搜索到
786
篇与
的结果
-
 用 PHP 读取和编写 XML DOM 用 PHP 读取和编写 XML DOM用 PHP 读取和编写可扩展标记语言(XML)看起来可能有点恐怖。实际上,XML 和它的所有相关技术可能是恐怖的,但是用 PHP 读取和编写 XML 不一定是项恐怖的任务。首先,需要学习一点关于 XML 的知识 —— 它是什么,用它做什么。然后,需要学习如何用 PHP 读取和编写 XML,而有许多种方式可以做这件事。本文提供了 XML 的简短入门,然后解释如何用 PHP 读取和编写 XML。什么是 XML?XML 是一种数据存储格式。它没有定义保存什么数据,也没有定义数据的格式。XML 只是定义了标记和这些标记的属性。格式良好的 XML 标记看起来像这样:Jack Herrington这个 标记包含一些文本:Jack Herrington。不包含文本的 XML 标记看起来像这样:用 XML 对某件事进行编写的方式不止一种。例如,这个标记形成的输出与前一个标记相同:也可以向 XML 标记添加属性。例如,这个 标记包含 first 和 last 属性:也可以用 XML 对特殊字符进行编码。例如,& 符号可以像这样编码:&包含标记和属性的 XML 文件如果像示例一样格式化,就是格式良好的,这意味着标记是对称的,字符的编码正确。清单 1 是一份格式良好的 XML 的示例。清单 1. XML 图书列表示例 Jack Herrington PHP Hacks O'Reilly Jack Herrington Podcasting Hacks O'Reilly 清单 1 中的 XML 包含一个图书列表。父标记 包含一组 标记,每个 标记又包含 、 和 标记。当 XML 文档的标记结构和内容得到外部模式文件的验证后,XML 文档就是正确的。模式文件可以用不同的格式指定。对于本文来说,所需要的只是格式良好的 XML。如果觉得 XML 看起来很像超文本标记语言(HTML),那么就对了。XML 和 HTML 都是基于标记的语言,它们有许多相似之处。但是,要着重指出的是:虽然 XML 文档可能是格式良好的 HTML,但不是所有的 HTML 文档都是格式良好的 XML。换行标记(br)是 XML 和 HTML 之间区别的一个好例子。这个换行标记是格式良好的 HTML,但不是格式良好的 XML:This is a paragraph With a line break这个换行标记是格式良好的 XML 和 HTML:This is a paragraph With a line break如果要把 HTML 编写成同样是格式良好的 XML,请遵循 W3C 委员会的可扩展超文本标记语言(XHTML)标准(参见 参考资料)。所有现代的浏览器都能呈现 XHTML。而且,还可以用 XML 工具读取 XHTML 并找出文档中的数据,这比解析 HTML 容易得多。回页首使用 DOM 库读取 XML读取格式良好的 XML 文件最容易的方式是使用编译成某些 PHP 安装的文档对象模型 (DOM)库。DOM 库把整个 XML 文档读入内存,并用节点树表示它,如图 1 所示。图 1. 图书 XML 的 XML DOM 树图书 XML 的 XML DOM 树树顶部的 books 节点有两个 book 子标记。在每本书中,有 author、publisher 和 title 几个节点。author、publisher 和title 节点分别有包含文本的文本子节点。读取图书 XML 文件并用 DOM 显示内容的代码如清单 2 所示。清单 2. 用 DOM 读取图书 XML<?php $doc = new DOMDocument(); $doc->load( 'books.xml' );$books = $doc->getElementsByTagName( "book" ); foreach( $books as $book ) { $authors = $book->getElementsByTagName( "author" ); $author = $authors->item(0)->nodeValue;$publishers = $book->getElementsByTagName( "publisher" ); $publisher = $publishers->item(0)->nodeValue;$titles = $book->getElementsByTagName( "title" ); $title = $titles->item(0)->nodeValue;echo "$title - $author - $publisher\n"; } ?>脚本首先创建一个 new DOMdocument 对象,用 load 方法把图书 XML 装入这个对象。之后,脚本用 getElementsByName 方法得到指定名称下的所有元素的列表。在 book 节点的循环中,脚本用 getElementsByName 方法获得 author、publisher 和 title 标记的 nodeValue。nodeValue是节点中的文本。脚本然后显示这些值。可以在命令行上像这样运行 PHP 脚本:% php e1.phpPHP Hacks - Jack Herrington - O'ReillyPodcasting Hacks - Jack Herrington - O'Reilly%可以看到,每个图书块输出一行。这是一个良好的开始。但是,如果不能访问 XML DOM 库该怎么办?回页首用 SAX 解析器读取 XML读取 XML 的另一种方法是使用 XML Simple API(SAX)解析器。PHP 的大多数安装都包含 SAX 解析器。SAX 解析器运行在回调模型上。每次打开或关闭一个标记时,或者每次解析器看到文本时,就用节点或文本的信息回调用户定义的函数。SAX 解析器的优点是,它是真正轻量级的。解析器不会在内存中长期保持内容,所以可以用于非常巨大的文件。缺点是编写 SAX 解析器回调是件非常麻烦的事。清单 3 显示了使用 SAX 读取图书 XML 文件并显示内容的代码。清单 3. 用 SAX 解析器读取图书 XML <?php $g_books = array(); $g_elem = null;function startElement( $parser, $name, $attrs ) { global $g_books, $g_elem; if ( $name == 'BOOK' ) $g_books []= array(); $g_elem = $name; }function endElement( $parser, $name ) { global $g_elem; $g_elem = null; }function textData( $parser, $text ) { global $g_books, $g_elem; if ( $g_elem == 'AUTHOR' || $g_elem == 'PUBLISHER' || $g_elem == 'TITLE' ) { $g_books[ count( $g_books ) - 1 ][ $g_elem ] = $text; } }$parser = xml_parser_create();xml_set_element_handler( $parser, "startElement", "endElement" ); xml_set_character_data_handler( $parser, "textData" );$f = fopen( 'books.xml', 'r' );while( $data = fread( $f, 4096 ) ) { xml_parse( $parser, $data ); }xml_parser_free( $parser );foreach( $g_books as $book ) { echo $book['TITLE']." - ".$book['AUTHOR']." - "; echo $book['PUBLISHER']."\n"; } ?>脚本首先设置 g_books 数组,它在内存中容纳所有图书和图书信息,g_elem 变量保存脚本目前正在处理的标记的名称。然后脚本定义回调函数。在这个示例中,回调函数是 startElement、endElement 和 textData。在打开和关闭标记的时候,分别调用startElement 和 endElement 函数。在开始和结束标记之间的文本上面,调用 textData。在这个示例中,startElement 标记查找 book 标记,在 book 数组中开始一个新元素。然后,textData 函数查看当前元素,看它是不是 publisher、title 或 author 标记。如果是,函数就把当前文本放入当前图书。为了让解析继续,脚本用 xml_parser_create 函数创建解析器。然后,设置回调句柄。之后,脚本读取文件并把文件的大块内容发送到解析器。在文件读取之后,xml_parser_free 函数删除解析器。脚本的末尾输出 g_books 数组的内容。可以看到,这比编写 DOM 的同样功能要困难得多。如果没有 DOM 库也没有 SAX 库该怎么办?还有替代方案么?回页首用正则表达式解析 XML可以肯定,即使提到这个方法,有些工程师也会批评我,但是确实可以用正则表达式解析 XML。清单 4 显示了使用 preg_ 函数读取图书文件的示例。清单 4. 用正则表达式读取 XML<?php $xml = ""; $f = fopen( 'books.xml', 'r' ); while( $data = fread( $f, 4096 ) ) { $xml .= $data; } fclose( $f );preg_match_all( "/\<book\>(.*?)\</book\>/s", $xml, $bookblocks );foreach( $bookblocks[1] as $block ) { preg_match_all( "/\<author\>(.*?)\</author\>/", $block, $author ); preg_match_all( "/\<title\>(.*?)\</title\>/", $block, $title ); preg_match_all( "/\<publisher\>(.*?)\</publisher\>/", $block, $publisher ); echo( $title[1][0]." - ".$author1." - ". $publisher1."\n" ); } ?>请注意这个代码有多短。开始时,它把文件读进一个大的字符串。然后用一个 regex 函数读取每个图书项目。最后用 foreach 循环,在每个图书块间循环,并提取出 author、title 和 publisher。那么,缺陷在哪呢?使用正则表达式代码读取 XML 的问题是,它并没先进行检查,确保 XML 的格式良好。这意味着在读取之前,无法知道 XML 是否格式良好。而且,有些格式正确的 XML 可能与正则表达式不匹配,所以日后必须修改它们。我从不建议使用正则表达式读取 XML,但是有时它是兼容性最好的方式,因为正则表达式函数总是可用的。不要用正则表达式读取直接来自用户的 XML,因为无法控制这类 XML 的格式或结构。应当一直用 DOM 库或 SAX 解析器读取来自用户的 XML。回页首用 DOM 编写 XML读取 XML 只是公式的一部分。该怎样编写 XML 呢?编写 XML 最好的方式就是用 DOM。清单 5 显示了 DOM 构建图书 XML 文件的方式。清单 5. 用 DOM 编写图书 XML<?php $books = array(); $books [] = array( 'title' => 'PHP Hacks', 'author' => 'Jack Herrington', 'publisher' => "O'Reilly" ); $books [] = array( 'title' => 'Podcasting Hacks', 'author' => 'Jack Herrington', 'publisher' => "O'Reilly" );$doc = new DOMDocument(); $doc->formatOutput = true;$r = $doc->createElement( "books" ); $doc->appendChild( $r );foreach( $books as $book ) { $b = $doc->createElement( "book" );$author = $doc->createElement( "author" ); $author->appendChild( $doc->createTextNode( $book['author'] ) ); $b->appendChild( $author );$title = $doc->createElement( "title" ); $title->appendChild( $doc->createTextNode( $book['title'] ) ); $b->appendChild( $title );$publisher = $doc->createElement( "publisher" ); $publisher->appendChild( $doc->createTextNode( $book['publisher'] ) ); $b->appendChild( $publisher );$r->appendChild( $b ); }echo $doc->saveXML(); ?>在脚本的顶部,用一些示例图书装入了 books 数组。这个数据可以来自用户也可以来自数据库。示例图书装入之后,脚本创建一个 new DOMDocument,并把根节点 books 添加到它。然后脚本为每本书的 author、title 和 publisher 创建节点,并为每个节点添加文本节点。每个 book 节点的最后一步是重新把它添加到根节点 books。脚本的末尾用 saveXML 方法把 XML 输出到控制台。(也可以用 save 方法创建一个 XML 文件。)脚本的输出如清单 6 所示。清单 6. DOM 构建脚本的输出% php e4.php <?xml version="1.0"?> Jack Herrington PHP Hacks O'Reilly Jack Herrington Podcasting Hacks O'Reilly %使用 DOM 的真正价值在于它创建的 XML 总是格式正确的。但是如果不能用 DOM 创建 XML 时该怎么办?回页首用 PHP 编写 XML如果 DOM 不可用,可以用 PHP 的文本模板编写 XML。清单 7 显示了 PHP 如何构建图书 XML 文件。清单 7. 用 PHP 编写图书 XML<?php $books = array(); $books [] = array( 'title' => 'PHP Hacks', 'author' => 'Jack Herrington', 'publisher' => "O'Reilly" ); $books [] = array( 'title' => 'Podcasting Hacks', 'author' => 'Jack Herrington', 'publisher' => "O'Reilly" ); ?> <?phpforeach( $books as $book ) { ?> <?php echo( $book['title'] ); ?> <?php echo( $book['author'] ); ?> <?php echo( $book['publisher'] ); ?> <?php } ?> 脚本的顶部与 DOM 脚本类似。脚本的底部打开 books 标记,然后在每个图书中迭代,创建 book 标记和所有的内部title、author 和 publisher 标记。这种方法的问题是对实体进行编码。为了确保实体编码正确,必须在每个项目上调用 htmlentities 函数,如清单 8 所示。清单 8. 使用 htmlentities 函数对实体编码 <?phpforeach( $books as $book ) { $title = htmlentities( $book['title'], ENT_QUOTES ); $author = htmlentities( $book['author'], ENT_QUOTES ); $publisher = htmlentities( $book['publisher'], ENT_QUOTES ); ?> <?php echo( $title ); ?> <?php echo( $author ); ?> <?php echo( $publisher ); ?> <?php } ?> 这就是用基本的 PHP 编写 XML 的烦人之处。您以为自己创建了完美的 XML,但是在试图使用数据的时候,马上就会发现某些元素的编码不正确。回页首结束语XML 周围总有许多夸大之处和混淆之处。但是,并不像您想像的那么难 —— 特别是在 PHP 这样优秀的语言中。在理解并正确地实现了 XML 之后,就会发现有许多强大的工具可以使用。XPath 和 XSLT 就是这样两个值得研究的工具。参考资料学习您可以参阅本文在 developerWorks 全球站点上的 英文原文。在 XHTML 1.0 The Extensible HyperText Markup Language 上学习 XHTML 的标准。找到 standards for XML。了解 XML Path (XPath) language。了解 XSL Transformations,这是用于转换 XML 的语言。请阅读用来定义 XML 文档结构的标准 XML Schema。在 developerWorks 的 XML 专区 找到面向 XML 开发人员的更多资源。请访问 developerWorks 的 开放源码专区 获得全面的 how-to 信息、工具和项目更新,帮助您用开放源码技术开发并把它们用于 IBM 产品。获得产品和技术请访问 PHP.net,了解关于 PHP 的最新新闻、找到下载,并向其他用户学习。了解 Expat XML Parser,这个解析器用来向 PHP 提供 SAX 解析器功能。利用 IBM 试用软件 改造您的下一个开放源码开发项目,可以下载也可以通过 DVD 得到。讨论通过参与 developerWorks blogs 加入 developerWorks 社区。关于作者Jack D. Herrington 是有 20 多年经验的高级软件工程师。他是三本书的作者:Code Generation in Action、Podcasting Hacks 和即将发表的 PHP Hacks。他还撰写了 30 多篇文章。
用 PHP 读取和编写 XML DOM 用 PHP 读取和编写 XML DOM用 PHP 读取和编写可扩展标记语言(XML)看起来可能有点恐怖。实际上,XML 和它的所有相关技术可能是恐怖的,但是用 PHP 读取和编写 XML 不一定是项恐怖的任务。首先,需要学习一点关于 XML 的知识 —— 它是什么,用它做什么。然后,需要学习如何用 PHP 读取和编写 XML,而有许多种方式可以做这件事。本文提供了 XML 的简短入门,然后解释如何用 PHP 读取和编写 XML。什么是 XML?XML 是一种数据存储格式。它没有定义保存什么数据,也没有定义数据的格式。XML 只是定义了标记和这些标记的属性。格式良好的 XML 标记看起来像这样:Jack Herrington这个 标记包含一些文本:Jack Herrington。不包含文本的 XML 标记看起来像这样:用 XML 对某件事进行编写的方式不止一种。例如,这个标记形成的输出与前一个标记相同:也可以向 XML 标记添加属性。例如,这个 标记包含 first 和 last 属性:也可以用 XML 对特殊字符进行编码。例如,& 符号可以像这样编码:&包含标记和属性的 XML 文件如果像示例一样格式化,就是格式良好的,这意味着标记是对称的,字符的编码正确。清单 1 是一份格式良好的 XML 的示例。清单 1. XML 图书列表示例 Jack Herrington PHP Hacks O'Reilly Jack Herrington Podcasting Hacks O'Reilly 清单 1 中的 XML 包含一个图书列表。父标记 包含一组 标记,每个 标记又包含 、 和 标记。当 XML 文档的标记结构和内容得到外部模式文件的验证后,XML 文档就是正确的。模式文件可以用不同的格式指定。对于本文来说,所需要的只是格式良好的 XML。如果觉得 XML 看起来很像超文本标记语言(HTML),那么就对了。XML 和 HTML 都是基于标记的语言,它们有许多相似之处。但是,要着重指出的是:虽然 XML 文档可能是格式良好的 HTML,但不是所有的 HTML 文档都是格式良好的 XML。换行标记(br)是 XML 和 HTML 之间区别的一个好例子。这个换行标记是格式良好的 HTML,但不是格式良好的 XML:This is a paragraph With a line break这个换行标记是格式良好的 XML 和 HTML:This is a paragraph With a line break如果要把 HTML 编写成同样是格式良好的 XML,请遵循 W3C 委员会的可扩展超文本标记语言(XHTML)标准(参见 参考资料)。所有现代的浏览器都能呈现 XHTML。而且,还可以用 XML 工具读取 XHTML 并找出文档中的数据,这比解析 HTML 容易得多。回页首使用 DOM 库读取 XML读取格式良好的 XML 文件最容易的方式是使用编译成某些 PHP 安装的文档对象模型 (DOM)库。DOM 库把整个 XML 文档读入内存,并用节点树表示它,如图 1 所示。图 1. 图书 XML 的 XML DOM 树图书 XML 的 XML DOM 树树顶部的 books 节点有两个 book 子标记。在每本书中,有 author、publisher 和 title 几个节点。author、publisher 和title 节点分别有包含文本的文本子节点。读取图书 XML 文件并用 DOM 显示内容的代码如清单 2 所示。清单 2. 用 DOM 读取图书 XML<?php $doc = new DOMDocument(); $doc->load( 'books.xml' );$books = $doc->getElementsByTagName( "book" ); foreach( $books as $book ) { $authors = $book->getElementsByTagName( "author" ); $author = $authors->item(0)->nodeValue;$publishers = $book->getElementsByTagName( "publisher" ); $publisher = $publishers->item(0)->nodeValue;$titles = $book->getElementsByTagName( "title" ); $title = $titles->item(0)->nodeValue;echo "$title - $author - $publisher\n"; } ?>脚本首先创建一个 new DOMdocument 对象,用 load 方法把图书 XML 装入这个对象。之后,脚本用 getElementsByName 方法得到指定名称下的所有元素的列表。在 book 节点的循环中,脚本用 getElementsByName 方法获得 author、publisher 和 title 标记的 nodeValue。nodeValue是节点中的文本。脚本然后显示这些值。可以在命令行上像这样运行 PHP 脚本:% php e1.phpPHP Hacks - Jack Herrington - O'ReillyPodcasting Hacks - Jack Herrington - O'Reilly%可以看到,每个图书块输出一行。这是一个良好的开始。但是,如果不能访问 XML DOM 库该怎么办?回页首用 SAX 解析器读取 XML读取 XML 的另一种方法是使用 XML Simple API(SAX)解析器。PHP 的大多数安装都包含 SAX 解析器。SAX 解析器运行在回调模型上。每次打开或关闭一个标记时,或者每次解析器看到文本时,就用节点或文本的信息回调用户定义的函数。SAX 解析器的优点是,它是真正轻量级的。解析器不会在内存中长期保持内容,所以可以用于非常巨大的文件。缺点是编写 SAX 解析器回调是件非常麻烦的事。清单 3 显示了使用 SAX 读取图书 XML 文件并显示内容的代码。清单 3. 用 SAX 解析器读取图书 XML <?php $g_books = array(); $g_elem = null;function startElement( $parser, $name, $attrs ) { global $g_books, $g_elem; if ( $name == 'BOOK' ) $g_books []= array(); $g_elem = $name; }function endElement( $parser, $name ) { global $g_elem; $g_elem = null; }function textData( $parser, $text ) { global $g_books, $g_elem; if ( $g_elem == 'AUTHOR' || $g_elem == 'PUBLISHER' || $g_elem == 'TITLE' ) { $g_books[ count( $g_books ) - 1 ][ $g_elem ] = $text; } }$parser = xml_parser_create();xml_set_element_handler( $parser, "startElement", "endElement" ); xml_set_character_data_handler( $parser, "textData" );$f = fopen( 'books.xml', 'r' );while( $data = fread( $f, 4096 ) ) { xml_parse( $parser, $data ); }xml_parser_free( $parser );foreach( $g_books as $book ) { echo $book['TITLE']." - ".$book['AUTHOR']." - "; echo $book['PUBLISHER']."\n"; } ?>脚本首先设置 g_books 数组,它在内存中容纳所有图书和图书信息,g_elem 变量保存脚本目前正在处理的标记的名称。然后脚本定义回调函数。在这个示例中,回调函数是 startElement、endElement 和 textData。在打开和关闭标记的时候,分别调用startElement 和 endElement 函数。在开始和结束标记之间的文本上面,调用 textData。在这个示例中,startElement 标记查找 book 标记,在 book 数组中开始一个新元素。然后,textData 函数查看当前元素,看它是不是 publisher、title 或 author 标记。如果是,函数就把当前文本放入当前图书。为了让解析继续,脚本用 xml_parser_create 函数创建解析器。然后,设置回调句柄。之后,脚本读取文件并把文件的大块内容发送到解析器。在文件读取之后,xml_parser_free 函数删除解析器。脚本的末尾输出 g_books 数组的内容。可以看到,这比编写 DOM 的同样功能要困难得多。如果没有 DOM 库也没有 SAX 库该怎么办?还有替代方案么?回页首用正则表达式解析 XML可以肯定,即使提到这个方法,有些工程师也会批评我,但是确实可以用正则表达式解析 XML。清单 4 显示了使用 preg_ 函数读取图书文件的示例。清单 4. 用正则表达式读取 XML<?php $xml = ""; $f = fopen( 'books.xml', 'r' ); while( $data = fread( $f, 4096 ) ) { $xml .= $data; } fclose( $f );preg_match_all( "/\<book\>(.*?)\</book\>/s", $xml, $bookblocks );foreach( $bookblocks[1] as $block ) { preg_match_all( "/\<author\>(.*?)\</author\>/", $block, $author ); preg_match_all( "/\<title\>(.*?)\</title\>/", $block, $title ); preg_match_all( "/\<publisher\>(.*?)\</publisher\>/", $block, $publisher ); echo( $title[1][0]." - ".$author1." - ". $publisher1."\n" ); } ?>请注意这个代码有多短。开始时,它把文件读进一个大的字符串。然后用一个 regex 函数读取每个图书项目。最后用 foreach 循环,在每个图书块间循环,并提取出 author、title 和 publisher。那么,缺陷在哪呢?使用正则表达式代码读取 XML 的问题是,它并没先进行检查,确保 XML 的格式良好。这意味着在读取之前,无法知道 XML 是否格式良好。而且,有些格式正确的 XML 可能与正则表达式不匹配,所以日后必须修改它们。我从不建议使用正则表达式读取 XML,但是有时它是兼容性最好的方式,因为正则表达式函数总是可用的。不要用正则表达式读取直接来自用户的 XML,因为无法控制这类 XML 的格式或结构。应当一直用 DOM 库或 SAX 解析器读取来自用户的 XML。回页首用 DOM 编写 XML读取 XML 只是公式的一部分。该怎样编写 XML 呢?编写 XML 最好的方式就是用 DOM。清单 5 显示了 DOM 构建图书 XML 文件的方式。清单 5. 用 DOM 编写图书 XML<?php $books = array(); $books [] = array( 'title' => 'PHP Hacks', 'author' => 'Jack Herrington', 'publisher' => "O'Reilly" ); $books [] = array( 'title' => 'Podcasting Hacks', 'author' => 'Jack Herrington', 'publisher' => "O'Reilly" );$doc = new DOMDocument(); $doc->formatOutput = true;$r = $doc->createElement( "books" ); $doc->appendChild( $r );foreach( $books as $book ) { $b = $doc->createElement( "book" );$author = $doc->createElement( "author" ); $author->appendChild( $doc->createTextNode( $book['author'] ) ); $b->appendChild( $author );$title = $doc->createElement( "title" ); $title->appendChild( $doc->createTextNode( $book['title'] ) ); $b->appendChild( $title );$publisher = $doc->createElement( "publisher" ); $publisher->appendChild( $doc->createTextNode( $book['publisher'] ) ); $b->appendChild( $publisher );$r->appendChild( $b ); }echo $doc->saveXML(); ?>在脚本的顶部,用一些示例图书装入了 books 数组。这个数据可以来自用户也可以来自数据库。示例图书装入之后,脚本创建一个 new DOMDocument,并把根节点 books 添加到它。然后脚本为每本书的 author、title 和 publisher 创建节点,并为每个节点添加文本节点。每个 book 节点的最后一步是重新把它添加到根节点 books。脚本的末尾用 saveXML 方法把 XML 输出到控制台。(也可以用 save 方法创建一个 XML 文件。)脚本的输出如清单 6 所示。清单 6. DOM 构建脚本的输出% php e4.php <?xml version="1.0"?> Jack Herrington PHP Hacks O'Reilly Jack Herrington Podcasting Hacks O'Reilly %使用 DOM 的真正价值在于它创建的 XML 总是格式正确的。但是如果不能用 DOM 创建 XML 时该怎么办?回页首用 PHP 编写 XML如果 DOM 不可用,可以用 PHP 的文本模板编写 XML。清单 7 显示了 PHP 如何构建图书 XML 文件。清单 7. 用 PHP 编写图书 XML<?php $books = array(); $books [] = array( 'title' => 'PHP Hacks', 'author' => 'Jack Herrington', 'publisher' => "O'Reilly" ); $books [] = array( 'title' => 'Podcasting Hacks', 'author' => 'Jack Herrington', 'publisher' => "O'Reilly" ); ?> <?phpforeach( $books as $book ) { ?> <?php echo( $book['title'] ); ?> <?php echo( $book['author'] ); ?> <?php echo( $book['publisher'] ); ?> <?php } ?> 脚本的顶部与 DOM 脚本类似。脚本的底部打开 books 标记,然后在每个图书中迭代,创建 book 标记和所有的内部title、author 和 publisher 标记。这种方法的问题是对实体进行编码。为了确保实体编码正确,必须在每个项目上调用 htmlentities 函数,如清单 8 所示。清单 8. 使用 htmlentities 函数对实体编码 <?phpforeach( $books as $book ) { $title = htmlentities( $book['title'], ENT_QUOTES ); $author = htmlentities( $book['author'], ENT_QUOTES ); $publisher = htmlentities( $book['publisher'], ENT_QUOTES ); ?> <?php echo( $title ); ?> <?php echo( $author ); ?> <?php echo( $publisher ); ?> <?php } ?> 这就是用基本的 PHP 编写 XML 的烦人之处。您以为自己创建了完美的 XML,但是在试图使用数据的时候,马上就会发现某些元素的编码不正确。回页首结束语XML 周围总有许多夸大之处和混淆之处。但是,并不像您想像的那么难 —— 特别是在 PHP 这样优秀的语言中。在理解并正确地实现了 XML 之后,就会发现有许多强大的工具可以使用。XPath 和 XSLT 就是这样两个值得研究的工具。参考资料学习您可以参阅本文在 developerWorks 全球站点上的 英文原文。在 XHTML 1.0 The Extensible HyperText Markup Language 上学习 XHTML 的标准。找到 standards for XML。了解 XML Path (XPath) language。了解 XSL Transformations,这是用于转换 XML 的语言。请阅读用来定义 XML 文档结构的标准 XML Schema。在 developerWorks 的 XML 专区 找到面向 XML 开发人员的更多资源。请访问 developerWorks 的 开放源码专区 获得全面的 how-to 信息、工具和项目更新,帮助您用开放源码技术开发并把它们用于 IBM 产品。获得产品和技术请访问 PHP.net,了解关于 PHP 的最新新闻、找到下载,并向其他用户学习。了解 Expat XML Parser,这个解析器用来向 PHP 提供 SAX 解析器功能。利用 IBM 试用软件 改造您的下一个开放源码开发项目,可以下载也可以通过 DVD 得到。讨论通过参与 developerWorks blogs 加入 developerWorks 社区。关于作者Jack D. Herrington 是有 20 多年经验的高级软件工程师。他是三本书的作者:Code Generation in Action、Podcasting Hacks 和即将发表的 PHP Hacks。他还撰写了 30 多篇文章。 -
再一次, 不要使用(include/require)_once 再一次, 不要使用(include/require)_once最近关于apc.include_once_override的去留, 我们做了几次讨论, 这个APC的配置项一直一来就没有被很好的实现过.在这里, 我想和大家在此分享下, 这个问题的原因, 以及对我们的一些启示.关于使用include还是include_once(以下,都包含require_once), 这个讨论很长了, 结论也一直有, 就是尽量使用include, 而不是include_once, 以前最多的理由的是, include_once需要查询一遍已加载的文件列表, 确认是否存在, 然后再加载.诚然, 这个理由是对的, 不过, 我今天要说的, 是另外一个的原因.我们知道, PHP去判断一个文件是否被加载, 是需要得到这个文件的opened_path的, 意思是说, 比如:<?php set_include_path("/tmp/:/tmp2/"); include_once("2.php"); ?>当PHP看到include_once "2.php"的时候, 他并不知道这个文件的实际路径是什么, 也就无法从已加载的文件列表去判断是否已经加载, 所以在include_once的实现中, 会首先尝试解析这个文件的真实路径(对于普通文件这个解析仅仅类似是检查getcwd和文件路径, 所以如果是相对路径, 一般是不会成功), 如果解析成功, 则查找EG(include_files), 如果存在则说明包含过了, 返回, 否则open这个文件, 从而得到这个文件的opened_path. 比如上面的例子, 这个文件存在于 "/tmp2/2.php".然后, 得到了这个opened_path以后, PHP去已加载的文件列表去查找, 是否已经包含, 如果没有包含, 那么就直接compile, 不再需要open file了.尝试解析文件的绝对路径, 如果能解析成功, 则检查EG(included_files), 存在则返回, 不存在继续打开文件, 得到文件的打开路径(opened path)拿opened path去EG(included_files)查找, 是否存在, 如果存在则返回, 不存在继续编译文件(compile_file)这个在大多数情况下, 不是问题, 然而问题出在当你使用APC的时候...在使用APC的时候, APC劫持了compile_file这个编译文件的指针, 从而直接从cache中得到编译结果, 避免了对实际文件的open, 避免了对open的system call.然而, 当你在代码中使用include_once的时候, 在compile_file之前, PHP已经尝试去open file了, 然后才进入被APC劫持的compile file中, 这样一来, 就会产生一次额外的open操作. 而APC正是为了解决这个问题, 引入了include_once_override, 在include_once_override开启的情况下, APC会劫持PHP的ZEND_INCLUDE_OR_EVAL opcode handler, 通过stat来确定文件的绝对路径, 然后如果发现没有被加载, 就改写opcode为include, 做一个tricky解决方案.但是, 很可惜, 如我所说, APC的include_once_override实现的一直不好, 会有一些未定义的问题, 比如:<?php set_include_path("/tmp"); function a($arg = array()) { include_once("b.php"); } a(); a(); ?>然后, 我们的b.php放置在"/tmp/b.php", 内容如下:<?php class B {} ?>那么在打开apc.include_once_override的情况下, 连续访问就会得到如下错误:Fatal error - include() : Cannot redeclare class b(后记 2012-09-15 02:07:20: 这个APC的bug我已经修复: #63070)排除这些技术因素, 我也一直认为, 我们应该使用include, 而不是include_once, 因为我们完全能做到自己规划, 一个文件只被加载一次. 还可以借助自动加载, 来做到这一点.你使用include_once, 只能证明, 你对自己的代码没信心.所以, 建议大家, 不要再使用include_once
-
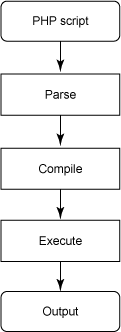
调优您的 LAMP 应用程序的 5 种简单方法 调优您的 LAMP 应用程序的 5 种简单方法简介Wikipedia、Facebook 和 Yahoo! 等主要 web 属性使用 LAMP 架构来为每天数百万的请求提供服务,而 Wordpress、Joomla、Drupal 和 SugarCRM 等 web 应用程序软件使用其架构来让组织轻松部署基于 web 的应用程序。该架构的优势在于其简单性。而 .NET 这样的堆栈和 Java™ 技术可能使用大量硬件、昂贵的软件栈和复杂的性能调优,LAMP 堆栈可以运行于商品硬件之上,使用开源软件栈。由于软件栈是一个松散的组件集,而非一个整体堆栈,性能调优是一大挑战,因为需要分析和调优每个组件。然而,这有几个个简单性能任务会对任何规模的网站的性能产生巨大的影响。在本文中,我们将探讨旨在优化 LAMP 应用程序性能的 5 个这样的任务。这些项目应当很少需要对您的应用程序进行架构更改,使其成为最大化您的 web 应用程序所需的响应能力和硬件需求的安全、便捷的选择。使用操作码缓存提高任何 PHP 应用程序(当然是 LAMP 中的 “P”)的性能的最简单方式是利用一个操作码缓存。对于我使用的任何网站,它是我确保存在的一项内容,因为性能影响很大(很多时候有了操作码缓存,响应时间可减少一半)。但是对 PHP 不熟悉的大部分人的一个很大的疑问是,为何改进会如此之大。答案在于 PHP 如何处理 web 请求。图 1 概览了 PHP 请求的流程。图 1. PHP 请求图表展示 PHP 请求的流程,从 PHP 脚本到解析到最后的输出由于 PHP 是一种解释语言,而非 C 或 Java 等编译语言,对每个请求执行了 “解析-编译-执行” 的整个步骤。您可以看到为何这会耗时、耗资源,特别是当脚本在请求之间很少变化时。解析和编译脚本之后,脚本作为一系列操作码处于机器可解析状态。这是操作码缓存发挥效用的地方。它作为一系列操作码缓存这些编译脚本,以避免为解析和编译每个请求步骤。您将在图 2 中看到这样的工作流是如何运作的。图 2. PHP 请求使用操作码缓存流程图展示逻辑流如何检查缓存的操作码并跳过解析和编译步骤(如果有的话)因此当 PHP 脚本的缓存操作码存在时,我们可以跳过 PHP 请求流程的解析和编译步骤,直接执行缓存操作码并输出结果。检查算法负责处理您可能对脚本文件进行了更改的情况,因此在已变更脚本的第一个请求后,会为随后的请求自动重新编译和缓存操作码,替换缓存的脚本。操作码缓存对于 PHP 流行已久,其中早期的一些要追溯到 PHP V4 的全盛期。目前有一些流行选项正在积极开发和使用中:替代 PHP 缓存(APC)可能是 PHP 最流行的操作码缓存(参见 参考资料)。它由若干核心 PHP 开发人员所开发,做出了很大贡献,Facebook 和 Yahoo! 的工程师赋予了其速度和稳定性。它还支持用于处理 PHP 请求的若干其他速度改进,包括一个用户缓存组件,这将在本文后面探讨。Wincache 是主要由 Microsoft® 的 Internet Information Services (IIS) 团队积极开发的一个操作码缓存,仅供在使用 IIS web 服务器的 Windows® 上使用(参见 参考资料)。开发它的主要动力在于使 PHP 成为 Windows-IIS-PHP 堆栈上的一流开发平台,因为据知 APC 在该堆栈上运作的不是很好。它在功能上非常类似于 APC,且支持一个用户缓存组件,以及一个内置会话处理程序,以将 Wincache 作为一个会话处理程序直接加以利用。eAccelerator 是原始 PHP 缓存之一 Turck MMCache 操作码缓存(参见 参考资料)的一个派生。不同于 APC 和 Wincache,它仅是一个操作码缓存和优化器,因此它不包含用户缓存组件。它在 UNIX® 和 Windows 堆栈上完全兼容,且对于不打算利用 APC 或 Wincache 提供的其他功能的站点很流行。如果您要使用 memcache 这样的解决方案来为多 web 服务器环境提供一个单独的用户缓存服务器,那么这就是常见情况。毫无疑问,一个操作码缓存是通过在每次请求后消除解析和编译脚本的需要来加速 PHP 的第一步。完成第一步之后,您应当看到响应时间和服务器负载方面的改进。但是优化 PHP 可以做的不止这些,我们接下来将加以讨论。优化您的 PHP 设置虽然实现操作码缓存是性能改进的一大创举,不过也有大量其他优化选项可供您基于 php.ini 文件中的设置优化您的 PHP 设置。这些设置更适合于生产实例;在开发或测试实例上,您可能不希望做这些变更,因为它会使得应用程序问题的调试变得更难。让我们看一下对于性能提升很重要的一些项目。应当禁用的选项有若干 php.ini 设置应当予以禁用,因为它们常用作向后兼容性:register_globals — 在 PHP V4.2 之前该功能常常是默认值,其中传入的请求变量被自动赋给普通 PHP 变量。这样做除了引起重大安全问题之外(使未过滤的传入请求数据与普通 PHP 变量内容相混),对每一个请求这样做还会产生开销。因此禁用这一设置使您的应用程序更安全且能提高性能。magic_quotes_* — 这是 PHP V4 的另一遗留项,其中传入的数据会自动避开有风险的表单数据。它旨在作为一个安全特性,在将传入的数据发送到数据库之前对其进行整理,但不是很有效,因为它不能帮助用户预防常见的 SQL 注入攻击。由于大部分数据库层支持能更好地处理该风险的准备语句,禁用该设置会再次消除这个烦人的性能问题。always_populate_raw_post_data — 这仅当您出于某些原因需要查看传入的未过滤 POST 数据的整个负载时才需要。否则,它仅在内存中存储 POST 数据的一个副本,而这没有必要。然而,在遗留代码上禁用这些选项会有风险,因为它们可能取决于其设置来实现正确执行。不应当基于被设置的这些选项来开发任何新代码,而且可能的话,您应当寻求方法来重构您的现有代码,避免使用它们。应当禁用或调整设置的选项您可以启用 php.ini 文件的一些优秀性能选项,来提升您的脚本速度:output_buffering — 您应当确保启用该选项,因为它会以块为单位将输出刷回到浏览器,而非以每个 echo 或 print 语句为单位,而后者会大大减缓您的请求响应时间。variables_order — 这个指令控制传入请求的 EGPCS(Environment、Get、Post、Cookie 和 Server)变量解析顺序。如果您没有使用某种超全局变量(比如环境变量),您可以安全地删除它们来获得一点加速,从而避免在每一个请求上解析它们。date.timezone — 这是在 PHP V5.1 中添加的一个指令,用于设置默认时区,然后用于后面将要介绍的 DateTime 函数。如果您不在 php.ini 文件中设置该选项,PHP 会执行大量系统请求来弄清它是什么,且在 PHP V5.3 中,对每一个请求会发出一个警告。就以应当在您的生产实例上配置的设置而言,这些被看作是 “唾手可得”。就 PHP 而言,还有一件事需要考虑。这就是您的应用程序中 require() 和 include()(以及其同级 require_once() 和 include_once())的使用。这些函数优化您的 PHP 配置和代码,以防止对每个请求进行不必要的文件状态检查,从而减少响应时间。管理您的 require() 和 include()从性能来看,文件状态调用(即为检查一个文件是否存在而对底层文件系统进行的调用)相当昂贵。文件状态的最大元凶之一以 require() 和 include() 语句的形式出现,这两个语句用于将代码带到脚本中。require_once() 和 include_once() 的同级调用更成问题,因为它们不仅需要验证文件是否存在,而且它之前没有包含在内。那么解决这个问题的最好方式是什么?您可以做一些事来加快解决。为所有 require() 和 include() 调用使用绝对路径。这将使 PHP 更清楚您希望包含的确切文件,因此无需为您的文件检查整个 include_path。保持 include_path 中的条目数较低。这在很难为每个 require() 和 include() 调用提供绝对路径的情况(通常在大型遗留应用程序中会出现这种情况)下很有用,方法就是不检查您包含的文件不在的位置。APC 和 Wincache 还有用于缓存 PHP 进行的文件状态检查结果的机制,因此无需进行反复的文件系统检查。当您将 include 文件名保留为静态而非变量驱动的时,它们最有效,因此尽可能尝试这样做很有用。优化您的数据库数据库优化很快会成为一个前沿话题,我几乎没有空间在这里完全公正地做这个话题。但是如果您在寻求优化您的数据库的速度,首先应当采取一些步骤,这应当对常见问题有所帮助。将数据库放在自己的机器上数据库查询自身可以变得相当激烈,通常在对大小合理的数据集执行简单的 SELECT 语句时限定在 100% 的 CPU。如果您的 web 服务器和数据库服务器都在竟用单一机器上的 CPU 时间,这无疑将减慢您的请求速度。因此我想第一步最好是将 web 服务器和数据库服务器放在单独的机器上,确保您的数据库服务器是两者中更强健的(数据库服务器喜欢大量内存和多个 CPU)。合理设计和编制表索引数据库性能的最大问题可能源自于不良数据库设计和缺失索引。SELECT 语句通常是运行在典型 web 应用程序中的最常见的查询类型。它们也是在数据库服务器上运行的最耗时的查询。此外,这些类型的 SQL 语句对适当的索引和数据库设计最敏感,因此查看以下指示,获取实现最优性能的技巧。确保每个表都有一个主键。这为表提供一个默认顺序和快速方式来联接其他表。确保一个表中的任何外键(即链接记录到另一个表中的记录的键)的索引得到合理编制。许多数据库会自动对这些键施加约束,以便值真正匹配另一个表中的一条记录,这有助于摆脱这一困难。试图限制一个表中的列数。一个表中有太多列比仅有一些列时进行查询所需的扫描时间要长。此外,如果您有不常用的含多个列的一个表,您也在通过 NULL 值字段浪费磁盘空间。文本或 blob 等可变大小字段也是如此,其中表大小的增长可以远超过需求。在这种情况下,您应当考虑将其他栏分成不同的表,在记录的主键上将其联合起来。分析在服务器上运行的查询改进数据库性能的最佳方法是分析在您的数据库服务器上运行什么查询,且运行它们需要多长时间。几乎每个数据库都有具有这种功能的工具。对于 MySQL,您可以利用慢查询日志来查找有问题的查询。要使用它,在 MySQL 配置文件中将 slow_query_log 设置为 1,然后将 log_output 设置为 FILE,将它们记录到文件 hostname-slow.log 中。您可以设置 long_query_time 阈值,确定查询必须运行多少秒才被看作是 “慢查询”。我想建议将该阈值首先设置为 5 秒,随着时间的推移将其缩减为 1 秒,具体取决于您的数据集。如果您探究该文件,您会看到类似于清单 1 的详细查询。清单 1. MySQL 慢查询日志/usr/local/mysql/bin/mysqld, Version: 5.1.49-log, started with: Tcp port: 3306 Unix socket: /tmp/mysql.sock Time Id Command Argument //Time: 030207 15:03:33 //User@Host: user[user] @ localhost.localdomain [127.0.0.1] //Query_time: 13 Lock_time: 0 Rows_sent: 117 Rows_examined: 234 use sugarcrm; select * from accounts inner join leads on accounts.id = leads.account_id;我们想要考虑的关键对象是 Query_time,显示查询需要的时间。另一项要考虑的是 Rows_sent 和 Rows_examined 的数量,因为这些可指这样的情况:其中如果一个查询察看太多行或返回太多行,就会被错误地书写。您可以更深入地钻研如何写查询,即在查询开始处加上 EXPLAIN,它会返回查询计划,而非结果集,如清单 2 所示。清单 2. MySQL EXPLAIN 结果mysql> explain select * from accounts inner join leads on accounts.id = leads.account_id; +----+-------------+----------+--------+--------------------------+---------+--- | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+----------+--------+--------------------------+---------+-------- | 1 | SIMPLE | leads | ALL | idx_leads_acct_del | NULL | NULL | NULL | 200 | | | 1 | SIMPLE | accounts | eq_ref | PRIMARY,idx_accnt_id_del | PRIMARY | 108 | sugarcrm.leads.account_id | 1 | | +----+-------------+----------+--------+--------------------------+---------+--------- 2 rows in set (0.00 sec)MySQL 手册更深入探究 EXPLAIN 输出的主题(参见 参考资料),但是我考虑的一项重要内容是 ‘type' 列为 ‘ALL' 的地方,因为这需要 MySQL 做一个全表扫描,且不需要键来执行查询。这些帮助您在添加索引时会大幅提高查询速度。有效缓存数据正如我们在上一节看到的,数据库往往容易成为您 web 应用程序性能的最大痛点。但是如果您要查询的数据不经常改变怎么办?在这种情况下,一个好的选择就是在本地存储这些结果,而非针对每个请求调用查询。我们之前探究的两个操作码缓存 APC 和 Wincache 具有实现上述操作的工具,其中您可以将 PHP 数据直接存储到一个共享内存段中,便于快速查询。清单 3 提供了具体示例。清单 3. 使用 APC 缓存数据库结果的示例<?php function getListOfUsers() { $list = apc_fetch('getListOfUsers'); if ( empty($list) ) { $conn = new PDO('mysql:dbname=testdb;host=127.0.0.1', 'dbuser', 'dbpass'); $sql = 'SELECT id, name FROM users ORDER BY name'; foreach ($conn->query($sql) as $row) { $list[] = $row; } apc_store('getListOfUsers',$list); } return $list; }我们仅需一次执行查询。之后,我们将结果推送到 getListOfUsers 键下的 APC 缓存中。从这里开始,直到缓存到期,您就能够直接从缓存中获取结果数组,跳过 SQL 查询。APC 和 Wincache 并非一个用户缓存的惟一选择;memcache 和 Redis 是不需要您在与 Web 服务器相同的服务器上运行用户缓存的其他流行选择。这就提高了性能和灵活性,特别是当您的 web 应用程序跨多个 Web 服务器向外扩展时。在本文中,我们探究了调优您的 LAMP 性能的 5 种简单方法。我们不仅通过利用一个操作码缓存和优化 PHP 配置探究了 PHP 级别的技术,而且探究了如何优化您的数据库设计来实现合理的索引编制。我们还探讨了如何利用一个用户缓存(以 APC 为例)来展示如何在数据不经常改变时避免重复的数据库调用。参考资料学习“PHP V5 迁移指南”:了解如何将在 PHP V4 中开发的代码迁移到 V5。Planet PHP 是 PHP 开发社区新闻来源。MySQL 手册 更深入探究 EXPLAIN 输出的主题。PHP.net 是面向 PHP 开发人员的中央资源。查看 “推荐 PHP 读物列表”。浏览 developerWorks 上的所有 PHP 内容。通过查阅 IBM developerWorks 的 PHP 项目资源,扩展您的 PHP 技能。要收听面向软件开发人员的有趣访谈和讨论,请查看 developerWorks 播客。要将数据库与 PHP 结合使用吗?请查看 Zend Core for IBM,它是一个开箱即用的无缝 PHP 开发和生产环境,易于安装并且支持 IBM DB2 V9。查阅最近将在全球举办的面向 IBM 开放源码开发人员的研讨会、交易展览、网络广播和其他 活动。随时关注 developerWorks 技术活动和网络广播。访问 developerWorks Open source 专区获得丰富的 how-to 信息、工具和项目更新以及最受欢迎的文章和教程,帮助您用开放源码技术进行开发,并将它们与 IBM 产品结合使用。查看免费的 developerWorks 演示中心,观看并了解 IBM 及开源技术和产品功能。获得产品和技术替代 PHP 缓存 大概是 PHP 最流行的操作码缓存。Wincache 是主要由 Microsoft 的 IIS 团队开发的一个操作码缓存,仅供在使用 IIS (Internet Information Services) Web 服务器的 Windows 上使用。eAccelerator 是原始 PHP 缓存之一 Turck MMCache 操作码缓存的一个派生。使用 IBM 产品评估试用版软件 改进您的下一个开发项目,这些软件可以通过下载获得。下载 IBM 产品评估试用版软件 或 IBM SOA Sandbox for People,并开始使用来自 DB2®、Lotus®、Rational®、Tivoli® 和 WebSphere® 的应用程序开发工具和中间件产品。讨论欢迎加入 developerWorks 中文社区。参与 developerWorks PHP 论坛:使用 IBM Information Management 产品(DB2,IDS)开发 PHP 应用程序。关于作者John Mertic 是 SugarCRM 公司的一位软件工程师,拥有数年 PHP Web 应用程序经验。在 SugarCRM,他专攻数据集成、移动和用户界面架构。作为一位热心的作者,他已在 php|architect、IBM developerWorks 和 Apple Developer Connector 中发表了多篇文章,他还是 “The Definitive Guide to SugarCRM: Better Business Applications” 一书的作者。他曾经为很多开源项目做出过贡献,最著名的是 PHP 项目;在该项目中,他是 PHP Windows Installer 的创建者和维护者。
-
PHP学习大纲 PHP学习大纲知识面最广,讲解最深的经典PHP教程,韩顺平等多位名师联合创作!!!视频下载地址: http://php.itcast.cn第一阶段: PHP前端网页开发基础(1)HTML基础与加强HTML语言,HTML语言背景知识,HTML全局标签,HTML格式标签,HTML文件标签,HTML超链接标签,HTML图像标签,HTML框架标签,HTML客户端图像地图,HTML表格标签,HTML帧标签,HTML表单标签,HTML头元素,HTML分区标签(2)XHTML基础与加强XHTML与 HTML的差异,XHTML语法,XHTML DTD,XHTML验证,XHTML模块,XHTML属性,XHTML事件,XTHML结构化(3)HTML5设计与应用HTML5介绍,HTML5多媒体处理,HTML5画布,HTML5 Web存储技术,HTML5表单,HTML5 属性和事件HTML5的常用标签(比如:applet标签、article标签、aside标签、audio标签、canvas标签、datalist标签、details标签等)(4)CSS基础与加强CSS 简介,CSS基础语法,CSS 派生选择器,id 选择器,CSS类选择器,CSS盒子模型CSS背景 、文本 、字体 、边框 、外边距 、内边距 、列表 、表格CSS 高级: CSS 尺寸、分类 、定位 、伪类 、伪元素 、媒介类型(5)DIV+CSS设计与应用使用知名网站的首页深入剖析DIV+CSS的WEB标准:盒子模型经典案例-优酷首页面、仿sohu首页面布局、可爱屋网站首页面。涉及知识点包括: (CSS定位的四种方式、左浮动、右浮动、清除浮动、标准流和非标准流、设置对象的层叠顺序、块元素和行元素的转换等)(6)Javascript基础语法:Javascript基本介绍、Javascript的发展史、Javascript运行原理剖析、Javascript特点、Javascript的标识符、Javascript基本数据类型(数值类型、布尔类型、字符串类型)、Javascript复合数据类型简介(数组、对象)、Javascript特殊数据类型(NULL、undefine)、定义变量、初始化、赋值、数据类型转换的两种方式(自动转换、强制转换)、Javascript的运算符(算术运算符、关系运算符、逻辑运算符)、Javascript的位运算和移位运算(7)Javascript三大流程控制顺序控制、分支控制(单分支: if语句、双分支: if-else语句、多分支 if-else if-else 语句, switch-case-default语句)、循环控制(for语句、while语句、do-while语句)、在ie和firefox如何调式Javascript(8)Javascript函数函数基本概念、函数的定义、函数的调用方式及调用过程深度剖析、函数使用细节讨论、使用Function类创建函数、函数实际运用(打印金字塔、九九乘法表)、函数的递归调用、Javascript常用系统函数使用(encodeURI、decodeURI、eval、parseInt、parseFloat、isNaN等)(9)Javascript数组数组的基本使用、使用for/while遍历数组、数组实际运用(计算班级平均分)、二维数组的基本使用、使用for遍历二维数组、对二维数组转置处理、数组排序介绍、冒泡排序、顺序查找和二分查询法(10)事件驱动Javascript的Event-Driven机制、事件源、事件处理程序、事件名称、事件对象是什么、事件类型(鼠标事件、键盘事件、HTML事件、其它事件)、Javascript访问CSS技术、事件驱动的浏览器兼容性处理、常用的18个事件(onblur、onchange、onfocus、onkeydown、onmousedown等)综合案例(Javascript版计算器)(11)DOM编程DOM编程介绍(HTML DOM与XML DOM)、DOM编程实例入门、BOM介绍、DOM对象介绍、window对象详解、history对象详解、location对象详解、navigator对象详解、screen对象详解、event对象详解、document对象详解、body对象详解、style对象详解、WEB版坦克大战游戏、forms对象(集合)、from对象、images对象(集合) 、img对象、links对象(集合)、link对象、all对象(集合)、table对象详解、tableRow对象和tableCell对象、基于table对象的用户管理系统(12)WEB网站设计与应用商业级网页制作(企业邮箱网页、旅游网网页或呱呱网网页)这个阶段的视频教程: 参考 传智播客 轻松搞定网页设计(html+css+javascript) ,下载php.itcast.cn第二阶段 PHP核心编程(1)PHP基本语法加强Apache--directory配置段、一个IP和多个域名绑定的两种方式、HTTP协议入门介绍、Apache逻辑组件介绍、Apache生命周期、PHP运行之时序图、PHP数据类型加强、PHP各种运算符加强、PHP三大流程控制加强位运算(按位与、按位或、按位异或、按位非、位左移、位右移)、二进制(原码、反码、补码)、PHP版本在线贷款计算器(2)PHP函数PHP函数的基本介绍、如何自定义函数、PHP页面调用函数、require()、require_once()、include()和include_once()的区别、从内存分析PHP函数调用过程、函数使用需要注意的细节、函数值传递和引用传递的区别(3)数组、排序和查找数组的基本概念、数组的引用方式、数组引用陷阱、与PHP数组相关的函数(count、is_array、print_r、explode等)遍历数组的三种方式、删除数组元素和数组运算符、数组使用细节总结、内部排序法和外部排序法介绍、冒泡排序和快速排序、选择排序和插入排序、顺序查找和二分查找、二维数组介绍和使用(4)面向对象编程面向对象编程基本概念、类和对象的关系、如何定义类、成员属性(变量)、如何创建对象实例及如何访问对象属性对象在内存中存在的形式、栈、堆、全局区、常量区和代码区的关系、成员方法(函数)及使用细节构造方法(函数)、默认构造方法(函数)、this的基本概念和使用、析构方法(函数)、PHP的对象垃圾回收器、静态变量(类变量)的概念和使用、静态方法(类方法)的概念和使用、面向对象编程的三大特征介绍、面向对象编程-封装、面向对象编程-继承、面向对象编程-多态访问控制修饰符(public、protected、private)、方法重载(overload)、方法重写(override)方法重载(overload)和方法重写(override)的比较、PHP魔术函数(__set get __construct __destruct __call等 )和魔术常量(__LINE , FILE ,__FUNCTION__等 )、抽象类(abstract class)的概念和使用接口(interface)的概念和使用、接口编程和继承的区别、关键字final的使用、常量关键字const 的作用和使用注意事项、面向对象编程之强大的反射机制、面向对象编程之动态代理(5)错误处理和异常处理错误处理的基本概念、PHP处理错误的三种方式介绍、使用die()进程错误处理、自定义错误和错误触发器、错误日志、错误级别介绍、PHP异常处理的基本介绍、PHP异常处理(try throw catch)、自定义异常、如何设置顶级异常处理器、异常使用的规则(6)预定义超全局数组预定义超全局数组-基本概念、$_GET、$_POST、$_REQUEST、$_SERVER、$_ENV、$_FILES 、$_COOKIE、$_SESSION、$GLOBALS、$_GET 使用陷阱(sql注入和中文乱码问题)(7)cookie和session什么是会话、cookie的基本概念、cookie的curd操作、cookie重要的api介绍、cookie运行原理图解、cookie的实际运用(显示用户上次访问时间、显示用户上次浏览过的商品、)、cookie使用的注意事项、session数据存放的位置和形式、session的curd操作、session运行原理图解、session实际案例-在线购物车、IE禁用Cookie后的session处理方案、session防止用户非法入侵、session配合验证码使用、php.ini 中关于cookie和session配置说明(重点,难点)、自定义会话处理器、Session和Cookie的区别(8)PHP文件编程文件及文件编程是什么、文件流的基本概念、文件的操作方式、PHP文件编程函数汇总介绍、最常用的13个文件函数、使用文件完成网站计数器、文件上传下载操作-mini版音乐共享网、无限级文件扫描器(9)PHP绘图技术php绘图坐标系、绘图步骤说明、绘图快速入门、绘图最常用的函数、绘图技术的实际运用—人口分布饼状统计图、专业的报表开发--JpGraph、JpGraph的安装和配置、JpGraph实际应用-网民支持情况统计图、JpGraph中文乱码处理这个阶段的视频教程: 参考 传智播客 PHP从入门到精通1-149集 ,下载php.itcast.cn第三阶段:Mysql数据库编程&中级项目阶段(1)MySQL数据库什么是数据库、MySQL数据库的三层结构、MySQL数据库的安装和配置、数据库命令行的常见操作(启动、连接、操作、关闭等)、SQL语句分类(ddl/dml/dcl/dql/dtl)、创建、查看、删除、修改、备份和恢复数据库、如何创建表及MySQL数据类型详解、修改、删除表操作、如何对数据表进行CRUD操作、select语句中使用orderby、合计函数(count/sum/avg/max/min)、select语句中使用group by 和having子句、时间日期常用的10个函数、字符串相关11个函数、数学函数10个、流程控制函数3个、其它函数4个、MySQL中文乱码处理、PHP操作数据库实例、MySQL表类型和存储引擎(BDB/HEAP/ISAM/MERGE/MYISAM/InnoBDB)、如何选择表的存储引擎、事务的基本概念、事务和锁、事务提交和回滚操作、PHP程序中如何使用事务、事务隔离级别、表的主键和外键、多表联合查询和笛卡尔集、自连接、单行子查询和多行子查询、蠕虫复制创建海量表、合并查询(union , union all,intersect , minus)、表的内连接和外连接(左外连接、右外连接和完全外连接)、维护数据的完整性-约束(not null、unique, primary key,foreign key,和check )、商店售货系统表设计案例、索引(主键索引/唯一索引/全文索引/普通索引/复合索引)、索引优缺点分析、触发器和存储过程(2)数据库编程(mysql mysqli pdo)mysql扩展库简介、mysql扩展库操作mysql数据库程序、mysql_query()执行结果、释放资源和连接、对mysql数据库进行CRUD、mysqli扩展库简介、第一个mysqli扩展库程序、$mysqli->query()执行结果、mysqli对数据库进行CRUD操作、mysqli扩展库增强--批量执行sql语句、mysqli扩展库增强--事务控制、事务的acid、预处理 MySQLi_STMT、PDO的介绍和使用(3)中级项目在中级项目阶段,讲师将分组进行项目开发,讲师给出项目的需求和文档,各小组商量后选择,讲师会全程陪同,细致耐心的辅导同学们顺利完成项目.同时,传智播客也会适时的到 其它公司接项目,分组完成,并将学员的网站项目放到公网上展示,增强学员就业竞争力。 目前,可选的项目有: (我们还会根据市场需求增加新项目)BBS系统: 本系统为互联网用户提供互动和交流功能。网上在线支付: 本系统是为互联网客户提供在线支付功能,可立即应用于项目中及时雨供求信息共享网: 及时雨供求信息网主要用来为用户提供信息服务,对于生活和工作中的各类 信息都应尽可能地全部包括在内,例如,公寓、求职、招聘、培训、招商、房屋、车辆、出售、求购等信息。项目 发布后,要实现能够为用户生活、工作带来极大地方便并提高企业知名度、为企业产品宣传节约大量成本的目标。 及时雨供求信息网的主要目标是提供强大的搜索功能,准确的信息定位描红功能,付费信息的管理、免费信息的审 核和删除功能。oa无纸办公系统: oa无纸办公系统是针对中小型企业内部自动化办公管理的要求进行设计的,实现了 文件类信息的强大的管理能力;对员工基础信息(人事消息)的管理功能等;个人办公的信息自动化管理功能;发 布会议信息,并对会议信息进行管理;对系统用户进行管理;为了加强数据保密性,为每个用户组设置权限级别。大网电子商城: 本网站将电子商城给普通用户提供如下功能:购买商品、用户个人资料管理及订单查询 等功能。用户在未进行登录时,只可以查看商品的详细信息及公告信息,登录后可以执行购买商品操作、对商品进 行评论及管理个人资料。管理后台实现: 商品信息、商品类别信息、用户信息、订单信息、公告信息及评论信息进 行管理,用户可通过相应的功能按钮,进入相应的页面,对信息进行管理。这个阶段的视频教程: 参考 传智播客 PHP从入门到精通1-149集 ,下载php.itcast.cn第四阶段: PHP高级阶段(1)PHP的XML编程什么是XML及XML的常见应用、XML基础语法(文档声明、元素、属性、注释、CDATA区、特殊字符、处理指令(processing instruction))、XML约束概述、常用的约束技术(DTD和Schema)、DTD的快速入门、编程校验XML文档正确性、内部DTD和外部DTD介绍、DTD文档声明及引用、DTD各元素详解、DTD的修饰符说明、DTD属性详解、引用实体和参数实体、DTD综合案例(2)Smarty模板技术模板技术是什么和快速入门、模板引擎原理分析、php模板引擎smarty-基本配置、smarty-如何使用变量、smarty基本语法、变量操作符、组合修改器、smarty-数组操作、内建函数 、自定义函数、smarty-配置文件、smarty-常量使用、smarty-变量、smarty-方法、smarty高级特性-对象、smarty高级特性-过滤器(预过滤器 /后过滤器/输出滤镜)、smarty缓存的配置和使用(3)Javascript面向(基于)对象编程js面向对象特征介绍、类(原型对象)与对象、自定义类(原型对象)的五种方式(工厂方法、使用构造函数来定义类、使用prototype、构造函数及原 型混合方式、动态原型方式)、对象的属性、Javascript对象在内存中存在形式深度剖析、this关键字、成员函数、所有Javascript类的基类Object详解、闭包(closure)介绍、面向对象编程小游戏-超级马里奥(或是其它小游戏)、构造函数、遍历对象属性的方法(for..in)、删除对象属性(delete关键字)、js面向对象编程三大特征介绍、封装性介绍、Javascript面向对象访问权限(公开级别和私有级别)、使用原型法(关键字prototype)为所有对象添加公共方法、继承性介绍、Javascript继承实现方法(对象冒充和call及apply)、Javascript多重继承和基类Object、方法重载(overload)及覆盖(overrid)介绍、多态性介绍(4)正则表达式(RegExp)正则表达式(RegExp)是什么、什么是正则表达式对象(RegExp)及如何创建、RegExp对象的常用方法(exec和test)、string对象与正则表达式方法(match/replace/split/search)、RegExp对象的静态属性和实例属性、子表达式、捕获、反向引用详细说明、元字符详解、正则表达式应用案例(电子邮件、身份证、电话、城市、中英文个数、整数小数、url解析和结巴程序)(5)Ajax技术什么是Ajax、Ajax相关的七种技术(javascript、xml、css、xstl、dom 、xhtml和XMLHttpRequest)、Ajax基本原理和优势、Ajax典型的应用场景、Ajax经典案例1-无刷新验证用户名、不同的浏览器创建 XMLHttpRequest 对象的兼容性处理、Ajax模板代码(Get和Post)两种方式、Ajax处理服务器返回HTML格式的数据、Ajax处理服务器返回XML格式的数据、Ajax处理服务器返回Json格式的数据、html、xml和json 比较、Ajax经典案例2—省市联动、Ajax经典案例3—天气实时报告、Ajax经典案例4—多人无刷新聊天室(6)Jquery框架JQuery是什么、流行的JavaScript库、JQuery快速入门、什么是jQuery对象、Dom对象和JQuery对象的相互转换、JQuery选择器介绍、JQuery各种选择器详解、DOM 操作的分类(XML DOM/CSS DOM/HTML DOM)、查找节点、创建节点、内部插入节点、外部插入节点、删除节点、克隆节点、替换节点、对属性进行各种操作、对样式操作、设置和获取 HTML, 文本和值、常用的遍历节点方法、CSS-DOM操作、JQuery 加载并解析 XML、jQuery 中的事件 -- 加载 DOM、JQuery和Ajax整合(load、$.get()、$.post())(7)ThinkPHP框架什么是框架、框架的优缺点分析及为什么要选择框架、主流MVC框架介绍、ThinkPHP3.0特性介绍(单入口/CBD/AOP)、MVC模式、TP执行流程深入分析、URL调度模式、module功能及源码剖析、model详解、ORM与AR方式的区别、实例化模型的执行流程、连贯操作、自动验证及字段映射、模板标签及逻辑控制、模板中的循环结构、变量调节器、模板包含与布局、TP缓存应用、模板常量替换、扩展标签库、自定义标签库、TP应用ajax、多语言处理和面向切面简介、导入机制和配置文件加载流程介绍(8)Linux操作系统(LAMP环境搭建)Linux的初步介绍、安装虚拟机和Linux系统、初步使用Linux(登录/注销/关机/重启)、VI编辑器的使用、Linux目录结构介绍、Linux用户管理、Linux运行级别、Linux常用命令(init/pwd/cd/mkdir/rmdir/rm/man/touch/cp/mv/ln/more/less/grep/管道命令/find/重定向命令ls)、文件所有者、所在组和其它组管理、文件和目录的权限管理、SSH介绍和使用、分区的概念、Linux分区及挂载和卸载(mount/umount)、磁盘管理命令(df/fdisk)、Linux下Shell(chsh)、history命令妙用、tcp/ip基础及原理、Linux网络环境配置三种方法(setup/ifconfig/修改配置文件ifcfg-eth0)、RPM包管理(安装/删除/升级)、samba服务器、设置任务调度命令crontab、监控网络状态信息(netstat/ping/traceroute)、进程的概念和管理(ps/top/kill/killall)、Linux启动过程分析、压缩和解压(zip/unzip/gzip/gunzip)、Linux下搭建LAMP开发环境(9)svn版本控制svn是什么、svn的运行原理、svn软件的下载安装及配置、svn的基本使用、svn的单仓库和多仓库、svn客户端tortoisesvn的基本功能介绍、svn用户权限管理和配置、svn做成一个服务(service)、svn批处理文件、svn与apache的整合、svn与zend studio的整合本章节视频,请从 php.itcast.cn 网站去下载.第五阶段: 大型门户网站核心优化技术(1)页面静态化明确几个重要概念(静态网址/动态网址/伪静态网址)、页面静态化基本概念、benchmarking tool使用、页面静态化的好处(速度快/seo/防sql注入)、php缓存机制完成页面静态化、页面静态化-真静态、数据库和页面静态化(真静态)结合、页面静态化(真静态)的优点和缺点、伪静态的基本概念、PHP程序实现伪静态、rewrite规则介绍、使用.htaccess来控制网站目录访问权限、真静态 VS 伪静态及其如何选择(2)memcached缓存技术memcached基本概念、Memcached的作用、Memcached--运行原理图、Memcached-下载安装和基本操作、Telnet对Memcached进行CRUD操作、PHP程序对Memcached进行CRUD操作、Socket套接字对Memcached进行CRUD操作、Memcached机制深入了解、Memcached的生命周期、Memcached最佳实践、Session数据放入到Memcached、Memcached访问安全性讨论(Windows和 Linux)、什么样的数据适合放Memcached讨论、Memcached vs session的比较、Redis(Key/value型数据库)介绍、基于Memcached的在线词典(或其它小项目)(3)Mysql数据库优化数据库表设计的3NF、什么是反3NF、SQL语句优化的基本概念、show status命令了解各种SQL的执行频率、SQL语句优化-定位慢查询(slow-query-log)、SQL语句优化-explain分析问题、建立适当的索引、哪些列上适合添加索引和索引的优缺点分析、索引的类型介绍、索引使用陷阱、优化group by 语句、使用连接来替代子查询、选择合适的存储引擎(MyISAM和InnoDB)、选择合适的数据类型、对表进行水平划分、对表进行垂直划分、文件、图片等大文件用文件系统存储、数据库参数优化配置、合理的硬件资源和操作系统、MySQL数据库读写分离(4)Mongodb数据库NoSQL是Not Only SQL的缩写,它指的是非关系型的数据库,是以key-value形式存储,和传统的关系型数据库不一样,不一定遵循SQL标准、ACID属性、表结构等等,这类数据库主要有以下特点:非关系型的、分布式的、开源的、水平可扩展的NoSQL的主要产品是MongoDB(文档型存储) MongoDB 是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的,语法有点类似Javascript面向对象的查询语言,它是一个面向集合的,模式自由的文档型数据库。(5)sphinxSphinx是一个基于SQL的全文检索引擎,可以结合MySQL,PostgreSQL,XML等 做全文搜索。全文检索是大型Web必须提供的功能,但如果数据量非常大,传统的索引方式效率极低,所以需要建立全文索引服务器,并通过Sphinx行高速索引、 高速搜索及高可用性。它们可以提供比数据库本身更专业的搜索功能,使得应用程序更容易实现专业化的全文检索。本章节视频,请从 php.itcast.cn 网站去下载.第六阶段: 大型项目实战(提示:在不同的班级分别会讲下面的二个项目,一些老项目可能也会被新项目替换)(1)电子商务系统(基于shopex或基于ecshop)一款基于B2C网店系统,适合各类企业及个人快速构建个性化网上商店。使 用PHP语言及MYSQL数据库开发的程序,该项目在稳定性、安全性、负载能力有突出表现,同时使用到seo(搜索引擎 优化)、页面静态化技术及缓存技术(2)CMS内容管理系统(基于DEDECMS二次开发)织梦内容管理系统(DedeCms) 以简单、实用、开源而闻名,是国内最知名 的PHP开源网站管理系统,也是使用用户最多的PHP类CMS系统,在经历了二年多的发展,目前的版本无论在功能,还 是是易用性方面,都有了长足的发展,DedeCms免费版的主要目标用户锁定在个人站长,功能更专注于个人网站或中 小型门户的构建,当然也不乏有企业用户和学校等在使用本系统。织梦内容管理系统(DedeCms)基于PHP+MySQL的技 术架构,完全开源加上强大稳定的技术架构,使你无论是目前打算做个小型网站,还是想让网站在不断壮大后系仍 能得到随意扩充都有充分的保证。(3)SNS社会化网络系统(校内网)本系统是一个社交系统,可以联络你和你周围的朋友,了解他们的最新动 态;和朋友分享相片、音乐和电影;找到老同学,结识新朋友;用照片和日志记录生活,展示自我视频下载: php.itcast.cn第七阶段: 传智播客特色课程总结以往所学知识,介绍面试、沟通等个人发展所需的知识和技巧。
-
如何在静态方法中使用非静态变量 如何在静态方法中使用非静态变量关于静态方法和静态变量:1)static方法中不能直接使用非静态成员,因为非静态成员与实例相关,通过实例化间接使用2)static方法中不能用this(与实例相关)3)非static方法中可以使用static成员如何在静态方法中使用非静态变量?实例:<?php class abc{ public $count=8; function __construct(){ $this->count++; } static function getCount(){ $b=new abc(); return $b->count; } } $c=new abc(); $b=new abc(); echo $b->getCount(); ?>在静态方法getCount()中, 创建了一个新变量$b=new abc()初始化类,然后再使用类的非静态变量就可以了。