1 = 2 for update nowait; ERROR 3572 (HY000): Statement aborted because lock(s) could not be acquired immediately and NOWAIT is set. mysql> select * from t1 where c1 = 2 for update skip locked; Empty set (0.00 sec)11. 增加SET_VAR语法在sql语法中 增加SET_VAR语法,动态调整部分参数 ,有利于 提升语句性能 。select /*+ SET_VAR(sort_buffer_size = 16M) */ id from test order id ; insert /*+ SET_VAR(foreign_key_checks=OFF) */ into test(name) values(1);12. 支持不可见索引使用 INVISIBLE 关键字 在创建表或者进行表变更中设置索引是否可见 。 索引不可见只是在查询时优化器不使用该索引 ,即使使用force index,优化器也不会使用该索引,同时优化器也不会报索引不存在的错误,因为索引仍然真实存在,在必要时,也可以快速的恢复成可见。// 创建不可见索引 create table t2(c1 int,c2 int,index idx_c1_c2(c1,c2 desc) invisible ); // 索引可见 alter table t2 alter index idx_c1_c2 visible; // 索引不可见 alter table t2 alter index idx_c1_c2 invisible;13. 支持直方图优化器会利用 column_statistics 的数据,判断字段的值的分布,得到更准确的执行计划。可以使用 ANALYZE TABLE table_name [UPDATE HISTOGRAM on col_name with N BUCKETS |DROP HISTOGRAM ON clo_name] 来 收集或者删除直方图信息 。直方图 统计了表中某些字段的数据分布情况 ,为优化选择高效的执行计划提供参考, 直方图与索引有着本质的区别,维护一个索引有代价 。每一次的insert、update、delete都会需要更新索引,会对性能有一定的影响。而 直方图一次创建永不更新,除非明确去更新它 。所以不会影响insert、update、delete的性能。// 添加/更新直方图 mysql> analyze table t1 update histogram on c1, c2 with 32 buckets; +--------+-----------+----------+-----------------------------------------------+ | Table | Op | Msg_type | Msg_text | +--------+-----------+----------+-----------------------------------------------+ | db.t1 | histogram | status | Histogram statistics created for column 'c1'. | | db.t1 | histogram | status | Histogram statistics created for column 'c2'. | +--------+-----------+----------+-----------------------------------------------+ 2 rows in set (2.57 sec) // 删除直方图 mysql> analyze table t1 drop histogram on c1, c2; +--------+-----------+----------+-----------------------------------------------+ | Table | Op | Msg_type | Msg_text | +--------+-----------+----------+-----------------------------------------------+ | db.t1 | histogram | status | Histogram statistics removed for column 'c1'. | | db.t1 | histogram | status | Histogram statistics removed for column 'c2'. | +--------+-----------+----------+-----------------------------------------------+ 2 rows in set (0.13 sec)14. 新增innodb_dedicated_server参数能够让InnoDB根据服务器上 检测到的内存大小 自动配置 innodb_buffer_pool_size,innodb_log_file_size,innodb_flush_method 三个参数。15. 日志分类更详细在错误信息中添加了 错误信息编号[MY-010311] 和 错误所属子系统[Server]// MySQL 5.7 2018-06-08T09:07:20.114585+08:00 0 [Warning] 'proxies_priv' entry '@ root@localhost' ignored in --skip-name-resolve mode. 2018-06-08T09:07:20.117848+08:00 0 [Warning] 'tables_priv' entry 'user mysql.session@localhost' ignored in --skip-name-resolve mode. 2018-06-08T09:07:20.117868+08:00 0 [Warning] 'tables_priv' entry 'sys_config mysql.sys@localhost' ignored in --skip-name-resolve mode. // MySQL 8.0 2018-06-21T17:53:13.040295+08:00 28 [Warning] [MY-010311] [Server] 'proxies_priv' entry '@ root@localhost' ignored in --skip-name-resolve mode. 2018-06-21T17:53:13.040520+08:00 28 [Warning] [MY-010330] [Server] 'tables_priv' entry 'user mysql.session@localhost' ignored in --skip-name-resolve mode. 2018-06-21T17:53:13.040542+08:00 28 [Warning] [MY-010330] [Server] 'tables_priv' entry 'sys_config mysql.sys@localhost' ignored in --skip-name-resolve mode.16. undo空间自动回收innodb_undo_log_truncate 参数在8.0.2版本 默认值由OFF变为ON,默认开启 undo日志表空间自动回收。 innodb_undo_tablespaces 参数在8.0.2版本默认为2,当一个undo表空间被回收时, 还有另外一个提供正常服务。 innodb_max_undo_log_size 参数定义了 undo表空间回收的最大值 ,当undo表空间 超过 这个值,该表空间被 标记为可回收 。17. 增加资源组MySQL 8.0新增了一个 资源组功能,用于调控线程优先级以及绑定CPU核 。MySQL用户需要有 RESOURCE_GROUP_ADMIN 权限才能创建、修改、删除资源组。在Linux环境下,MySQL进程需要有 CAP_SYS_NICE 权限才能使用资源组完整功能。[root@localhost~]# sudo setcap cap_sys_nice+ep /usr/local/mysql8.0/bin/mysqld [root@localhost~]# getcap /usr/local/mysql8.0/bin/mysqld /usr/local/mysql8.0/bin/mysqld = cap_sys_nice+ep默认提供两个资源组 ,分别是 USR_default,SYS_default创建资源组create resource group test_resouce_group type=USER vcpu=0,1 thread_priority=5;将当前线程加入资源组SET RESOURCE GROUP test_resouce_group;将某个线程加入资源组SET RESOURCE GROUP test_resouce_group FOR thread_id;查看资源组里有哪些线程select * from Performance_Schema.threads where RESOURCE_GROUP='test_resouce_group';修改资源组alter resource group test_resouce_group vcpu = 2,3 THREAD_PRIORITY = 8;删除资源组drop resource group test_resouce_group;示例// 创建资源组 mysql>create resource group test_resouce_group type=USER vcpu=0,1 thread_priority=5; Query OK, 0 rows affected (0.03 sec) mysql> select * from RESOURCE_GROUPS; +---------------------+---------------------+------------------------+----------+-----------------+ | RESOURCE_GROUP_NAME | RESOURCE_GROUP_TYPE | RESOURCE_GROUP_ENABLED | VCPU_IDS | THREAD_PRIORITY | +---------------------+---------------------+------------------------+----------+-----------------+ | USR_default | USER | 1 | 0-3 | 0 | | SYS_default | SYSTEM | 1 | 0-3 | 0 | | test_resouce_group | USER | 1 | 0-1 | 5 | +---------------------+---------------------+------------------------+----------+-----------------+ 3 rows in set (0.00 sec) // 把线程id为60的线程加入到资源组test_resouce_group中,线程id可通过Performance_Schema.threads获取 mysql> SET RESOURCE GROUP test_resouce_group FOR 60; Query OK, 0 rows affected (0.00 sec) // 资源组里有线程时,删除资源组报错 mysql> drop resource group test_resouce_group; ERROR 3656 (HY000): Resource group test_resouce_group is busy. // 修改资源组 mysql> alter resource group test_resouce_group vcpu = 2,3 THREAD_PRIORITY = 8; Query OK, 0 rows affected (0.10 sec) mysql> select * from RESOURCE_GROUPS; +---------------------+---------------------+------------------------+----------+-----------------+ | RESOURCE_GROUP_NAME | RESOURCE_GROUP_TYPE | RESOURCE_GROUP_ENABLED | VCPU_IDS | THREAD_PRIORITY | +---------------------+---------------------+------------------------+----------+-----------------+ | USR_default | USER | 1 | 0-3 | 0 | | SYS_default | SYSTEM | 1 | 0-3 | 0 | | test_resouce_group | USER | 1 | 2-3 | 8 | +---------------------+---------------------+------------------------+----------+-----------------+ 3 rows in set (0.00 sec) // 把资源组里的线程移出到默认资源组USR_default mysql> SET RESOURCE GROUP USR_default FOR 60; Query OK, 0 rows affected (0.00 sec) // 删除资源组 mysql> drop resource group test_resouce_group; Query OK, 0 rows affected (0.04 sec)18. 增加角色管理角色可以认为 是一些权限的集合,为用户赋予统一的角色,权限的修改直接通过角色来进行,无需为每个用户单独授权。// 创建角色 mysql> create role role_test; Query OK, 0 rows affected (0.03 sec) // 给角色授予权限 mysql> grant select on db.* to 'role_test'; Query OK, 0 rows affected (0.10 sec) // 创建用户 mysql> create user 'read_user'@'%' identified by '123456'; Query OK, 0 rows affected (0.09 sec) // 给用户赋予角色 mysql> grant 'role_test' to 'read_user'@'%'; Query OK, 0 rows affected (0.02 sec) // 给角色role_test增加insert权限 mysql> grant insert on db.* to 'role_test'; Query OK, 0 rows affected (0.08 sec) // 给角色role_test删除insert权限 mysql> revoke insert on db.* from 'role_test'; Query OK, 0 rows affected (0.10 sec) // 查看默认角色信息 mysql> select * from mysql.default_roles; +------+-----------+-------------------+-------------------+ | HOST | USER | DEFAULT_ROLE_HOST | DEFAULT_ROLE_USER | +------+-----------+-------------------+-------------------+ | % | read_user | % | role_test | +------+-----------+-------------------+-------------------+ 1 row in set (0.00 sec) // 查看角色与用户关系 mysql> select * from mysql.role_edges; +-----------+-----------+---------+-----------+-------------------+ | FROM_HOST | FROM_USER | TO_HOST | TO_USER | WITH_ADMIN_OPTION | +-----------+-----------+---------+-----------+-------------------+ | % | role_test | % | read_user | N | +-----------+-----------+---------+-----------+-------------------+ 1 row in set (0.00 sec) // 删除角色 mysql> drop role role_test; Query OK, 0 rows affected (0.06 sec)数据类型介绍MySQL 支持所有标准SQL数值数据类型 。这些类型包括 严格数值数据类型(INTEGER、SMALLINT、DECIMAL和NUMERIC),以及近似数值数据类型(FLOAT、REAL和DOUBLE PRECISION) 。数值数据类型关键字INT是INTEGER的同义词,关键字DEC是DECIMAL的同义词。BIT数据类型保存位字段值,并且支持MyISAM、MEMORY、InnoDB和BDB表。作为SQL标准的扩展,MySQL也支持整数类型TINYINT、MEDIUMINT和BIGINT。下面的表显示了需要的每个整数类型的存储和范围。类型 大小 范围(有符号) 范围(无符号) 用途TINYINT 1 字节 (-128,127) (0,255) 小整数值SMALLINT 2 字节 (-32 768,32 767) (0,65 535) 大整数值MEDIUMINT 3 字节 (-8 388 608,8 388 607) (0,16 777 215) 大整数值INT或INTEGER 4 字节 (-2 147 483 648,2 147 483 647) (0,4 294 967 295) 大整数值BIGINT 8 字节 (-9,223,372,036,854,775,808,9 223 372 036 854 775 807) (0,18 446 744 073 709 551 615) 极大整数值FLOAT 4 字节 (-3.402 823 466 E+38,-1.175 494 351 E-38),0,(1.175 494 351 E-38,3.402 823 466 351 E+38) 0,(1.175 494 351 E-38,3.402 823 466 E+38) 单精度 浮点数值DOUBLE 8 字节 (-1.797 693 134 862 315 7 E+308,-2.225 073 858 507 201 4 E-308),0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) 0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) 双精度 浮点数值DECIMAL 对DECIMAL(M,D) ,如果M>D,为M+2否则为D+2 依赖于M和D的值 依赖于M和D的值 小数值日期和时间类型表示时间值的日期和时间类型为 DATETIME、DATE、TIMESTAMP、TIME和YEAR。 每个时间类型有一个有效值范围和一个"零"值,当指定不合法的MySQL不能表示的值时使用"零"值。TIMESTAMP类型有专有的自动更新特性,将在后面描述。| 类型 | 大小(字节) 范围 格式 用途DATE 3 1000-01-01/9999-12-31 YYYY-MM-DDTIME 3 '-838:59:59'/'838:59:59' HH:MM:SSYEAR 1 1901/2155 YYYYDATETIME 8 1000-01-01 00:00:00/9999-12-31 23:59:59 YYYY-MM-DD HH:MM:SSTIMESTAMP 41970-01-01 00:00:00/2038结束时间是第2147483647秒,北京时间2038-1-19 11:14:07,格林尼治时间 2038年1月19日 凌晨 03:14:07| YYYYMMDD HHMMSS | 混合日期和时间值,时间戳 |字符串类型字符串类型指 CHAR、VARCHAR、BINARY、VARBINARY、BLOB、TEXT、ENUM和SET 。该节描述了这些类型 如何工作以及如何在查询中使用这些类型 。类型 大小 用途CHAR 0-255字节 定长字符串VARCHAR 0-65535 字节 变长字符串TINYBLOB 0-255字节 不超过 255 个字符的二进制字符串TINYTEXT 0-255字节 短文本字符串BLOB 0-65 535字节 二进制形式的长文本数据TEXT 0-65 535字节 长文本数据MEDIUMBLOB 0-16 777 215字节 二进制形式的中等长度文本数据MEDIUMTEXT 0-16 777 215字节 中等长度文本数据LONGBLOB 0-4 294 967 295字节 二进制形式的极大文本数据LONGTEXT 0-4 294 967 295字节 极大文本数据CHAR 和 VARCHAR 类型类似,但它们保存和检索的方式不同。它们的最大长度和是否尾部空格被保留等方面也不同。在存储或检索过程中不进行大小写转换。BINARY 和 VARBINARY 类似于 CHAR 和 VARCHAR,不同的是它们包含二进制字符串而不要非二进制字符串。也就是说,它们包含字节字符串而不是字符字符串。这说明它们没有字符集,并且排序和比较基于列值字节的数值值。BLOB 是一个二进制大对象,可以容纳可变数量的数据。有 4 种 BLOB 类型:TINYBLOB、BLOB、MEDIUMBLOB 和 LONGBLOB。它们区别在于可容纳存储范围不同。数据类型详解在Mysql中常用数据类型一共有 四种字符串数据类型、日期/时间数据类型、数值数据类型以及二进制数据类型 。约束条件在开始正式讲解数据类型之前,我们需要先了解下如何给字段添加一些基本的约束条件。Mysql可以 给字段添加的常用约束条件有:unsigned,zerofill,not null,default,primary key,auto_increment,unique key,foreign key 。unsigned:无符号类型,加上此约束值无法取负数,只能作用于数值类型数据列。zerofill:当数据显示长度不够时在数据前面补0至指定长度,字段会自动添加unsigned约束。not null:这个很好理解,给字段添加非空约束。default:如果插入数据没有指定值,则使用默认值。primary key:给字段添加主键约束,一个表只能有一个主键,但是可以和其他字段形成组合主键,一般与auto_increment约束一并使用。auto_increment:只能作用于数值类型,字段可以自动递增,默认从1开始。一般和primary key配合使用。unique key:设置唯一约束,则字段的值不能出现重复数据,null除外。foreign key:外键约束,保证数据完整性和唯一性,以及多表联表操作。四种数据类型字符串数据类型:主要包括下列几种数据类型:char,varchar,tinytext,mediumtext,text,longtext,enum,set。日期/时间数据类型:主要包含下列几种数据类型:date,time,datetime,timestamp,year。数值数据类型:主要包含下列几种数据类型:tinyint,smallint,mediumint,int,bigint,float,double,decimal。二进制数据类型:主要包含下列几种数据类型:tityblob,blob,mediumblob,longblob。字符串类型char数据类型定义: 可以定义一个 固定长度的字符串 ,长度范围在 1-255 个字符之间,长度必须在表创建时指定,否则 会默认定义为char(1),在存储时字符串如果未达到指定的长度则会填充空格到指定长度。 使用途径: 当我们需要涉及一些 长度固定的数据列 时可以使用char数据类型,比如 手机号使用char(11),身份证号使用char(18),用户性别使用char(3)。varchar数据类型定义: 可以定义一个 可变长度的字符串 ,理论情况下可 存储最多255个字节的数据。但是如果创建时指定varchar(x),则只能存储不超过x个字符的数据 。对比char类型区别: 实际上我们 更经常使用的还是varchar数据类型 ,因为char类型不管存储数据的长度多少,都会占用定义的字节数,但是varchar只会占用实际字符串长度+1个字节。 但是char查询效率相比于varchar会更高 ,所以存储固定长度时我们可以优先选择char数据类型。 使用途径: 一般 长度不固定的数据列 就可以使用varchar类型,比如 姓名,一般中文名字2到5字,所以我们定义为varchar(15)。tinytext数据类型定义: tinytext也属于 变长字符串 ,最多可 存储不超过255字节的变长文本 。缺点: tinyint数据类型 定义时不允许设置默认值,在检索也不存在大小写转换,而且效率低于char以及varchar 。所以一般情况下比较少使用该数据类型。mediumtext数据类型定义: mediumtext也属于 变长字符串 ,最多可 存储不超过16k字节的变长文本 。缺点: mediumtext和tinytext同属于 text 系列数据类型,所以缺点都是一致的。使用途径: mediumtext一般 用于varchar存储范围不符合时用来存储长文本 操作,一般情况下使用mediumtext存储长文本就可以满足操作。text数据类型定义: text也属于 变长字符串 ,最多可 存储不超过64k字节的变长文本 。缺点: text也属于text系列数据类型,所以缺点和上述都是一致的。使用途径: text一般 用于mediumtext存储范围不符合时用来存储长文本 操作,一般用户 文章存储 。longtext数据类型定义: longtext也属于变长字符串,最多可存储不超过4G字节的变长文本。缺点: longtext也属于text系列数据类型,所以缺点和上述都是一致的。使用途径: longtext最长长度 可存储不超过4G的纯文本 ,但是一般情况下几乎不需要使用这种数据类型。enum数据类型定义: ENUM是一个 字符串对象,可以通过ENUM限制字段的取值范围。 如果插入数据时字段的取值并非可选值之一,则会空串或者NULL代替用户想要插入的值。 enum集合的长度最多不超过64K。 缺点: 不建议在数据库使用ENUM限制取值范围,因为坑其实挺多的,比如ENUM通过角标取值,但是角标从1开始,因为0留给空串了,再或者在ENUM中0和"0"是不一样的,如果将0当做角标去操作由于ENUM角标从1开始会报错,如果使用"0"去操作,最后插入的是空串,因为角标0是预留给空串的。所以说在数据库层次 不建议使用ENUM限制字段取值范围 。使用途径: 比如 用户性别 我们在建表时可以 使用ENUM限制取值范围只能为男或女 。set数据类型定义: 数据列定义为set则 可以存储集合 ,set集合最多 不超过64k的长度 。set与enum的区别: enum定义数据列的取值范围,但是 插入值永远只能有一个值 。但是set可以设置数据列的取值范围,但是 插入值时可以插入多个值 。 使用途径: 如果我们需要保存集合数据的时候可以将字段设置为set集合然后设置一个取值范围, 然后插入时在取值范围内取多个值形成集合进行插入 。。日期/时间数据类型Mysql有多种可以用来存储时间或日期的数据类型,比如我们 可以使用date存储日期,可以使用year存储年份,可以使用time存储时间。可以使用datetime或者timestamp来存储日期和时间的组合 ,接下来我们来看下这几个日期/时间数据类型。date数据类型定义: 用来存储 日期 ,存储 范围为'1000-01-01'到'9999-12-31' 。使用途径: 可用于存储年月日的数据列,比如存储用户出生日期我们就可以使用date数据类型来进行存储。year数据类型定义: 这个很简单,就是保存一个 年份值 。使用途径: 比如我们需要 记录图书出版年份 ,则可以使用year数据类型。datetime数据类型定义: 可以使用datetime来保存 时间与日期组合 格式,存储范围为1970-01-01 00:00:00 到 9999-12-31 23:59:59。一般有两种保存方式yyyy-mm-dd HH:MM:SS或者yyyymmddHHMMSS。使用途径: 这个很常用,比如订单下单时间或订单付款时间。timestamp数据类型定义: timestamp实际上功能 和datetime差不多,但是范围更小, timestamp存储范围为1000-01-01 00:00:00 到 2038-01-19 11:14:07。使用途径: 这个很常用,比如订单下单时间或订单付款时间。数值数据类型刚才其实提到了数值数据类型有很多种,不同类型有不同的存储范围,同样所需的存储空间也是不一样的,数值类型都可以都是有符号,即可设置正负值。tinyint数据类型定义: 存储整型数据, 大小为1字节 ,如果保存有符号值则取值范围为 -128到127,如果保存无符号值大小为取值范围为0到255。smallint数据类型定义: 存储整型数据, 大小为2字节 ,如果保存有符号值则取值范围为 -32768到32767,如果保存无符号值大小为取值范围为0到65535。mediumint数据类型定义: 存储整型数据, 大小为3字节 ,如果保存 有符号 值则取值范围为 -8388608到8388607,如果保存 无符号 值大小为取值范围为 0到16777215 。int数据类型定义: 存储整型数据, 大小为4字节 ,如果保存 有符号 值则取值范围为 -2147683648到2147683647 ,如果保存 无符号 值大小为取值范围为 0到4294967295 。bigint数据类型定义: 存储整型数据, 大小为8字节 ,如果保存 有符号 值则取值范围为 -263到263-1 ,如果保存 无符号 值大小为取值范围为 0到2^64-1 。float数据类型定义: 存储 浮点数据,大小为4字节 ,浮点型不能设置 unsigned ,取值范围为 -1.175494351e - 38到1.175494351e - 38 。double数据类型定义: 存储 浮点数据,大小为8字节 ,浮点型不能设置 unsigned , 精度 相比float会更 高 ,取值范围为 -2.2250738585072014e-308到2.2250738585072014e-308 。decimal数据类型定义: 常用于存储 精确的小数,可以设置存储的字节数和保留的小数位数 。存储的 字节数最大为65,默认为10,小数位数最大为30,默认为0 。使用途径: 经常可以 使用decimal保存金额或者积分值 ,因为金额一般保存都是固定小数位。二进制数据类型定义: 二进制数据类型 可存储任何数据,既可存储文本数据,也可存储图像或者多媒体等数据。 二进制数据类型其实相对其他数据类型 比较少用 ,因为文件现在一般都是 上传oss进行cdn加速 ,一共有 四种数据类型:tinyblob,blob,mediumblob,longblob ,这几个数据类型的区别在于存储范围。tinyblob:存储长度最大为255字节。blob:存储长度最大为64k。mediumblob:存储长度最大为16M。longblob:存储长度最大为4G。缺点:存储文件过大会影响数据库的性能。常用函数一、数字函数ABS(x) 返回x的绝对值BIN(x) 返回x的二进制(OCT返回八进制,HEX返回十六进制) CEILING(x) 返回大于x的最小整数值 EXP(x) 返回值e(自然对数的底)的x次方 FLOOR(x) 返回小于x的最大整数值 GREATEST(x1,x2,...,xn)返回集合中最大的值 LEAST(x1,x2,...,xn) 返回集合中最小的值 LN(x) 返回x的自然对数 LOG(x,y)返回x的以y为底的对数 MOD(x,y) 返回x/y的模(余数) PI()返回pi的值(圆周率) RAND()返回0到1内的随机值,可以通过提供一个参数(种子)使RAND()随机数生成器生成一个指定的值。 ROUND(x,y)返回参数x的四舍五入的有y位小数的值 SIGN(x) 返回代表数字x的符号的值 SQRT(x) 返回一个数的平方根 TRUNCATE(x,y) 返回数字x截短为y位小数的结果二、聚合函数(常用于GROUP BY从句的SELECT查询中)select sum(anyun_level) from anyun_tbl;AVG(col)返回指定列的平均值COUNT(col)返回指定列中非NULL值的个数MIN(col)返回指定列的最小值MAX(col)返回指定列的最大值SUM(col)返回指定列的所有值之和GROUP\_CONCAT(col) 返回由属于一组的列值连接组合而成的结果三、字符串函数ASCII(char)返回字符的ASCII码值BIT\_LENGTH(str)返回字符串的比特长度CONCAT(s1,s2...,sn)将s1,s2...,sn连接成字符串CONCAT\_WS(sep,s1,s2...,sn)将s1,s2...,sn连接成字符串,并用sep字符间隔INSERT(str,x,y,instr) 将字符串str从第x位置开始,y个字符长的子串替换为字符串instr,返回结果FIND\_IN\_SET(str,list)分析逗号分隔的list列表,如果发现str,返回str在list中的位置LCASE(str)或LOWER(str) 返回将字符串str中所有字符改变为小写后的结果LEFT(str,x)返回字符串str中最左边的x个字符LENGTH(s)返回字符串str中的字符数LTRIM(str) 从字符串str中切掉开头的空格POSITION(substr,str) 返回子串substr在字符串str中第一次出现的位置QUOTE(str) 用反斜杠转义str中的单引号**REPEAT(str,srchstr,rplcstr)返回字符串str重复x次的结果REVERSE(str) 返回颠倒字符串str的结果RIGHT(str,x) 返回字符串str中最右边的x个字符 RTRIM(str) 返回字符串str尾部的空格STRCMP(s1,s2)比较字符串s1和s2TRIM(str)去除字符串首部和尾部的所有空格UCASE(str)或UPPER(str) 返回将字符串str中所有字符转变为大写后的结果四、日期和时间函数CURDATE()或CURRENT\_DATE() 返回当前的日期 CURTIME()或CURRENT\_TIME() 返回当前的时间 DATE\_ADD(date,INTERVAL int keyword)返回日期date加上间隔时间int的结果(int必须按照关键字进行格式化),如:SELECTDATE\_ADD(CURRENT\_DATE,INTERVAL 6 MONTH); DATE\_FORMAT(date,fmt) 依照指定的fmt格式格式化日期date值 DATE\_SUB(date,INTERVAL int keyword)返回日期date加上间隔时间int的结果(int必须按照关键字进行格式化),如:SELECTDATE\_SUB(CURRENT\_DATE,INTERVAL 6 MONTH); DAYOFWEEK(date) 返回date所代表的一星期中的第几天(1~7) DAYOFMONTH(date) 返回date是一个月的第几天(1~31) DAYOFYEAR(date) 返回date是一年的第几天(1~366) DAYNAME(date) 返回date的星期名,如:SELECT DAYNAME(CURRENT\_DATE); FROM\_UNIXTIME(ts,fmt) 根据指定的fmt格式,格式化UNIX时间戳ts HOUR(time) 返回time的小时值(0~23) MINUTE(time) 返回time的分钟值(0~59) MONTH(date) 返回date的月份值(1~12) MONTHNAME(date) 返回date的月份名,如:SELECT MONTHNAME(CURRENT\_DATE); NOW() 返回当前的日期和时间 QUARTER(date) 返回date在一年中的季度(1~4),如SELECT QUARTER(CURRENT\_DATE); WEEK(date) 返回日期date为一年中第几周(0~53) YEAR(date) 返回日期date的年份(1000~9999)一些示例:获取当前系统时间 :SELECT FROM\_UNIXTIME(UNIX\_TIMESTAMP()); SELECT EXTRACT(YEAR\_MONTH FROM CURRENT\_DATE); SELECT EXTRACT(DAY\_SECOND FROM CURRENT\_DATE); SELECT EXTRACT(HOUR\_MINUTE FROM CURRENT\_DATE); 返回两个日期值之间的差值(月数) :SELECT PERIOD\_DIFF(200302,199802); 在Mysql中计算年龄 : SELECT DATE\_FORMAT(FROM\_DAYS(TO\_DAYS(NOW())-TO\_DAYS(birthday)),'%Y')+0 AS age FROM employee;这样,如果Brithday是未来的年月日的话,计算结果为0。下面的SQL语句计算员工的绝对年龄,即当Birthday是未来的日期时,将得到负值。SELECT DATE\_FORMAT(NOW(), '%Y') - DATE\_FORMAT(birthday, '%Y') -(DATE\_FORMAT(NOW(), '00-%m-%d') <DATE\_FORMAT(birthday, '00-%m-%d')) AS age from employee 五、加密函数AES\_ENCRYPT(str,key) 返回用密钥key对字符串str利用高级加密标准算法加密后的结果,调用AES\_ENCRYPT的结果是一个二进制字符串,以BLOB类型存储 AES\_DECRYPT(str,key) 返回用密钥key对字符串str利用高级加密标准算法解密后的结果 DECODE(str,key) 使用key作为密钥解密加密字符串str ENCRYPT(str,salt) 使用UNIXcrypt()函数,用关键词salt(一个可以惟一确定口令的字符串,就像钥匙一样)加密字符串str ENCODE(str,key) 使用key作为密钥加密字符串str,调用ENCODE()的结果是一个二进制字符串,它以BLOB类型存储 MD5() 计算字符串str的MD5校验和 PASSWORD(str) 返回字符串str的加密版本,这个加密过程是不可逆转的,和UNIX密码加密过程使用不同的算法。 SHA() 计算字符串str的安全散列算法(SHA)校验和示例:SELECT ENCRYPT('root','salt'); SELECT ENCODE('xufeng','key'); SELECT DECODE(ENCODE('xufeng','key'),'key');#加解密放在一起 SELECT AES\_ENCRYPT('root','key'); SELECT AES\_DECRYPT(AES\_ENCRYPT('root','key'),'key'); SELECT MD5('123456'); SELECT SHA('123456');六、控制流函数MySQL 有4个函数是用来进行条件操作的 ,这些函数可以实现SQL的 条件逻辑 ,允许开发者将一些应用程序业务逻辑转换到数据库后台。 MySQL控制流函数:CASE WHEN[test1] THEN [result1]...ELSE [default] END如果testN是真,则返回resultN,否则返回defaultCASE [test] WHEN[val1] THEN [result]...ELSE [default]END 如果test和valN相等,则返回resultN,否则返回defaultIF(test,t,f) 如果test是真,返回t;否则返回fIFNULL(arg1,arg2) 如果arg1不是空,返回arg1,否则返回arg2NULLIF(arg1,arg2) 如果arg1=arg2返回NULL;否则返回arg1IFNULL()这些函数的第一个是 IFNULL() ,它有两个参数,并且 对第一个参数进行判断。如果第一个参数不是NULL,函数就会向调用者返回第一个参数;如果是NULL,将返回第二个参数 。如:SELECT IFNULL(1,2), IFNULL(NULL,10),IFNULL(4*NULL,'false');NULLIF()NULLIF()函数将会 检验提供的两个参数是否相等,如果相等,则返回NULL,如果不相等,就返回第一个参数。如:SELECT NULLIF(1,1),NULLIF('A','B'),NULLIF(2+3,4+1);IF()和许多脚本语言提供的IF()函数一样,MySQL的IF()函数也可以建立一个简单的条件测试,这个函数 有三个参数,第一个是要被判断的表达式,如果表达式为真,IF()将会返回第二个参数,如果为假,IF()将会返回第三个参数。如:SELECTIF(1100,'true','false');CASEIF()函数在 只有两种可能结果时才适合使用 。然而,在现实世界中,我们可能发现在条件测试中会 需要多个分支 。在这种情况下,MySQL提供了 CASE函数 ,它和PHP及Perl语言的 switch-case条件 例程一样。CASE函数的格式有些复杂,通常如下所示:CASE [expression to be evaluated] WHEN [val 1] THEN [result 1] WHEN [val 2] THEN [result 2] WHEN [val 3] THEN [result 3] ...... WHEN [val n] THEN [result n] ELSE [default result] END这里, 第一个参数是要被判断的值或表达式,接下来的是一系列的WHEN-THEN块,每一块的第一个参数指定要比较的值,如果为真,就返回结果。 所有的WHEN-THEN块将以ELSE块结束,当END结束了所有外部的CASE块时,如果前面的每一个块都不匹配就会返回ELSE块指定的默认结果。如果没有指定ELSE块,而且所有的WHEN-THEN比较都不是真,MySQL将会返回NULL。CASE函数 还有另外一种句法 ,有时使用起来非常方便,如下:CASE WHEN \[conditional test 1\] THEN \[result 1\] WHEN \[conditional test 2\] THEN \[result 2\] ELSE \[default result\] END 这种条件下,返回的结果取决于相应的条件测试是否为真。 示例:mysql>SELECT CASE 'green' WHEN 'red' THEN 'stop' WHEN 'green' THEN 'go' END; SELECT CASE 9 WHEN 1 THEN 'a' WHEN 2 THEN 'b' ELSE 'N/A' END; SELECT CASE WHEN (2+2)=4 THEN 'OK' WHEN(2+2)<>4 THEN 'not OK' END ASSTATUS; SELECT Name,IF((IsActive = 1),'已激活','未激活') AS RESULT FROMUserLoginInfo; SELECT fname,lname,(math+sci+lit) AS total, CASE WHEN (math+sci+lit) < 50 THEN 'D' WHEN (math+sci+lit) BETWEEN 50 AND 150 THEN 'C' WHEN (math+sci+lit) BETWEEN 151 AND 250 THEN 'B' ELSE 'A' END AS grade FROM marks; SELECT IF(ENCRYPT('sue','ts')=upass,'allow','deny') AS LoginResultFROM users WHERE uname = 'sue';#一个登陆验证 七、格式化函数DATE\_FORMAT(date,fmt) 依照字符串fmt格式化日期date值 FORMAT(x,y) 把x格式化为以逗号隔开的数字序列,y是结果的小数位数 INET\_ATON(ip) 返回IP地址的数字表示 INET\_NTOA(num) 返回数字所代表的IP地址 TIME\_FORMAT(time,fmt) 依照字符串fmt格式化时间time值其中最简单的是 FORMAT() 函数,它可以 把大的数值格式化为以逗号间隔 的易读的序列。 示例:SELECT FORMAT(34234.34323432,3); SELECT DATE\_FORMAT(NOW(),'%W,%D %M %Y %r'); SELECT DATE\_FORMAT(NOW(),'%Y-%m-%d'); SELECT DATE\_FORMAT(19990330,'%Y-%m-%d'); SELECT DATE\_FORMAT(NOW(),'%h:%i %p'); SELECT INET\_ATON('10.122.89.47'); SELECT INET\_NTOA(175790383); 八、类型转化函数为了进行数据类型转化,MySQL提供了 CAST() 函数,它可以 把一个值转化为指定的数据类型。 类型有:BINARY,CHAR,DATE,TIME,DATETIME,SIGNED,UNSIGNED示例:SELECT CAST(NOW() AS SIGNED INTEGER),CURDATE()+0; SELECT 'f'=BINARY 'F','f'=CAST('F' AS BINARY);九、系统信息函数DATABASE() 返回当前数据库名 BENCHMARK(count,expr) 将表达式expr重复运行count次 CONNECTION\_ID() 返回当前客户的连接ID FOUND\_ROWS() 返回最后一个SELECT查询进行检索的总行数 USER()或SYSTEM\_USER() 返回当前登陆用户名 VERSION() 返回MySQL服务器的版本示例:SELECT DATABASE(),VERSION(),USER(); SELECTBENCHMARK(9999999,LOG(RAND()\*PI()));#该例中,MySQL计算LOG(RAND()\*PI())表达式9999999次。参考 https://www.runoob.com/mysql/mysql-functions.html命令速查SQL速查表 SQL 语句对大小写不敏感SELECTSELECT * FROM 表名称 --查询所有 SELECT 列名称 FROM 表名称 --查询指定列DISTINCTSELECT DISTINCT 列名称 FROM 表名称 --将指定列的值去重WHERESELECT 列名称 FROM 表名称 WHERE 列 运算符 值运算符 描述= 等于<>, != 不等于< 小于<= 小于等于大于= 大于等于BETWEEN AND 在某个范围内LIKE 模糊AND & ORSELECT 列名称 FROM 表名称 WHERE 列 运算符 值 AND 列 运算符 值 SELECT 列名称 FROM 表名称 WHERE 列 运算符 值 OR 列 运算符 值ORDER BYSELECT * FROM 表名称 ORDER BY 列名称 ASC --升序(默认) SELECT * FROM 表名称 ORDER BY 列名称 DESC --降序INSERT INTOINSERT INTO 表名称 VALUES (值1, 值2,....) INSERT INTO table_name (列1, 列2,...) VALUES (值1, 值2,....)UPDATEUPDATE 表名称 SET 列名称 = 新值 WHERE 列名称 = 某值DELETEDELETE FROM 表名称 WHERE 列名称 = 值LIMIT & OFFSETSELECT * FROM 表名称 LIMIT offset,rows --查询从offset开始共rows行 SELECT * FROM 表名称 LIMIT rows OFFSET offset --查询从offset开始共rows行MyISAM与InnoDB区别什么是MyISAM?MyISAM是 MySQL关系数据库管理系统的默认储存引擎(5.5之前) 。这种MySQL表存储结构从旧的ISAM代码扩展 出许多有用的功能。在新版本的MySQL中, InnoDB引擎由于其对事务,参照完整性,以及更高的并发性等优点开始广泛的取代MyISAM 。 每一个MyISAM表 都对应于硬盘上的 三个文件 。这三个文件有一样的文件名,但是有不同的扩展名以指示其类型用途: .frm文件保存表的定义,但是这个文件并不是MyISAM引擎的一部分,而是服务器的一部分;.MYD保存表的数据;.MYI是表的索引文件 。什么是InnoDB?InnoDB是MySQL的另一个存储引擎,目前MySQL AB所发行新版的标准,被包含在所有二进制安装包里, 5.5之后作为默认的存储引擎。 较之于其它的存储引擎它的优点是它 支持兼容ACID的事务(类似于PostgreSQL),以及参数 完整性(即对外键的支持) 。Oracle公司与2005年10月收购了Innobase。Innobase采用双认证授权。它使用GNU发行,也允许其它想将InnoDB结合到商业软件的团体获得授权。目前 比较普及的存储引擎是MyISAM和InnoDB 。MyISAM与InnoDB的主要的 不同点在于性能和事务控制上。 MyISAM是 早期ISAM(Indexed Sequential Access Method,MySQL5.0之后已经不支持ISAM了)的扩展实现, ISAM被设计为适合处理读频率远大于写频率这样的情况,因此ISAM以及后来的MyISAM都没有考虑对事物的支持,排除了TPM,不需要事务记录, ISAM的查询效率相当可观,而且内存占用很少。 MyISAM 在继承了这类优点的同时,与时俱进地提供了大量实用的新特性和相关工具。例如考虑到并发控制,提供了 表级锁 ,虽然MyISAM本身不支持容错,但可以通过 myisamchk进行故障恢复。而且由于MyISAM是每张表使用各自独立的存储文件(MYD数据文件和MYI索引文件),使得备份及恢复十分方便(拷贝覆盖即可),而且还支持在线恢复。与其他存储引擎比较,MyISAM具有检查和修复表格的大多数工具. MyISAM表格可以被压缩,而且它们支持全文(fulltext)搜索。它们不是事务安全的,而且也不支持外键所以如果你的应用是不需要事务,处理的只是基本的CRUD操作,那么MyISAM是不二选择。InnoDB 被设计成 适用于高并发读写 的情况,使用 MVCC(Multi-Version Concurrency Control)以及行级锁来提供遵从ACID的事务支持 。InnoDB支持外键参照完整性,具备故障恢复能力。另外 InnoDB的性能其实还是不错的,特别是在处理大数据量的情况下,用官方的话说就是: InnoDB的CPU效率是其他基于磁盘的关系数据库存储引擎所不能比的。不过InnoDB的备份恢复要麻烦一点,除非你使用了4.1以后版本提供的 Mulit-tablespace支持,因为InnoDB和MyISAM不同,他的数据文件并不是独立对应于每张表的。而是使用的共享表空间,简单的拷贝覆盖方法对他不适用,必须在停掉MYSQL后对进行数据恢复。使用Per-Table Tablespacesd,使其每张表对应一个独立的表空间文件,则情况要简单很多。它与BDB类型具有相同的特性,它们还支持外键。InnoDB表格速度很快,具有比BDB还丰富的特性,因此如果需要一个事务安全的存储引擎,建议使用它。一般来说,如果需要事务支持,并且有较高的并发读写频率,InnoDB是不错的选择。要是并发读写频率不高的话,其实可以考虑BDB,但由于在 MySQL5.1及其以后版本中,将不再提供BDB支持 。这个选项也就没有了InnoDB默认情况下的事务是打开的(set autocommit = 0)就是说每插入一条记录时候,InnoDB类型的表都会把它当作一个单独的事务来处理.所以如果我们插入了10000条记录,而且没有将事务关闭,那么 InnoDB类型的表会把它当作10000个事务来处理,此时插入的总时间是很多的,这个时候一定要首先把事务关掉再插入,这样的速度就很快了 至于Heap和BDB(Berkeley DB),相对来说,普及率不如前两种,但在有些情况下,还是挺适用的Heap存储引擎就是将数据存储在内存中,由于没有磁盘I/O的等待,速度极快。但由于是内存存储引擎,所做的任何修改在服务器重启后都将消失。Heap挺适合做测试的时候使用BDB是MySQL第一款事务安全的存储引擎。在Berkeley DB database library的基础上建立,同样是事务安全的,但BDB的普及率显然不及InnoDB,因为大多数在MySQL中寻找支持事务的存储引擎的同时也在找支 持MVCC或是行级锁定存储引擎,而BDB只支持Page-level Lock。InnoDB引擎InnoDB是一个 事务型的存储引擎,支持回滚,设计目标是处理大数量数据时提供高性能的服务,它在运行时会在内存中建立缓冲池,用于缓冲数据和索引 。InnoDB引擎优点1.支持事务处理、ACID事务特性;2.实现了SQL标准的四种隔离级别;3.支持行级锁和外键约束;4.可以利用事务日志进行数据恢复。5.锁级别为行锁,行锁优点是适用于高并发的频繁表修改,高并发是性能优于 MyISAM。缺点是系统消耗较大。6.索引不仅缓存自身,也缓存数据,相比 MyISAM 需要更大的内存。InnoDB引擎缺点因为它没有保存表的行数,当使用COUNT统计时会扫描全表。MyISAM引擎MyISAM 是 MySQL 5.5.5 之前的默认引擎,它的设计目标是快速读取。MyISAM引擎优点1.高性能读取;2.因为它保存了表的行数,当使用COUNT统计时不会扫描全表;MyISAM引擎缺点1.锁级别为表锁,表锁优点是开销小,加锁快;缺点是锁粒度大,发生锁冲动概率较高,容纳并发能力低,这个引擎适合查询为主的业务。2.此引擎不支持事务,也不支持外键。3.INSERT和UPDATE操作需要锁定整个表;4.它存储表的行数,于是SELECT COUNT(*) FROM TABLE时只需要直接读取已经保存好的值而不需要进行全表扫描。适用场景MyISAM适合:(1)做很多count 的计算;(2)插入不频繁,查询非常频繁;(3)没有事务。InnoDB适合:(1)可靠性要求比较高,或者要求事务;(2)表更新和查询都相当的频繁,并且表锁定的机会比较大的情况。表格对比属性 MyISAM Heap BDB InnoDB事务 不支持 不支持 支持 支持锁粒度 表锁 表锁 页锁(page, 8KB) 行锁存储 拆分文件 内存中 每个表一个文件 表空间隔离等级 无 无 读已提交 所有可移植格式 是 N/A 否 是引用完整性 否 否 否 是数据主键 否 否 是 是MySQL缓存数据记录 无 有 有 有可用性 全版本 全版本 MySQL-Max 全版本一些细节上的差别InnoDB不支持 FULLTEXT 类型的索引, MySQL5.6 之后已经支持(实验性)。InnoDB中不保存表的 具体行数 ,也就是说,执行 select count() from table 时,InnoDB要扫描一遍整个表来计算有多少行,但是 MyISAM只要简单的读出保存好的行数 即可。注意的是,当count()语句包含 where条件时,两种表的操作是一样的。对于 AUTO_INCREMENT 类型的字段,InnoDB中必须包含只有该字段的索引,但是在MyISAM表中,可以和其他字段一起建立联合索引。DELETE FROM table 时,InnoDB不会重新建立表,而是一行一行的删除。LOAD TABLE FROM MASTER 操作对InnoDB是不起作用的,解决方法是首先把InnoDB表改成MyISAM表,导入数据后再改成InnoDB表,但是对于使用的额外的InnoDB特性(例如外键)的表不适用。另外,InnoDB表的行锁也不是绝对的,如果在执行一个SQL语句时MySQL 不能确定要扫描的范围,InnoDB表同样会锁全表 。服务器构成(一)、MySQL服务器构成1.1 客户端与服务器端模型MySQL是一个 典型的C/S模式,单进程多线程的服务结构。 MySQL自带的 客户端程序在/usr/local/mysql/bin下 ,如:mysql、 mysqladmin、mysqldump等; 服务端程序是mysqld(即守护进程,二进制的程序)1.2 应用程序连接MySQL的方式1.2.1 TCP/IP方式通过网络连接串:[root@db02 ~]# mysql -uroot -p12345678 -h 127.0.0.11.2.2 Socket方式通过套接字文件:[root@db02 ~]# mysql -uroot -p12345678 -S /usr/local/mysql/tmp/mysql.sock提示:服务器默认使用Socket方式连接数据库。1.3 实例介绍1.3.1 什么是实例MySQL 在启动过程中会启动后台守护进程,并生成工作线程,预分配内存结构供MySQL处理数据使用,这些MySQL的后台进程+线程+预分配的内存结构就是实例。(二)、MySQL的逻辑结构2.1 mysqld服务器程序构成msyqld服务程序分为三层 ,分别为 连接层、SQL层、存储引擎层 :2.1.1 连接层所包含的服务并 不是MySQL所独有的技术 。它们都是 服务于C/S程序或者是这些程序所需要的 :连接处理,身份验证,安全性等等 :2.1.2 SQL层这是 MySQL的核心部分 ,通常叫做 SQL Layer 。在 MySQL据库系统 处理底层数据之前的所有工作都是在这一层完成的 ,包括 权限判断,sql解析,行计划优化,query cache的处理以及所有内置的函数(如日期、时间、数学运算、加密) 等等。各个 存储引擎提供的功能 都集中在这一层,如 存储过程,触发器,视图 等:SQL处理流程图: 2.1.3 存储引擎层通常叫做 StorEngine Layer ,也就是 底层数据存取操作实现部分,由多种存储引擎共同组成 。它们负责存储和获取所有存储在MySQL中的数据。 就像Linux众多的文件系统一样。每个存储引擎都有自己的优点和缺陷。服务器是通过存储引擎API来与它们交互的 。这个接口隐藏了各个存储引擎不同的地方,对于查询层尽可能的透明。这个API包含了很多底层的操作,如开始一个事务,或者取出有特定主键的行。 存储引擎不能解析SQL,互相之间也不能通信,仅仅是简单的响应服务器 的请求:(三)、2.2 SQL的整个处理过程2.2.1 Connectors指的是不同语言中与SQL的交互。2.2.2 Management Serveices & Utilities:系统管理和控制工具。2.2.3 Connection Pool: 连接池管理缓冲用户连接,线程处理等需要缓存的需求。 负责监听对 MySQL Server 的各种请求,接收连接请求,转发所有连接请求到 线程管理模块 。每一个连接上 MySQL Server 的客户端请求都会被分配(或创建)一个连接线程为其单独服务。而 连接线程 的 主要工作就是负责 MySQL Server 与客户端的通信,接受客户端的命令请求,传递 Server 端的结果信息等。 线程管理模块则 负责管理维护这些连接线程 。包括线程的创建,线程的 cache 等。2.2.4 SQL Interface: SQL接口接受用户的SQL命令,并且返回用户需要查询的结果。 比如select from就是调用SQL Interface。2.2.5 Parser: 解析器SQL命令传递到解析器的时候会被解析器验证和解析。 解析器是由Lex和YACC实现的,是一个很长的脚本。在 MySQL中我们习惯将 所有 Client 端发送给 Server 端的命令 都称为 query ,在 MySQL Server 里面,连接线程接收到客户端的一个 Query 后,会直接将该 query 传递给专门负责将各种 Query 进行分类然后转发给各个对应的处理模块。主要功能: 将SQL语句进行语义和语法的分析,分解成数据结构,然后按照不同的操作类型进行分类,然后做出针对性的转发到后续步骤,以后SQL语句的传递和处理就是基于这个结构的。如果在分解构成中遇到错误,那么就说明这个sql语句是不合理的2.2.6 Optimizer: 查询优化器SQL语句在 查询之前会使用查询优化器对查询进行优化。 就是优化客户端请求的 query(sql语句) ,根据客户端请求的 query 语句,和数据库中的一些统计信息,在一系列算法的基础上进行分析,得出一个最优的策略,告诉后面的程序如何取得这个 query 语句的结果,他使用的是“ 选取-投影-联接 ”策略进行查询,用一个例子就可以理解:select uid,name from user where gender = 1;解析方式:这个select 查询先根据where 语句进行选取,而不是先将表全部查询出来以后再进行gender过滤这个select查询先根据uid和name进行属性投影,而不是将属性全部取出以后再进行过滤将这两个查询条件联接起来生成最终查询结果2.2.7 Cache和Buffer:查询缓存他的主要功能是将客户端提交 给MySQL 的Select类 query请求的返回结果集cache到内存中,与该query的一个hash值做一个对应。 该Query 所取数据的基表发生任何数据的变化 之后,MySQL会 自动使该query的Cache失效 。在 读写比例非常高 的应用系统中,Query Cache对 性能的提高 是非常显著的。当然它对 内存的消耗 也是非常大的。如果查询缓存 有命中的查询结果 ,查询语句就可以 直接去查询缓存中取数据。 这个缓存机制是由一系列小缓存组成的:比如表缓存、记录缓存、key缓存、权限缓存等2.2.8 存储引擎接口存储引擎接口模块 可以说是 MySQL数据库中最有特色 的一点了。目前各种数据库产品中,基本上 只有MySQL可以实现其底层数据存储引擎的插件式管理 。这个模块实际上只是一个 抽象类 ,但正是因为它成功地将各种数据处理高度抽象化,才成就了今天MySQL可插拔存储引擎的特色。从图上还可以看出,MySQL区别于其他数据库的最重要的特点就是其插件式的表存储引擎。MySQL插件式的存储引擎架构提供了一系列标准的管理和服务支持,这些标准与存储引擎本身无关,可能是每个数据库系统本身都必需的,如SQL分析器和优化器等,而存储引擎是底层物理结构的实现,每个存储引擎开发者都可以按照自己的意愿来进行开发。注意:存储引擎是 基于表 的,而不是数据库。(四)、2.3 存储引擎概览存储引擎是 充当不同表类型的处理程序的服务器组件 。依赖于存储引擎的功能2.3.1 存储引擎用于存储数据检索数据通过索引查找数据2.3.2 双层处理上层包括SQL解析器和优化器下层包含一组存储引擎2.3.3 SQL层不依赖于存储引擎引擎不影响SQL处理有一些例外2.3.4 依赖于存储引擎的功能存储介质事务功能锁定备份和恢复优化特殊功能:如全文搜索、引用完整性、空间数据处理等(五)、MySQL“库”的构成3.1 数据库的逻辑结构3.1.1 库show databases use mysql3.1.2 表show tables;3.1.3 记录(行、列)select user,host,password from user; desc user3.2 数据库的物理结构对象存储中的 库相当于目录 。表分为 MyIASM和InnoDB 方式:MyIASM方式[root@db02 ~]# ll -h /usr/local/mysql/data/mysql/user* -rw-rw---- 1 mysql mysql 11K Nov 13 11:54 /usr/local/mysql/data/mysql/user.frm # 存放索引 -rw-rw---- 1 mysql mysql 488 Nov 13 12:33 /usr/local/mysql/data/mysql/user.MYD # 存放列结构 -rw-rw---- 1 mysql mysql 2.0K Nov 13 12:33 /usr/local/mysql/data/mysql/user.MYI # 存放行结构InnoDB方式共享表空间:ibdata1:ibdata2独立表空间:t1.frm t1.ibd创建一个数据库和表,查看一下独立表空间存储的不同mysql> create database leon; Query OK, 1 row affected (0.00 sec) mysql> use leon; Database changed mysql> create table t1 (id int); Query OK, 0 rows affected (0.63 sec) mysql> insert into t1 values(1); Query OK, 1 row affected (0.01 sec) mysql> select id from t1; +------+ | id | +------+ | 1 | +------+ 1 row in set (0.00 sec) mysql> desc t1; +-------+---------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+---------+------+-----+---------+-------+ | id | int(11) | YES | | NULL | | +-------+---------+------+-----+---------+-------+ 1 row in set (0.00 sec) [root@db02 leon]# ll -h t1* -rw-rw---- 1 mysql mysql 8.4K Nov 14 10:21 t1.frm # 存储表结构定义 -rw-rw---- 1 mysql mysql 96K Nov 14 10:21 t1.ibd # 存储行、列结构(六)、3.3 MySQL使用磁盘方式程序文件随数据目录一起存储在服务器安装目录下。 执行各种客户机程序、管理程序和实用程序时将创建程序 可执行文件和日志文件 。首要使用磁盘空间的是数据目录。服务器日志文件和状态文件 :包含有关服务器处理的语句的信息。 日志可用于进行故障排除、监视、复制和恢复。InnoDB 日志文件:(适用于所有数据库)驻留在数据目录级别。nnoDB 系统表空间:包含数据字典、撤消日志和缓冲区。每个数据库在数据目录下均具有单一目录(无论在数据库中创建何种类型的表)。数据库目录存储以下内容:数据文件:特定于存储引擎的数据文件。这些文件也可能包含元数据或索引信息,具体取决于所使用的存储引擎。格式文件 (.frm):包含每个表和/或视图结构的说明,位于相应的数据库目录中。触发器:某个表关联并在该表发生特定事件时激活的命名数据库对象。数据目录的位置取决于配置、操作系统、安装包和分发。典型位置是 /var/lib/mysql。MySQL在磁盘上存储系统数据库 (mysql)。mysql 包含诸如用户、特权、插件、帮助列表、事件、时区实现和存储例程之类的信息。事务本质事物的 本质 => 锁和并发的结合体优势:容易理解劣势:性能一般解读事务的一个 解读 容易理解的模型性能不好,性能好的模型都不容易理解。完整性ACID保证事务完整性 bob给smith转1000元钱,要么钱在bob这,要么在smith这,不会让其他线程看到bob和smith的钱都为0的情况。事务 - 单个事务单元每一个操作都可以认为是一个事务 ,如下:建立一个基于GMT_Modified的索引读一行记录写一行记录,同时更新这行记录的所有索引删除整张表插入,查询,更新,删除...事务 - 一组事务单元事务单元之间 需要 等待需要操作的内容解锁 之后,才能 执行 。事务 - 产生的原因事务单元之间 的 Happen-before 关系读写读读写读写写特性原子性: 事务是一个原子操作单元,其对数据的修改,要么全都执行,要么全都不执行。一致性:事务中包含的处理要满足数据库提前设置的约束,如主键约束或者NOT NULL 约束等。隔离性:事务处理过程中的中间状态对外部是不可见的。持久性:事务完成之后,它对于数据的修改是永久性的。分类一般分为 两种:隐式事务和显示事务 。在Mysql中, 事务默认是自动提交的,所以说每个DML语句实际上就是一次事务的过程。隐式事务没有开启和结束的标志,默认执行完SQL语句就自动提交 ,比如我们经常使用的 INSERT、UPDATE、DELETE 语句就属于隐式事务。显示事务需要显示的开启关闭, 然后执行 一系列 操作,最后如果 全部操作都成功执行 ,则 提交事务释放连接 ,如果操作 有异常,则回滚事务 中的所有操作。隔离级别级别InnoDB 引擎支持的 4种事务隔离级别 分别是: 读未提交、读已提交、可重复读、串行读。读未提交: 允许脏读,可以读取其他session中未提交的脏数据。读已提交: 不可读取其他session尚未提交的数据,只有其他session数据已提交才能读取到,为不重复读。可重复读: 该级别下可重复读,InnoDB引擎默认采用可重复读,不允许读取还未提交的脏数据,但是可能存在InnoDB独有的幻读。串行读: 该级别下隔离程度最高,事务只能一个接着一个串行执行,无法并发执行。每次串行读都需要获得表级共享锁,读写操作都会阻塞。设置可以在 my.ini 文件中 [mysqld] 下配置 transaction-isolation 属性, 隔离性的四个值为:READ-UNCOMMITTED、READ-COMMITIED、REPEATABLE-READ、SERIALIZABLE ,分别对应读未提交、读已提交、可重复读、串行读四种隔离级别。PHP中使用事务实例<?php $dbhost = 'localhost:3306'; // mysql服务器主机地址 $dbuser = 'root'; // mysql用户名 $dbpass = '123456'; // mysql用户名密码 $conn = mysqli\_connect($dbhost, $dbuser, $dbpass); if(! $conn ) { die('连接失败: ' . mysqli\_error($conn)); } // 设置编码,防止中文乱码 mysqli\_query($conn, "set names utf8"); mysqli\_select\_db( $conn, 'RUNOOB' ); mysqli\_query($conn, "SET AUTOCOMMIT=0"); // 设置为不自动提交,因为MYSQL默认立即执行 mysqli\_begin\_transaction($conn); // 开始事务定义 if(!mysqli\_query($conn, "insert into runoob\_transaction\_test (id) values(8)")) { mysqli\_query($conn, "ROLLBACK"); // 判断当执行失败时回滚 } if(!mysqli\_query($conn, "insert into runoob\_transaction\_test (id) values(9)")) { mysqli\_query($conn, "ROLLBACK"); // 判断执行失败时回滚 } mysqli\_commit($conn); //执行事务 mysqli\_close($conn); ?>MVCC隔离级别的特性先重申下 隔离级别的特性隔离级别 脏读可能性 不可重复可能性 幻读可能性 加锁读READ UNCOMMITTED Yes Yes Yes NoREAD COMMITTED No Yes Yes NoREPEATABLE READ No No Yes NoSERIALIZABLE No No No YesMVCC机制InnoDB的 一致性的非锁定读 就是通过 在MVCC实现 的,Mysql的大多数事务型存储引擎实现的都不是简单的行级锁。基于提升并发性能的考虑,它们一般都同时实现了多版本并发控制(MVCC)。MVCC的实现,是通过保存数据在某一个时间点的快照来实现的。因此每一个事务无论执行多长时间看到的数据,都是一样的。所以MVCC实现 可重复读 。快照读: select语句默认,不加锁,MVCC实现可重复读,使用的是MVCC机制读取undo中的已经提交的数据。所以它的读取是非阻塞的 当前读: select语句加S锁或X锁;所有的修改操作加X锁,在select for update 的时候,才是当地前读。RR隔离级别下的快照读,不是以begin开始的时间点作为snapshot建立时间点,而是以第一条select语句的时间点作为snapshot建立的时间点。什么是MVCC?英文全称为 Multi-Version Concurrency Control ,翻译为中文即 多版本并发控制 。在小编看来,他无非就是 乐观锁的一种实现方式 。在Java编程中,如果把乐观锁看成一个接口, MVCC便是这个接口的一个实现类 而已。Mysql中MVCC的使用及原理详解特点1.MVCC其实广泛应用于数据库技术,像Oracle,PostgreSQL等也引入了该技术,即适用范围广2.MVCC并没有简单的使用数据库的 行锁 ,而是使用了 行级锁 , row_level_lock ,而非InnoDB中的 innodb_row_lock .基本原理MVCC的实现,通过保存数据在 某个时间点的快照 来实现的。这意味着一个事务无论运行多长时间,在 同一个事务里能够看到数据一致 的视图。根据事务开始的时间不同,同时也意味着在 同一个时刻不同事务看到的相同表里的数据可能是不同的 。基本特征每行数据都存在一个版本,每次数据更新时都更新该版本。修改时Copy出当前版本随意修改,各个事务之间无干扰。保存时比较版本号,如果成功(commit),则覆盖原记录;失败则放弃copy(rollback)InnoDB存储引擎MVCC的实现策略在每一行数据中额外保存两个隐藏的列:当前行创建时的版本号和删除时的版本号(可能为空,其实还有一列称为回滚指针,用于事务回滚,不在本文范畴)。这里的版本号并不是实际的时间值,而是系统版本号。每开始新的事务,系统版本号都会自动递增。事务开始时刻的系统版本号会作为事务的版本号,用来和查询每行记录的版本号进行比较。每个事务又有自己的版本号 ,这样事务内执行CRUD操作时,就 通过版本号的比较来达到数据版本控制的目的。MVCC下InnoDB的增删查改是怎么work的1.插入数据(insert) :记录的版本号即当前事务的版本号执行一条数据语句:insert into testmvcc values(1,"test");假设事务id为1,那么插入后的数据行如下:2、在更新操作的时候 ,采用的是先标记旧的那行记录为已删除,并且删除版本号是事务版本号,然后插入一行新的记录的方式。比如,针对上面那行记录,事务Id为2 要把name字段更新update table set name= 'new_value' where id=1;3、删除操作 的时候,就把事务版本号作为删除版本号。比如delete from table where id=1;4、查询操作: 从上面的描述可以看到,在查询时要符合以下 两个条件的记录才能被事务查询出来 :删除版本号未指定或者大于当前事务版本号,即查询事务开启后确保读取的行未被删除。(即上述事务id为2的事务查询时,依然能读取到事务id为3所删除的数据行)创建版本号 小于或者等于 当前事务版本号 ,就是说记录创建是在当前事务中(等于的情况)或者在当前事务启动之前的其他事物进行的insert。(即事务id为2的事务只能读取到create version<=2的已提交的事务的数据集)补充:1.MVCC手段只适用于Msyql隔离级别中的读已提交(Read committed)和可重复读(Repeatable Read).2.Read uncimmitted由于存在脏读,即能读到未提交事务的数据行,所以不适用MVCC.原因是MVCC的创建版本和删除版本只要在事务提交后才会产生。3.串行化由于是会对所涉及到的表加锁,并非行锁,自然也就不存在行的版本控制问题。4.通过以上总结,可知,MVCC主要作用于事务性的,有行锁控制的数据库模型。关于Mysql中MVCC的总结客观上,我们认为他就是乐观锁的一整实现方式,就是每行都有版本号,保存时根据版本号决定是否成功。但由于Mysql的写操作会加排他锁(前文有讲),如果锁定了还算不算是MVCC? 了解 乐观锁 的小伙伴们,都知道其 主要依靠版本控制,即消除锁定 ,二者相互矛盾,so从某种意义上来说,Mysql的MVCC并非真正的MVCC,他只是 借用MVCC的名号实现了读的非阻塞而已。问题和解决数据库 事务并发带来的问题 四大问题:更新丢失、脏读、不可重复读、幻象读假设张三办了一张招商银行卡,余额100元,分别说明上述情况。1、更新丢失一个事务的更新覆盖了另一个事务的更新。 事务A:向银行卡存钱100元。事务B:向银行卡存钱200元。A和B同时读到银行卡的余额,分别更新余额,后提交的事务B覆盖了事务A的更新。更新丢失 本质上是写操作的冲突,解决办法是一个一个地写 。2、脏读一个事务读取了另一个事务未提交的数据。 事务A:张三妻子给张三转账100元。事务B:张三查询余额。事务A转账后(还未提交),事务B查询多了100元。事务A由于某种问题,比如超时,进行回滚。事务B查询到的数据是假数据。脏读 本质上是读写操作的冲突,解决办法是写完之后再读。3、不可重复读一个事务两次读取同一个数据,两次读取的数据不一致。 事务A:张三妻子给张三转账100元。事务B:张三两次查询余额。事务B第一次查询余额,事务A还没有转账,第二次查询余额,事务A已经转账了,导致一个事务中,两次读取同一个数据,读取的数据不一致。不可重复读 本质上是读写操作的冲突,解决办法是读完再写。4、幻象读一个事务两次读取一个范围的记录,两次读取的记录数不一致。 事务A:张三妻子两次查询张三有几张银行卡。事务B:张三新办一张银行卡。事务A第一次查询银行卡数的时候,张三还没有新办银行卡,第二次查询银行卡数的时候,张三已经新办了一张银行卡,导致两次读取的银行卡数不一样。幻象读 本质上是读写操作的冲突,解决办法是读完再写。解决办法(1)一组事务单元执行加锁(悲观锁)开启两个十五单元之前认为冲突很严重,先把锁加上。 两个事务单元串行。(2)乐观锁并发方案让版本低的并发更新回滚 (事务1比事务2先来,则事务1的版本更低,事务2版本更高)优点:并发低时性能好缺点:并发高时失败率高,需要不断重试可以完成并发方案。最后结果事务2完成事务1在Bob给Smith加100元的更新环节,检测到事务1的这一环节的版本号 低于 事务2锁定smith账户数据的版本号,从而事务回滚。调优原则1.结合业务场景,使用低级别事务隔离2.避免行锁升级表锁在InnoDB中,行锁是通过索引实现的,如果不通过索引条件检索数据,行锁将会升级到表锁。表锁是会严重影响到整张表的操作性能的,所以应该避免它。3.控制事务的大小,减少锁定的资源量和锁定时间长度分布式事务何谓分布式事务分布式事务是 指事务的参与者、支持事务的服务器、资源服务器以及事务管理器 分别 位于不同的分布式系统的不同节点 之上。分布式事务设计 保证不同数据库的数据一致性 。目标像传统单机事务一样的操作方式,即 ACID 可按需无限扩展现状容易理解 ---> 性能不好性能好的 ---> 不容易理解应用面和能力上,分布式事务明显优于是单机事务,但它是有代价的,目前不能实现和单机事务一样的体验。不是数据库只能与单机数据库并存,不能取代。分布式事物的常识和问题什么是事务无论怎么伪装,我们在操作的仍然是个图灵机基于锁的事务实现中的问题从2PL到2PC分布式事务异常处理分布式日志记录分布式事务延迟变大问题结合MVCC的事务实现中遇到的问题分布式顺序问题共享数据两个线程共同去更改一条共享数据 ,需要让很多步操作顺序发生多进程/线程看上去就像是一步操作这就是 事务 。网络(去中心化)带来的 -理论无限的扩展能力-理论无限的数据安全性-理论无线的服务可用性失去的 -共享数据变得困难-更多的延迟-确定性丧失索引简介什么是索引?一个索引是 存储的表中一个特定列的值数据结构(最常见的是B-Tree) 。索引是在表的列上创建。所以,要记住的关键点是索引包含一个表中列的值,并且这些值存储在一个数据结构中。请记住记住这一点: 索引是一种数据结构 。MySQL索引的建立对于MySQL的高效运行是很重要的,索引可以大大 提高MySQL的检索速度 。打个比方如果合理的设计且使用索引的MySQL是一辆兰博基尼的话,那么没有设计和使用索引的MySQL就是一个人力三轮车。拿汉语字典的目录页(索引)打比方,我们可以按拼音、笔画、偏旁部首等排序的目录(索引)快速查找到需要的字。索引分单列索引和组合索引。 单列索引,即 一个索引只包含单个列 ,一个表可以有多个单列索引,但这不是组合索引。组合索引,即 一个索引包含多个列。 创建索引时 ,你需要 确保 该索引是 应用在 SQL 查询语句的条件(一般作为 WHERE 子句的条件)。 实际上,索引 也是一张表 ,该表 保存了主键与索引字段,并指向实体表的记录。代价上面都在说使用索引的好处,但 过多的使用索引将会造成滥用 。因此索引也会有它的缺点:虽然索引大大 提高了查询速度 ,同时却 会降低更新表的速度 ,如对表进行 INSERT、UPDATE和DELETE 。因为更新表时, MySQL不仅要保存数据,还要保存一下索引文件。 建立索引会占用磁盘空间的索引文件。索引的分类从数据结构角度1、B+树索引(O(log(n)))关于B+树索引,可以参考 MySQL索引背后的数据结构及算法原理2、hash索引a 仅仅能满足"=","IN"和"<=>"查询,不能使用范围查询b 其检索效率非常高,索引的检索可以一次定位,不像B-Tree 索引需要从根节点到枝节点,最后才能访问到页节点这样多次的IO访问,所以 Hash 索引的查询效率要远高于 B-Tree 索引c 只有Memory存储引擎显示支持hash索引3、FULLTEXT索引现在MyISAM和InnoDB引擎都支持了4、R-Tree索引用于对GIS数据类型创建SPATIAL索引从物理存储角度1、聚集索引(clustered index)2、非聚集索引(non-clustered index)从逻辑角度1、主键索引主键索引是一种特殊的唯一索引,不允许有空值2、普通索引(单列索引)当存在多个单列索引可以用时,mysql会根据查询优化策略选择其中一个单列索引,并不是每个单列索引都生效。当同时存在单列索引和联合索引,mysql会根据查询优化策略选择其中一个索引。如果where中的关系是or,索引不生效。3、多列索引(复合索引)复合索引指多个字段上创建的索引,只有在查 询条件中使用了创建索引时的第一个字段 ,索引才会被使用。使用复合索引时遵循 最左前缀集合4、唯一索引或者非唯一索引唯一索引 是这样一种索引,它通过 确保表中没有两个数据行具有完全相同的键值 来帮助维护 数据完整性 。为包含数据的现有表创建唯一索引时,会检查组成索引键的列或表达式中的值是否唯一。如果该表包含具有重复键值的行,那么索引创建过程会失败。为表定义了唯一索引之后,每当在该索引内添加或更改键时就会强制执行唯一性。此强制执行包括插入、更新、装入、导入和设置完整性以命名一些键。除了强制数据值的唯一性以外,唯一索引 还可用来提高查询处理期间检索数据的性能。 非唯一索引 不用于对与它们关联的表强制执行约束。相反,非唯一索引通过维护频繁使用的数据值的排序顺序, 仅仅用于提高查询性能 。5、空间索引空间索引是 对空间数据类型的字段 建立的索引,MYSQL中的 空间数据类型有4种,分别是GEOMETRY、POINT、LINESTRING、POLYGON 。MYSQL使用SPATIAL关键字进行扩展,使得能够用于创建正规索引类型的语法创建空间索引。创建空间索引的列,必须将其声明为 NOT NULL ,空间索引 只能在存储引擎为MYISAM的表 中创建创建索引创建索引CREATE TABLE 表名( 字段名 数据类型 [完整性约束条件], ……, [UNIQUE | FULLTEXT | SPATIAL] INDEX | KEY [索引名](字段名1 [(长度)] [ASC | DESC]) [USING 索引方法] );说明:UNIQUE:可选。表示索引为唯一性索引。FULLTEXT:可选。表示索引为全文索引。SPATIAL:可选。表示索引为空间索引。INDEX和KEY:用于指定字段为索引,两者选择其中之一就可以了,作用是 一样的。索引名:可选。给创建的索引取一个新名称。字段名1:指定索引对应的字段的名称,该字段必须是前面定义好的字段。长度:可选。指索引的长度,必须是字符串类型才可以使用。ASC:可选。表示升序排列。DESC:可选。表示降序排列。注:索引方法默认使用BTREE。单列索引(示例)CREATE TABLE projectfile ( id INT AUTO_INCREMENT COMMENT '附件id', fileuploadercode VARCHAR(128) COMMENT '附件上传者code', projectid INT COMMENT '项目id;此列受project表中的id列约束', filename VARCHAR (512) COMMENT '附件名', fileurl VARCHAR (512) COMMENT '附件下载地址', filesize BIGINT COMMENT '附件大小,单位Byte', -- 主键本身也是一种索引(注:也可以在上面的创建字段时使该字段主键自增) PRIMARY KEY (id), -- 主外键约束(注:project表中的id字段约束了此表中的projectid字段) FOREIGN KEY (projectid) REFERENCES project (id), -- 给projectid字段创建了唯一索引(注:也可以在上面的创建字段时使用unique来创建唯一索引) UNIQUE INDEX (projectid), -- 给fileuploadercode字段创建普通索引 INDEX (fileuploadercode) -- 指定使用INNODB存储引擎(该引擎支持事务)、utf8字符编码 ) ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT '项目附件表';注:这里只为示例如何创建索引,其他的合理性之类的先放一边。组合索引(示例)CREATE TABLE projectfile ( id INT AUTO_INCREMENT COMMENT '附件id', fileuploadercode VARCHAR(128) COMMENT '附件上传者code', projectid INT COMMENT '项目id;此列受project表中的id列约束', filename VARCHAR (512) COMMENT '附件名', fileurl VARCHAR (512) COMMENT '附件下载地址', filesize BIGINT COMMENT '附件大小,单位Byte', -- 主键本身也是一种索引(注:也可以在上面的创建字段时使该字段主键自增) PRIMARY KEY (id), -- 创建组合索引 INDEX (fileuploadercode,projectid) -- 指定使用INNODB存储引擎(该引擎支持事务)、utf8字符编码 ) ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT '项目附件表';建表后创建ALTER TABLE 表名 ADD [UNIQUE | FULLTEXT | SPATIAL] INDEX | KEY [索引名] (字段名1 [(长度)] [ASC | DESC]) [USING 索引方法];或CREATE [UNIQUE | FULLTEXT | SPATIAL] INDEX 索引名 ON 表名(字段名) [USING 索引方法];示例一:-- 假设建表时fileuploadercode字段没创建索引(注:同一个字段可以创建多个索引,但一般情况下意义不大)-- 给projectfile表中的fileuploadercode创建索引ALTER TABLE projectfile ADD UNIQUE INDEX (fileuploadercode);示例二:ALTER TABLE projectfile ADD INDEX (fileuploadercode, projectid);示例三:-- 将id列设置为主键ALTER TABLE index_demo ADD PRIMARY KEY(id) ;-- 将id列设置为自增ALTER TABLE index_demo MODIFY id INT auto_increment; 删除索引DROP INDEX 索引名 ON 表名或ALTER TABLE 表名 DROP INDEX 索引名示例一:drop index fileuploadercode1 on projectfile;示例二:alter table projectfile drop index s2123;哈希索引哈希表索引是怎么工作的?哈希表 是另外一种你可能看到用作索引的数据结构-这些索引通常被称为 哈希索引 。 使用哈希索引的原因是,在寻找值时哈希表效率极高 。所以,如果使用哈希索引,对于比较字符串是否相等的查询能够极快的检索出的值。例如之前我们讨论过的这个查询(SELECT * FROM Employee WHERE Employee_Name = ‘Jesus’) 就可以受益于创建在Employee_Name 列上的哈希索引。哈系索引的工作方式是将列的值作为索引的键值(key),和键值相对应实际的值(value)是指向该表中相应行的指针。 因为哈希表基本上可以看作是关联数组,一个典型的数据项就像“Jesus => 0x28939″,而0x28939是对内存中表中包含Jesus这一行的引用。 在哈系索引的中查询一个像“Jesus”这样的值,并得到对应行的在内存中的引用, 明显要比扫描全表获得值为“Jesus”的行的方式快很多。哈希索引的缺点哈希表是 无顺的数据结构 ,对于 很多类型 的查询语句哈希索引都无能为力。举例来说,假如你想要 找出所有小于40岁的员工 。你怎么使用使用哈希索引进行查询?这不可行, 因为哈希表只适合查询键值对-也就是说查询相等的查询(例:like “WHERE name = ‘Jesus’) 。哈希表的键值映射也暗示其键的存储是无序的。 这就是为什么哈希索引通常不是数据库索引的默认数据结构 -因为在作为索引的数据结构时,其 不像B-Tree那么灵活btree索引和hash索引的区别hash 索引结构的特殊性,其检索效率非常高,索引的检索可以一次定位,不像B-Tree 索引需要从根节点到枝节点,最后才能访问到页节点这样多次的IO访问,所以 Hash 索引的查询效率要远高于 B-Tree 索引。可 能很多人又有疑问了,既然 Hash 索引的效率要比 B-Tree 高很多,为什么大家不都用 Hash 索引而还要使用 B-Tree 索引呢?任何事物都是有两面性的,Hash 索引也一样,虽然 Hash 索引效率高,但是 Hash 索引本身由于其特殊性也带来了很多限制和弊端,主要有以下这些。(1)Hash 索引仅仅能满足"=","IN"和"<=>"查询,不能使用范围查询。由于 Hash 索引比较的是进行 Hash 运算之后的 Hash 值,所以它只能用于等值的过滤,不能用于基于范围的过滤,因为经过相应的 Hash 算法处理之后的 Hash 值的大小关系,并不能保证和Hash运算前完全一样。(2)Hash 索引无法被用来避免数据的排序操作。由于 Hash 索引中存放的是经过 Hash 计算之后的 Hash 值,而且Hash值的大小关系并不一定和 Hash 运算前的键值完全一样,所以数据库无法利用索引的数据来避免任何排序运算;(3)Hash 索引不能利用部分索引键查询。对于组合索引,Hash 索引在计算 Hash 值的时候是组合索引键合并后再一起计算 Hash 值,而不是单独计算 Hash 值,所以通过组合索引的前面一个或几个索引键进行查询的时候,Hash 索引也无法被利用。(4)Hash 索引在任何时候都不能避免表扫描。前面已经知道,Hash 索引是将索引键通过 Hash 运算之后,将 Hash运算结果的 Hash 值和所对应的行指针信息存放于一个 Hash 表中,由于不同索引键存在相同 Hash 值,所以即使取满足某个 Hash 键值的数据的记录条数,也无法从 Hash 索引中直接完成查询,还是要通过访问表中的实际数据进行相应的比较,并得到相应的结果。(5)Hash 索引遇到大量Hash值相等的情况后性能并不一定就会比B-Tree索引高。对于选择性比较低的索引键,如果创建 Hash 索引,那么将会存在大量记录指针信息存于同一个 Hash 值相关联。这样要定位某一条记录时就会非常麻烦,会浪费多次表数据的访问,而造成整体性能低下。单列索引和多列索引单列索引所有的MySQL列类型能被索引。在相关的列上的使用索引是改进SELECT操作性能的最好方法。一个表 最多可有16个索引。最大索引长度是256个字节 ,尽管这可以在编译MySQL时被改变。 对于CHAR和VARCHAR列,你可以索引列的前缀 。这更快并且比索引整个列需要较少的磁盘空间。在CREATE TABLE语句中索引列前缀的语法看起来像这样:KEY index_name (col_name(length))下面的例子 为name列的头10个字符创建一个索引 :mysql> CREATE TABLE test ( name CHAR(200) NOT NULL, KEY index_name (name(10)));对于 BLOB和TEXT列,你必须索引列的前缀,你不能索引列的全部。多列索引MySQL能 在多个列上创建索引。一个索引可以由最多15个列组成 。(在CHAR和VARCHAR列上,你也可以使用列的前缀作为一个索引的部分)。一个多重列索引可以认为是包含通过合并(concatenate)索引列值创建的值的一个排序数组。当你为 在一个WHERE子句索引的第一列指定已知的数量时,MySQL以这种方式使用多重列索引使得查询非常快速 ,即使你不为其他列指定值。假定一张表使用下列说明创建:mysql> CREATE TABLE test ( id INT NOT NULL, last_name CHAR(30) NOT NULL, first_name CHAR(30) NOT NULL, PRIMARY KEY (id), INDEX name (last_name,first_name));那么 索引name是一个在last_name和first_name上的索引 ,这个索引将被用于在last_name或last_name和first_name的一个已知范围内指定值的查询,因此,name索引 将使用在下列查询中:mysql> SELECT * FROM test WHERE last_name=”Widenius”; mysql> SELECT * FROM test WHERE last_name=”Widenius” AND first_name=”Michael”; mysql> SELECT * FROM test WHERE last_name=”Widenius” AND (first_name=”Michael” OR first_name=”Monty”); mysql> SELECT * FROM test WHERE last_name=”Widenius” AND first_name >=”M” AND first_name < "N";然而,name索引 将不用在下列询问中:mysql> SELECT * FROM test WHERE first_name=”Michael”; mysql> SELECT * FROM test WHERE last_name=”Widenius” OR first_name=”Michael”;创建 一个多列索引:CREATE TABLE test ( id INT NOT NULL, last_name CHAR(30) NOT NULL, first_name CHAR(30) NOT NULL, PRIMARY KEY (id), INDEX name (last_name,first_name) ); 创建 多个索引:CREATE TABLE test ( id INT NOT NULL, last_name CHAR(30) NOT NULL, first_name CHAR(30) NOT NULL, PRIMARY KEY (id), INDEX name (last_name), INDEX_2 name (first_name) ); 当查询语句的条件中包含last_name 和 first_name时,例如:SELECT * FROM test WHERE last_name='Kun' AND first_name='Li'; sql会先过滤出last_name符合条件的记录,在其基础上再过滤first_name符合条件的记录。那如果我们分别在last_name和first_name上创建两个列索引,mysql的处理方式就不一样了,它会选择一个最严格的索引来进行检索,可以理解为检索能力最强的那个索引来检索,另外一个利用不上了,这样效果就不如多列索引了。但是多列索引的利用也是需要条件的,以下形式的查询语句能够利用上多列索引:SELECT * FROM test WHERE last_name='Widenius'; SELECT * FROM test WHERE last_name='Widenius' AND first_name='Michael'; SELECT * FROM test WHERE last_name='Widenius' AND (first_name='Michael' OR first_name='Monty'); SELECT * FROM test WHERE last_name='Widenius' AND first_name >='M' AND first_name < 'N';以下形式的查询语句利用不上多列索引:SELECT * FROM test WHERE first_name='Michael'; SELECT * FROM test WHERE last_name='Widenius' OR first_name='Michael';多列建索引比对每个列分别建索引更有优势,因为索引建立得越多就越占磁盘空间,在更新数据的时候速度会更慢。另外建立多列索引时,顺序也是需要注意的,应该将严格的索引放在前面,这样筛选的力度会更大,效率更高。索引优化查看SQL语句对索引的使用情况锁技能点开发规范导入导出数据库blob和text的区别char与varchar类型区别SQL查询语句优化事务隔离和锁操作需要在语言级别来做吗58到家数据库30条军规解读数据迁移SKU数据库设计RBAC数据库设计计