


关于负载均衡的一切:总结与思考
概述
古人云,不患寡而患不均。
在计算机的世界,这就是大家耳熟能详的 负载均衡(load balancing) ,所谓负载均衡,就是说如果一组计算机节点(或者一组进程)提供相同的(同质的)服务,那么对服务的请求就应该均匀的分摊到这些节点上。负载均衡的前提一定是“provide a single Internet service from multiple servers”, 这些提供服务的节点被称之为server farm、server pool或者backend servers。
这里的服务是广义的,可以是简单的计算,也可能是数据的读取或者存储。负载均衡也不是新事物,这种思想在多核CPU时代就有了,只不过在分布式系统中,负载均衡更是无处不在,这是分布式系统的天然特性决定的,分布式就是利用大量计算机节点完成单个计算机无法完成的计算、存储服务,既然有大量计算机节点,那么均衡的调度就非常重要。
负载均衡的意义在于,让所有节点以最小的代价、最好的状态对外提供服务,这样系统吞吐量最大,性能更高,对于用户而言请求的时间也更小。而且,负载均衡增强了系统的可靠性,最大化降低了单个节点过载、甚至crash的概率。不难想象,如果一个系统绝大部分请求都落在同一个节点上,那么这些请求响应时间都很慢,而且万一节点降级或者崩溃,那么所有请求又会转移到下一个节点,造成雪崩。
事实上,网上有很多文章介绍负载均衡的算法,大多都是大同小异。本文更多的是自己对这些算法的总结与思考。
一分钟了解负载均衡的一切
本章节的标题和内容都来自 一分钟了解负载均衡的一切 这一篇文章。当然,原文的标题是夸张了点,不过文中列出了在一个大型web网站中各层是如何用到负载均衡的,一目了然。

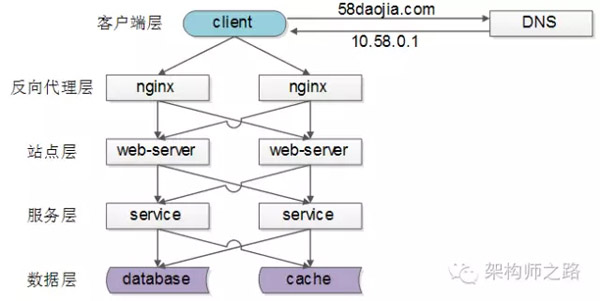
常见互联网分布式架构如上,分为客户端层、反向代理nginx层、站点层、服务层、数据层。可以看到,每一个下游都有多个上游调用,只需要做到,每一个上游都均匀访问每一个下游,就能实现“将请求/数据【均匀】分摊到多个操作单元上执行”。
(1)【客户端层】到【反向代理层】的负载均衡,是通过“DNS轮询”实现的
(2)【反向代理层】到【站点层】的负载均衡,是通过“nginx”实现的
(3)【站点层】到【服务层】的负载均衡,是通过“服务连接池”实现的
(4)【数据层】的负载均衡,要考虑“数据的均衡”与“请求的均衡”两个点,常见的方式有“按照范围水平切分”与“hash水平切分”。
数据层的负载均衡,在我之前的《带着问题学习分布式系统之数据分片》 中有详细介绍。
算法衡量
在我看来,当我们提到一个负载均衡算法,或者具体的应用场景时,应该考虑以下问题
第一,是否意识到不同节点的服务能力是不一样的,比如CPU、内存、网络、地理位置
第二,是否意识到节点的服务能力是动态变化的,高配的机器也有可能由于一些突发原因导致处理速度变得很慢
第三,是否考虑将同一个客户端,或者说同样的请求分发到同一个处理节点,这对于“有状态”的服务非常重要,比如session,比如分布式存储
第四,谁来负责负载均衡,即谁充当负载均衡器(load balancer),balancer本身是否会成为瓶颈
下面会结合具体的算法来考虑这些问题
负载均衡算法
轮询算法(round-robin)
思想很简单,就是提供同质服务的节点逐个对外提供服务,这样能做到绝对的均衡。Python示例代码如下
SERVER_LIST = [
'10.246.10.1',
'10.246.10.2',
'10.246.10.3',
]
def round_robin(server_lst, cur = [0]):
length = len(server_lst)
ret = server_lst[cur[0] % length]
cur[0] = (cur[0] + 1) % length
return ret可以看到,所有的节点都是以同样的概率提供服务,即没有考虑到节点的差异,也许同样数目的请求,高配的机器CPU才20%,低配的机器CPU已经80%了
加权轮询算法(weight round-robin)
加权轮训算法就是在轮训算法的基础上,考虑到机器的差异性,分配给机器不同的权重,能者多劳。注意,这个权重的分配依赖于请求的类型,比如计算密集型,那就考虑CPU、内存;如果是IO密集型,那就考虑磁盘性能。Python示例代码如下
WEIGHT_SERVER_LIST = {
'10.246.10.1': 1,
'10.246.10.2': 3,
'10.246.10.3': 2,
}
def weight_round_robin(servers, cur = [0]):
weighted_list = []
for k, v in servers.iteritems():
weighted_list.extend([k] * v)
length = len(weighted_list)
ret = weighted_list[cur[0] % length]
cur[0] = (cur[0] + 1) % length
return ret随机算法(random)
这个就更好理解了,随机选择一个节点服务,按照概率,只要请求数量足够多,那么也能达到绝对均衡的效果。而且实现简单很多
def random_choose(server_lst):
import random
random.seed()
return random.choice(server_lst)加权随机算法(random)
如同加权轮训算法至于轮训算法一样,也是在随机的时候引入不同节点的权重,实现也很类似。
def weight_random_choose(servers):
import random
random.seed()
weighted_list = []
for k, v in servers.iteritems():
weighted_list.extend([k] * v)
return random.choice(weighted_list)当然,如果节点列表以及权重变化不大,那么也可以对所有节点归一化,然后按概率区间选择
def normalize_servers(servers):
normalized_servers = {}
total = sum(servers.values())
cur_sum = 0
for k, v in servers.iteritems():
normalized_servers[k] = 1.0 * (cur_sum + v) / total
cur_sum += v
return normalized_servers
def weight_random_choose_ex(normalized_servers):
import random, operator
random.seed()
rand = random.random()
for k, v in sorted(normalized_servers.iteritems(), key = operator.itemgetter(1)):
if v >= rand:
return k
else:
assert False, 'Error normalized_servers with rand %s ' % rand 哈希法(hash)
根据客户端的IP,或者请求的“Key”,计算出一个hash值,然后对节点数目取模。好处就是,同一个请求能够分配到同样的服务节点,这对于“有状态”的服务很有必要
def hash_choose(request_info, server_lst):
hashed_request_info = hash(request_info)
return server_lst[hashed_request_info % len(server_lst)]只要hash结果足够分散,也是能做到绝对均衡的。
一致性哈希
哈希算法的缺陷也很明显,当节点的数目发生变化的时候,请求会大概率分配到其他的节点,引发到一系列问题,比如sticky session。而且在某些情况,比如分布式存储,是绝对的不允许的。
为了解决这个哈希算法的问题,又引入了一致性哈希算法,简单来说,一个物理节点与多个虚拟节点映射,在hash的时候,使用虚拟节点数目而不是物理节点数目。当物理节点变化的时候,虚拟节点的数目无需变化,只涉及到虚拟节点的重新分配。而且,调整每个物理节点对应的虚拟节点数目,也就相当于每个物理节点有不同的权重
最少连接算法(least connection)
以上的诸多算法,要么没有考虑到节点间的差异(轮训、随机、哈希),要么节点间的权重是静态分配的(加权轮训、加权随机、一致性hash)。
考虑这么一种情况,某台机器出现故障,无法及时处理请求,但新的请求还是会以一定的概率源源不断的分配到这个节点,造成请求的积压。因此,根据节点的真实负载,动态地调整节点的权重就非常重要。当然,要获得接节点的真实负载也不是一概而论的事情,如何定义负载,负载的收集是否及时,这都是需要考虑的问题。
每个节点当前的连接数目是一个非常容易收集的指标,因此lease connection是最常被人提到的算法。也有一些侧重不同或者更复杂、更客观的指标,比如最小响应时间(least response time)、最小活跃数(least active)等等。
一点思考
有状态的请求
首先来看看“算法衡量”中提到的第三个问题:同一个请求是否分发到同样的服务节点,同一个请求指的是同一个用户或者同样的唯一标示。什么时候同一请求最好(必须)分发到同样的服务节点呢?那就是有状态 -- 请求依赖某些存在于内存或者磁盘的数据,比如web请求的session,比如分布式存储。怎么实现呢,有以下几种办法:
(1)请求分发的时候,保证同一个请求分发到同样的服务节点。
这个依赖于负载均衡算法,比如简单的轮训,随机肯定是不行的,哈希法在节点增删的时候也会失效。可行的是一致性hash,以及分布式存储中的按范围分段(即记录哪些请求由哪个服务节点提供服务),代价是需要在load balancer中维护额外的数据。
(2)状态数据在backend servers之间共享
保证同一个请求分发到同样的服务节点,这个只是手段,目的是请求能使用到对应的状态数据。如果状态数据能够在服务节点之间共享,那么也能达到这个目的。比如服务节点连接到共享数据库,或者内存数据库如memcached
(3)状态数据维护在客户端
这个在web请求中也有使用,即cookie,不过要考虑安全性,需要加密。
关于load balancer
接下来回答第四个问题:关于load balancer,其实就是说,在哪里做负载均衡,是客户端还是服务端,是请求的发起者还是请求的3。具体而言,要么是在客户端,根据服务节点的信息自行选择,然后将请求直接发送到选中的服务节点;要么是在服务节点集群之前放一个集中式代理(proxy),由代理负责请求求分发。不管哪一种,至少都需要知道当前的服务节点列表这一基础信息。
如果在客户端实现负载均衡,客户端首先得知道服务器列表,要么是静态配置,要么有简单接口查询,但backend server的详细负载信息,就不适用通过客户端来查询。因此,客户端的负载均衡算法要么是比较简单的,比如轮训(加权轮训)、随机(加权随机)、哈希这几种算法,只要每个客户端足够随机,按照大数定理,服务节点的负载也是均衡的。要在客户端使用较为复杂的算法,比如根据backend的实际负载,那么就需要去额外的负载均衡服务(external load balancing service)查询到这些信息,在grpc中,就是使用的这种办法

可以看到,load balancer与grpc server通信,获得grpc server的负载等具体详细,然后grpc client从load balancer获取这些信息,最终grpc client直连到被选择的grpc server。
而基于Proxy的方式是更为常见的,比如7层的Nginx,四层的F5、LVS,既有硬件路由,也有软件分发。集中式的特点在于方便控制,而且能容易实现一些更精密,更复杂的算法。但缺点也很明显,一来负载均衡器本身可能成为性能瓶颈;二来可能引入额外的延迟,请求一定先发到达负载均衡器,然后到达真正的服务节点。
load balance proxy对于请求的响应(response),要么不经过proxy(三角传输模式),如LVS;要么经过Proxy,如Nginx。下图是LVS示意图(来源见水印)

而如果response也是走load balancer proxy的话,那么整个服务过程对客户端而言就是完全透明的,也防止了客户端去尝试连接后台服务器,提供了一层安全保障!
值得注意的是,load balancer proxy不能成为单点故障(single point of failure),因此一般会设计为高可用的主从结构
# 其他
在这篇文章中提到,负载均衡是一种推模型,一定会选出一个服务节点,然后把请求推送过来。而换一种思路,使用消息队列,就变成了拉模型:空闲的服务节点主动去拉取请求进行处理,各个节点的负载自然也是均衡的。消息队列相比负载均衡好处在于,服务节点不会被大量请求冲垮,同时增加服务节点更加容易;缺点也很明显,请求不是事实处理的。
想到另外一个例子,比如在gunicorn这种pre-fork模型中,master(gunicorn 中Arbiter)会fork出指定数量的worker进程,worker进程在同样的端口上监听,谁先监听到网络连接请求,谁就提供服务,这也是worker进程之间的负载均衡。
评论 (0)